
If you want to know just how far the performance of an all-flash array can be pushed, you need look no further than the DSSD D5 array that, after years of development and mystery, is being launched by storage juggernaut EMC today. It is an extreme machine, and one that is going to find a home wherever the need for speed trumps everything, including cost.
There are a lot of different kinds of scale that we talk about here at The Next Platform, and the DSSD D5 flash array can be thought of as a device for doing scale in, rather than scale up or scale out.
Scaling compute or storage up means very tightly coupling together components to make a much more powerful single unit of capacity; in the case of servers, it means using SMP or NUMA clustering to create a single memory space for applications to run in. Storage arrays can similarly be clustered to present a bigger single footprint under a single storage operating system and management domain. With scale out, the capacity scales out horizontally rather than vertically, as the industry lingo goes, with elements of compute or storage more loosely coupled and that looseness masked by middleware software.
Scale in means adding a different kind of device to a system that, in the end, eliminates the need to scale up or scale out a compute or storage element. So, for example, adding PCI-Express flash cards to servers is what helped Apple and Facebook massively increase the performance of their relational databases, allowing them to process much higher I/O rates than was possible with disk-based systems back in 2010 when they first started doing this, and together the two spent hundreds of millions of dollars per year adding flash to their systems.
The problem with this approach – and one that DSSD is taking on directly – is that the flash is locked up inside of a server and is only useful for that particularly machine. It would be far better to have a centralized array of flash memory that looked more or less local to servers but which was actually external to the machines and also a shared resource, like a storage array network (SAN) is for traditional block storage.
A Flash Of Insight
It might be a coincidence that Oracle completed its acquisition of Sun Microsystems in early 2010, but it was not a coincidence that two former Sun storage experts and one of the company’s legendary founders chose that year to start DSSD.
By then, the rise of flash inside servers and storage arrays was a foregone conclusion, and Bill Moore, who was the chief storage engineer at Sun, and Jeff Bonwick, one of the key engineers who with Moore created the Zettabyte File System (ZFS) at Sun, were looking for the next big thing in storage.
They approached Andy Bechtolsheim, the key systems techie behind Sun’s founding back in 1985 and a serial entrepreneur who has launched many successful systems and networking companies in his illustrious career, to be DSSD’s chairman. The trio worked on the DSSD array design for four years, and in May 2014, EMC shelled out an undisclosed sum to acquire DSSD before its products went to market. As we have previously reported, DSSD arrays are a key component of the “Wrangler” system at the Texas Advanced Computing Center at the University of Texas, accelerating Hadoop analytics and PostgreSQL database workloads.

In effect, although EMC will not say it this way, the DSSD design creates what amounts to a rack-scale storage area network for very high speed flash storage. Rather than use relatively slow Fibre Channel protocols (or even 100 Gb/sec InfiniBand or Ethernet) to lash the flash to the servers, DSSD’s engineers have taken NVM-Express, which accelerates the performance of flash devices linked to PCI-Express buses inside of systems, and extended that outside of the server’s metal skins with embedded PCI-Express switching inside of the D5 array. All of the flash is accessible to all of the servers that are linked to the DSSD D5 array, and none of the capacity or I/O is stranded. (It is however partitioned, and we will get into that in a minute.)
“DSSD is really focused on data intensive, analytical workloads,” Matt McDonough, senior director of marketing for the DSSD line, tells The Next Platform. “With the growth in data, especially hot data, as well in the growth in the number of connected devices and sources of data, applications are changing the requirements around infrastructure. If you look at a traditional architecture, you have a relational database and it is all about asset correctness and resilience and you have a deeper storage hierarchy, and your working dataset often fits into main memory, so you able to handle ERP and other requirements. But with the new applications, it is a mix of structured and unstructured data and there is no defined working set size, and you need to move from batch to real time.”
One way to try to speed this up is to do what Facebook and Apple did, as we pointed out above, and that is to put flash storage inside of servers. But there are some issues with this approach, and ones that the hyperscalers have had to create complex data management code themselves to cope with. The flash ends up being hostage to its server, and the I/O and storage capacity inherent in the flash ends up being stranded in the machines. Moreover, data is constantly shuffling between server nodes in a cluster as applications require it, the flash capacity is limited in each machine, and enterprise features such as snapshotting, compression, de-duplication, and other things are missing.
The other thing enterprises can do to goose their analytics workloads is to buy hybrid disk-flash or all-flash storage arrays, which brings a wealth of those enterprise storage features to flash, but the network latencies are relatively high and the I/O bottlenecks can be problematic for high-speed analytics jobs.
The DSSD D5 flash array takes inspiration from both sides, providing a shared flash array that offers much higher capacity than is available on in-server flash modules while at the same time making it look like that array’s capacity is local inside the server when it is not.
The Feeds And Speeds
While EMC is launching DSSD arrays today, the company continues to be secretive about the precise components inside the system. But McDonough gave us the basics.
The DSSD D5 array comes in a 5U rack-mounted chassis that has two Xeon-based storage controllers that operate in an active-active cluster sharing work. (The early, pre-production D5 units, like those that were part of the initial Wrangler system at TACC, had only one controller per chassis.) The flash modules in the D5 are based on enterprise-class multi-level cell (MLC) NAND flash memory, which McDonough says DSSD is getting from a number of different suppliers without naming names. DSSD is making modules with 2 TB or 4 TB capacities, and a fully loaded system with 36 of the 4 TB modules has a total of 18,000 flash chips. (The 2 TB flash modules are half populated with NAND dies.) The dual controllers in the D5 array hook into the flash modules through a pair of redundant PCI-Express switch fabrics (the vendor of the chips that implement these fabrics was not disclosed, but it is probably the PLX unit of Avago Technologies).
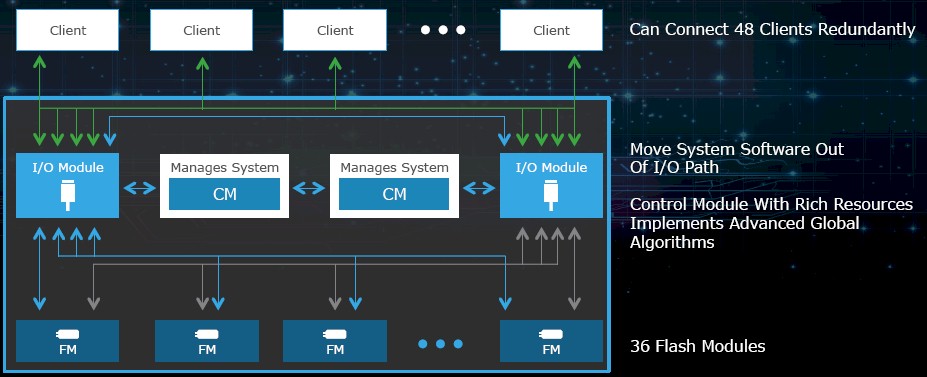
The important thing is that the control plane created by these Xeon motors is not in the datapath between the servers and the flash, and servers can link directly to the flash over the PCI-Express switching infrastructure using the NVM-Express protocol. This is one of the ways that DSSD is reducing the latency for data accesses on the D5. The wear leveling and garbage collection on the flash as data is added or deleted is done across the entire pool at the same time, not at a single module level, which is an innovation you cannot get if you try to build your own flashy servers.
The DSSD flash modules have two ports on them to link into this PCI-Express fabric, and stateless PCI-Express client cards that link the D5 to the servers also have two ports. The D5 has 48 of these two-port PCI-Express x4 links, which means that a single D5 can feed data to up to 48 server nodes. McDonough says that the PCI-Express mesh inside of the D5 array is the largest such one in the world, and it provides up to 8 GB/sec of throughput to each flash module. The D5 chassis is providing 100 GB/sec of bandwidth end-to-end across the servers and modules over that PCI-Express switch fabric embedded in the device.

A fully loaded D5 array can deliver 10 million I/O operations per second with an average latency of 100 microseconds, and that low latency is accomplished, as the chart above shows, by chopping out anything that is extraneous between the application and the flash module. Think of it as NVM-Express on steroids, or with a whole lot of other baggage removed from the datapath so NVM-Express can be even more nimble.
The D5 implements a single flash storage pool that all of the servers linking in can read or write data to, but then it is carved up into volumes that are where objects are housed. The containers that the DSSD operating system implements to create volumes can support block and key/value data types. Each server client card is given access to one or more volumes, which are sharable, but in the initial release of the software, applications have to provide locking mechanisms that keep two different machines from writing data to the same volume at the same time. But this locking mechanism is something EMC is looking to add over time, and is looking at the best approach to do this.
The DSSD D5 does not have de-duplication or data compression to try to maximize the effective capacity of the shared array. This machine, says McDonough, is all about maximizing performance and anything that might get in the data path like these features is not added, and very likely will not be added, either. The D5 has a block driver that allows for parallel file systems like GPFS or Lustre to run on top of the flash modules (and indeed, TACC is running GPFS on several D5 arrays that are part of Wrangler); this block device driver also allows for database management systems to be run atop it, too. The idea is to lay this software down on the D5 and not have to make any modifications to the applications for them to run.
While the D5 is aimed at database and analytics workloads that require low and deterministic latency and high bandwidth, it is not aimed at particularly huge data sets. The base D5 comes half populated with 2 TB flash modules and has 36 TB of capacity, while the top-end configuration has the full complement of flash modules and weighs in at 144 TB. DSSD has come up with its own multidimensional RAID data protection scheme, called Cubic RAID, that knocks the usable capacity down to 100 TB on the biggest configuration.
The point is, the D5 flash array is not aimed at customers who need to wrestle with petabytes or exabytes of storage, but it is designed for organizations that do not want to spend a lot of time tuning their Hadoop clusters, databases, or data warehouses. This is for people who want to throw hardware – and money – at the problem, and their data sets fit into 100 TB of capacity and will do no more than double every year.
In one test case at an electronics manufacturing running a portion of its EDA workflow for chip design, the tapeouts of chips was accelerated using DSSD arrays by a factor of 5X to 10X. In a parallel Oracle database workload at another early tester, a four-node Oracle RAC cluster backed by the D5 array was three times faster and had one third the cost of an Oracle Exadata cluster. On Hadoop tests, it takes one third of the storage to support Hadoop and queries on the system ran 10X faster than on a regular server cluster. EMC expects for the DSSD arrays to be adopted for fraud detection, risk analysis, predictive modeling, financial transaction modeling, product design, oil and gas reservoir modeling, and various life sciences applications.
So how much money is this performance going to cost? McDonough says that an entry D5 flash array with 36 TB of capacity will cost around $1 million, while a fully loaded box with 144 TB will cost under $3 million. That is a lot of money for capacity – something south of $30,000 per usable terabyte, which is a few times more expensive than a high-end PCI-Express flash card. But the D5 array also packs a lot of IOPS, remember, and the volumes allowed on the D5 array will be many times larger than what a single flash card tucked inside of a server holds.
EMC is focusing the DSSD sales pitch on the latency and the IOPS.
“From a dollars per IOPS perspective, we believe that we will be in the range of five to ten times better than what is out there on the market today,” boasts McDonough. “This is how we position ourselves. If you need the best IOPS per dollar, you are going to get that with DSSD.” To be precise, EMC thinks DSSD will offer 5X lower latency and 10X higher IOPS than other all-flash arrays, and do so at around 70 percent lower TCO on a per-IOPS basis.
The DSSD D5 will start shipping in March.

Hyperscalers Start Taking Pure Storage Flash For A Spin
Usually, innovation starts with the hyperscalers, HPC centers, and cloud builders of the world and spreads to the enterprise. But every once in a while, a technology establishes itself in large enterprises and the migrates upwards. This may be finally happening to Pure Storage, which was founded in 2009 and …

Can Anyone Make Money From Modern Storage?
In the past three decades, there has been no shortage of companies with interesting ideas to solve very specific data storage and retrieval problems associated with high performance computing in some form or another. Many of them raised tons of money, and most of them got eaten by platform incumbents …
The Vast Potential For Storage In A Compute Crazed AI World
When it comes to funding rounds for high tech companies, the alphabet usually runs out somewhere around Series E. If you haven’t figured out who you are by then – or the market hasn’t – that probably means the you are going to be one of the 80 percent or …
What is “libflood” mentioned in the diagram? Is this a library to access key/value volumes directly from userspace, rather than going via the OS block layer to a block volume?
That is what it looked like to me. But they did not explain it.
Hi Bill, yes you are correct – there’s a new whitepaper that was published today that goes into more detail on the software side of the DSSD architecture: https://www.emc.com/collateral/white-papers/h14907-wp-dssd-d5-software-aspects.pdf — disclaimer, I work for EMC.