
While innovators in the HPC and hyperscale arenas usually have the talent and often have the desire to get into the code for the tools that they use to create their infrastructure, most enterprises want their software with a bit more fit and finish, and if they can get it so it is easy to operate and yet still in some ways open, they are willing to pay a decent amount of cash to get commercial-grade support.
OpenStack has pretty much vanquished Eucalyptus, CloudStack, and a few other open source alternatives from the corporate datacenter, and it is giving VMware’s vCloud/vRealize a run for the money and has even compelled VMware to launch its own OpenStack distribution, VMware Integrated OpenStack. When Microsoft brings its Azure Stack out at the end of this year for building private clouds based on Windows Server and tools ported over from its Azure public cloud, OpenStack will be the main competition Azure Stack will face.
While there is no question that OpenStack is growing in popularity and is increasingly being used in production settings to orchestrate compute, network, and storage for virtualized servers and sometimes for bare metal and containers, one of the big gripes about OpenStack is that it takes a team of experts to stand up the software and maintain it. OpenStack has come a long way in terms of usability in the past several years, and the project contributors have been more concerned with this than with scalability or feature additions with the most recent releases. For instance, with the “Mitaka” release that came out last month, the big news is that the core features of OpenStack now have the same command line interface. But for some companies, these steps are not bold enough. They want something that turns OpenStack into something more like an appliance and that is as easy to use as VMware’s ESXi hypervisor and vSphere management tools were and is not anywhere near as complex as the vRealize (formerly vCloud) tools that turn virtualized servers into more malleable and automated cloudy infrastructure.
In essence, says Ariel Maislos, co-founder and CEO at Stratoscale, what companies want is the experience of Amazon Web Services in their own datacenters – or the closest approximation they can get since Amazon does not sell its stack for companies to literally buy. To that end, Stratoscale has spent more than three years building its own OpenStack variant, called Symphony, that wraps around OpenStack and simplifies it while at the same time running it atop homegrown hyperconverged block storage that runs on the same nodes as the virtualized server slices.
“The big challenge is that OpenStack is a technology, it is not a product,” Maislos tells The Next Platform. “It is a big promise, but the code is fundamentally broken. It has some nuggets of gold in it, and whatever we could take that worked, we took and in some areas we have done wholesale replacement. We think OpenStack today is about interoperability and APIs as opposed to taking the code and creating a distro from the open source with no value add.”
The Symphony stack runs on standard Xeon-based servers from the popular vendors, and unlike appliances sold for hyperconverged storage, it can run on popular machines. All that Symphony requires is a system with at least one “Sandy Bridge” Xeon E5 processor with at least six cores on it, 32 GB of main memory, one 256 GB flash drive, and at least two disk drives. Server nodes have to be linked by 10 Gb/sec or faster Ethernet links. A base Symphony cluster needs at least three nodes for data replication, which can be set at one, two, or three copies of the datasets that are replicated across the underlying homegrown distributed block storage that Stratoscale has invented. (This storage layer does not have a name, according to Maislos.)
The storage architecture for Symphony is similar to other hyperconverged storage, like that from Nutanix, which also created its own distributed file system from scratch and which runs within and underpins virtualized server instances originally deployed on VMware’s ESXi hypervisor and now supports its own Acropolis implementation of the KVM hypervisor. The Symphony storage layer currently only supports block storage (a requirement for VMs and for stateful applications like databases), and for object storage, the company currently recommends hooking in a Ceph array but is working on its own native object storage. (We are guessing that it will be a derivative of Ceph, but Maislos isn’t saying.) The company is also working on its own native file system to run across the hyperconverged storage, he adds. Existing block storage arrays used by datacenters can be plugged into the Symphony stack and accessed by the VMs on the machines.
This hyperconverged approach for Symphony is distinct from the way OpenStack is normally deployed, which has Cinder block storage and Ceph or Swift object storage deployed on distinct nodes in the cluster that are separate from Nova compute nodes. The control plane nodes for a regular OpenStack implementation are also separated. With Symphony, all nodes have all of the software and you just plug them in and they autoconfigure.
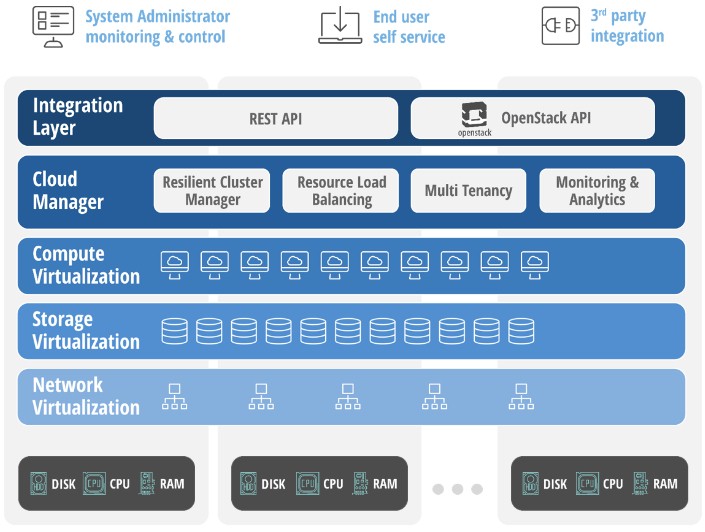
The virtualization layer in Symphony is a variant of the open source KVM hypervisor, which includes better implementations of live migration and load balancing than are available in the stock KVM, according to Maislos. The important thing is that Symphony does automatic VM placement across the cluster, rather than having admins pin particular VMs to specific machines, as companies are still doing out there. Stratoscale is using the Neutron feature of OpenStack to virtualize networking, but again, there are lots of tweaks to this feature to make it work with Symphony.
The overall Symphony stack is based on the “Kilo” OpenStack release, and Stratoscale will take a methodical approach to rolling out improvements from the “Liberty” release from October last year and the “Mitaka” release from last month. Stratoscale does its own releases every three months.
The Layer 2 networking in Symphony is based on VLANs, and that means that at the moment the scalability of Symphony is limited to 4,096 nodes. This is, by the way, a very large limit, and Maislos says that Stratoscale could have used the more recent VXLAN virtual networking layer (created by VMware and at the heart of its NSX virtual networking stack), but VXLAN is a relatively expensive feature in switches and customers wanted cheaper Ethernet switching for their clouds.
Thus far, Stratoscale has tested its code running on 200 nodes, and has 600 nodes it will eventually scale up to in its labs. The management domain in virtualized server clusters running VMware’s ESXi hypervisor peak at 32 or 64 nodes, depending on the ESXi release, and up to ten clusters can be federated under one management console. Symphony will literally scale across all the nodes as a single entity across hundreds of nodes and theoretically across thousands of nodes. But most companies will not want to put all of their application eggs in one cluster basket that goes too far beyond a few hundred nodes, we think. That has been our observation talking about other distributed computing platforms, with some outlier exceptions.
The Symphony mashup of OpenStack and hyperconverged storage became generally available back in October and had about a dozen beta testers kicking the tires before then. The WebEx division of Cisco Systems and CreditSuisse are early customers, which started putting the code into production back in January. The software cannot run on virtualized clouds such as AWS, Google Compute Engine, or Microsoft Azure, but it can run on IBM SoftLayer or Rackspace Hosting bare metal clouds.
For the moment, Stratoscale is mostly targeting the 500,000-strong installed base of VMware ESXi users, who probably have 50 million virtual machines by now. (The number was 45 million VMs back in February 2015, the last time we got a number from VMware on this.) The company has cooked up porting tools that can take ESXi virtual machines and convert them to the KVM format and automatically move them over to Symphony, which makes the sales pitch a bit easier. So is the relatively low price that Stratoscale is charging for Symphony, which is $5,000 per node, all-in. A stack of ESXi plus vSphere Enterprise Plus tools and the vCenter console plus vRealize cloud extensions and Virtual SAN hyperconverged storage would not be anywhere near as inexpensive. The vSphere Enterprise Plus edition of the hypervisor stack alone costs $4,229 per socket, and VSAN costs anywhere from $2,495 to $5,495 per socket, depending on the edition. vRealize cloud add-ons cost $6,750 to $9,950 per socket. Add up those elements, and Symphony is about one-fifth to one-eighth the cost per system. Whether or not this is equivalent technology is debatable.
Perhaps the better comparison would be to VMware Integrated OpenStack, or the Platform9 cloud controller, which mashes up OpenStack with VMware’s vSphere. VIO software is free to customers using vSphere Enterprise Plus, with an additional fee of $200 per socket for tech support. Platform9 costs $2,499 per server year, not including the ESXi hypervisor stack. So it looks like Stratoscale can undercut Platform9 by switching to KVM – something that Nutanix is also doing with its hyperconverged storage.
Stratoscale has over 100 employees, who work at the company headquarters in Herzliya, Israel as well as in Silicon Valley, New York, and Boston. The company has received $69 million in three rounds of funding, with Battery Ventures and Bessemer Venture Partners kicking in $10 million for the first round; Cisco, Intel, and SanDisk $32 million in the second round; and Qualcomm $27 million in the third round.

VMware And Kubernetes: More Than Just A Defensive Play
At first, VMware’s embrace of Kubernetes – several times in several different ways over several years – has a whiff of desperation about it. Kubernetes has been exploding in growth at the expense of the traditional virtualized applications that VMware has built its business upon. Kubernetes is nothing less than …
VMware Stretches ESXi To Be A Disaggregated Memory Hypervisor
We are strong believers in disaggregation and composability here at The Next Platform, and we think that eventually the tyranny of the physical confines and configurations of motherboard will be over. At some point in the future – probably not five years but maybe within ten – systems will be …

How Edge Is Different From Cloud – And Not
As the dominant supplier of commercial-grade open source infrastructure software, Red Hat sets the pace and it is not a surprise that IBM was willing to shell out an incredible $34 billion to acquire the company. It is no surprise, then, that Red Hat has its eyes on the edge, …
Be the first to comment