

It is amazing how fast open source Linux displaced open systems Unix from the HPC datacenters of the world.
This change, which started in the early 2000s, was not just about having a fully open source operating system, which stands in stark contrast to the closed source Unix variants with a common set of APIs that met the SPEC 1170 common API set. While those common APIs made application portability easier across different Unixes, this capability was nowhere near as friction free as having a single operating system span multiple processor architectures and interconnects.
Combined with the commodity pricing of X86 processors, it is no surprise that the supercomputing set very quickly switched from clusters of relatively few federated RISC/Unix NUMA systems to large numbers of commodity two-socket Xeon (and for a while Opteron) servers running Linux. Look at how fast the switch happened:
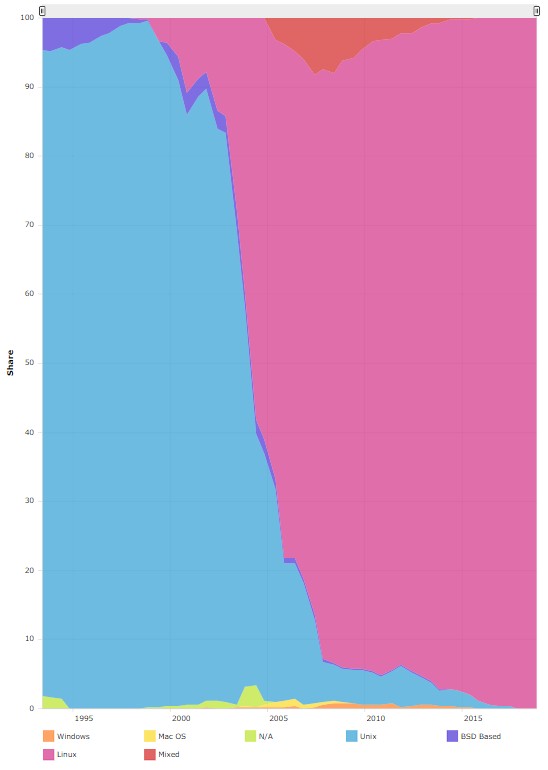
That is like overnight in the IT sector. It is important to remember that it was HPC that gave Linux legs in the datacenter first, as it should be, because the whole point of HPC is to push the envelope and point the way to the future. (The Unix wave hit there first, too.)
Linux was a foregone conclusion as the operating system of choice for the hyperscalers and cloud builders, for political as well as economic and cultural reasons. With the exception of Microsoft and the Windows Server operating system it uses as the substrate for the Azure cloud, all of the Magnificent Seven (Google, Amazon, Facebook, Alibaba, Tencent, Baidu) roll their own Linux and control their own stack, top to bottom. That absolute control is why open source (you have the code and can maintain it or fork it as you see fit) trumps open systems (you have a common API set but you can’t change anything) every time. Some of these titans give back a lot to the Linux community – Google especially – and others, well, not so much.
Saying that HPC clusters run Linux perhaps conveys the idea that they are all running the same Linux. For many years, they did not. There were many more Linux distributions back in the day and some HPC centers hacked together their own variants of Linux, with their own tweaks and tunings, to run better on clusters than the stock Linux distributions of the time could offer. SUSE Linux, once independent and then part of Novell and then Attachmate and then Micro Focus and then this year spun off for $2.5 billion to private equity group EQT, carved out a niche for itself by creating a distinct version of its Enterprise Server specifically for traditional HPC simulation and modeling workloads. For that reason, both Cray and SGI created their own HPC software stacks based on SLES, tuning up the operating system for their hardware, particularly for their homegrown interconnects.
While SUSE Linux carved out that niche, it is having trouble holding onto it with Red Hat and the HPC community working in concert to create variants of the RHEL aimed at HPC clusters. The three labs operated by the US Department of Energy that are part of the National Nuclear Security Administration – the so-called Tri-Labs consisting of Lawrence Livermore National Laboratory, Los Alamos National Laboratory, and Sandia National Laboratories – started its Tri-Lab Capacity Clusters (TLCC) effort back in 2007, and at that time part of the deal was to create the Tri-Lab Operating System Stack (TOSS) to run across these commodity machines, which are distinct from the capability-class iron that the labs also have. TOSS is based on RHEL. So is Scientific Linux, a RHEL variant tuned for HPC cooked up by Fermilab, CERN, DESY and by ETH Zurich in Europe. Three years ago, CERN moved to Red Hat Enterprise Linux proper, and Fermilab is spearheading the effort to keep Scientific Linux current. But in the long run, this effort might not be necessary. Atos/Bull has a variant of RHEL called Super Computer Suite.
If you look at the current Top500 supercomputer rankings from November, RHEL and its community support variant, CentOS, which was formerly independent but which has been controlled by Red Hat for the past four years, already dominate. There are 232 machines out of the 500 that just simply say they are running Linux without being specific. Some of these are homegrown Linuxes created by the hyperscalers, cloud builders, and telcos that run the Linpack benchmark test, but we reckon that a lot of them are just being imprecise. (Which is so uncharacteristic of the HPC crowd.) Of the remaining machines, 139 are running CentOS and another 24 are running RHEL proper, with another nine systems running the Tri-Labs TOSS, 17 are running Bull SCS, and three running Scientific Linux. There are 48 machines running the Cray Linux Environment variant of SLES and another 17 that are running the real SLES distribution. The rest are a smattering of Ubuntu Server and other Linux variants.
Today, the two most powerful supercomputers in the world – the “Summit” system at Oak Ridge National Laboratory and the ‘Sierra” system at Lawrence Livermore National Laboratory – are running RHEL 7, which has had a lot of work done on it by the labs and by IBM, Nvidia, and Mellanox Technologies in conjunction with Red Hat to tune up the operating system for the Power9 processors, the “Volta” Tesla GPU accelerators and their NVLink interconnect, and the 100 Gb/sec EDR InfiniBand adapters, respectively. The Post-K exascale system being built with a custom A64FX Arm processor from Fujitsu for the RIKEN lab in Japan will also run RHEL, but with the McKernel lightweight kernel instead of the stock Red Hat kernel.
How did Summit and Sierra end up running stock RHEL? It took years of development to make that happen, and now the rest of the HPC community will benefit from that effort.
“Both Summit and Sierra run on RHEL 7, and that is because of the tuning and optimization work we have done,” Ron Pacheco, director of product management for Enterprise Linux at Red Hat, tells The Next Platform. We did this for financial services and for manufacturing, and HPC is just a natural progression for us. From a kernel perspective, we did a lot of work around the memory and keeping the latency as low as possible. We did a lot of tuning for the network and I/O cards from Mellanox Technologies. These tunings were put into the upstream Linux kernel, which means the HPC community can work with us to do additional testing and hardening, in the same way that our team did around Summit and Sierra. That also spills over into the work we were doing with Nvidia around the NVLink interconnect. That is proprietary technology, but that did not inhibit us from working with Nvidia to help tune that unique communication path.”
The Nvidia drivers are closed source, but Nvidia worked with Red Hat and the Linux community upstream to provide interfaces to access the capabilities of the “Volta” Tesla GPU accelerators. Mellanox has similarly worked closely with Red Hat on the OFED drivers for its ConnectX adapters. Nvidia and Red Hat have worked closely on what Pacheco called heterogeneous memory management (what we would call unified memory) between the GPUs and CPUs. IBM, Nvidia, and Mellanox all contributed code to Linux alongside Red Hat to tune up those machines.
As the Top500 data cited above shows, it is hard for Red Hat to know just how many organizations are using RHEL (or CentOS) for their HPC, whether it is scientific simulation and modeling, financial modeling, data analytics, or whatever else we want to call high performance computing.
“It is difficult to tell because of the subscription model that we have and the fact that customers are allowed to move those subscriptions around machines and underneath workloads,” says Pacheco. “I have been here at Red Hat for 13 years, working with a lot of different customers, and many customers always had HPC grids that ran adjacent to but separate from what they were doing in production with core applications. Depending on the customers, there are an equal number of subscriptions on both sides to run the entire operation. Leaving that aside, we are nonetheless seeing tremendous growth in a number of areas, including traditional HPC, because the cost of the compute and networking has just dropped dramatically. For example, with the cost of GPUs coming down to almost reasonable levels, enterprises can now bring hybrid systems in-house, and that means data scientists can start working locally as opposed to going to specialized HPC centers. And with the public clouds making GPUs available, some companies are taking these workloads into the cloud.”
Red Hat has had free-to-paid conversion programs under way for the past decade, trying to move companies from the CentOS community supported version of its operating system to RHEL with proper subscriptions, and it is not clear how successful these have been. If memory serves, the CentOS base was about the same size as the RHEL base when these programs got started, with millions of servers running each, but we have no idea what the split looks like today or how much the base has grown. (It has probably almost doubled in that decade.)
The point is, HPC centers usually have plenty of Linux expertise and they tend to share information, so this is why the CentOS base is still pretty large in the Top500 data. But that doesn’t mean it will stay that way. If Red Hat got more aggressive about pricing in HPC and AI accounts and created its own full blown HPC stack like the Tri-Labs have done with TOSS and like Intel is trying to do with OpenHPC (somewhat half-heartedly as of late), and did a similar thing with AI stacks, it could move many HPC centers to paid support and still make a decent fee for the contracts even if it charges less than it does for standard RHEL contracts knowing how sensitive to price HPC centers are to anything that isn’t just raw compute.
To our way of thinking – and we do think in terms of platforms around this joint – Red Hat should have created a true and complete HPC stack a long time ago, and it should do so for AI frameworks, too. Enterprise customers are surely looking for this – something that doesn’t tie them to particular processors, storage, and networks, but supports them all. Red Hat has its own OpenStack cloud controller distribution, and it has created a Kubernetes container orchestration system atop OpenShift after evolving it from its original “gear” abstraction layer that predated Docker containers and runtimes. Red Hat has also shown little interest in rolling up database distributions (it dabbled a bit here and there many years back) or Lustre parallel file systems; IBM’s Spectrum Scale (GPFS) is closed source, so that is not even possible.
“We talked to Intel quite a bit about OpenHPC, and I think there are some things about it where we seem to be aligned but there are some things where we have some concerns because, as an open source company, these pieces are not as open as we want,” Pacheco explains. “But that doesn’t inhibit us from working with Intel. We are also members of the OpenHPC community, and Nvidia’s RAPIDS is another stack that we are interested in. We are hoping to work with anyone who is trying to get a stack out there, particularly if it is open source and we can land it on RHEL. We will partner with the community for these, we are not just going to do it independently because that kind of collaboration gets the best out of everybody.”
When pressed about why there isn’t a RHEL for HPC stack and a RHEL for AI stack, which are natural, low-level, software infrastructure for Red Hat to provide – and for a wide variety of processors and accelerators – this is what Pacheco had to say: “I certainly agree that there has to be a common base where people can innovate and then differentiate. We are looking at that. The machine learning frameworks are still undergoing rapid innovation, they are changing a lot. IBM, Intel, and Nvidia have stacks. Once we start to see stability in the frameworks and libraries, then we can look at how to integrate that into a Red Hat offering.”
Whether or not there are full-blown stacks, the cross-platform nature of RHEL is appealing to many customers, particularly enterprises that are doing infrastructure and data analytics as well as Web infrastructure on Linux.
“Fujitsu has some pretty significant HPC business in the Asia/Pacific region, so moving from Sparc and Solaris to Arm and RHEL is a big shift,” says Scott Herold, senior manager of multi-architecture for Enterprise Linux, meaning that he oversees enablement of the Power, Arm, and mainframe architectures that can also run RHEL. “The choice of architectures has opened up. Power has shifted from big endian to little endian, which makes it more compatible with X86 processors. Arm has dominance in mobile and is moving into the datacenter, and Marvell/Cavium and Ampere are delivering Arm processors that are on par with or exceeding the performance and price/performance of Xeons. This is just opening up opportunities, and my team is focused on making sure that any enablement that we do is the same across the architectures. Three years ago, our capabilities across Power and Arm would have been different from IBM mainframes and would have been different from X86. We realize that this is not a way to sustain business, especially if we have these segmented datacenters where some of the infrastructure is running HPC as well as other enterprise workloads. Enterprises want to simplify licensing and they don’t want to deal with multiple vendors. Now that we have provided that common platform, and can provide capabilities across all of these hardware architectures, it has put us in a significantly better position. Historically, that has been SUSE’s strength – they find areas where Red Hat had not focused or was not as strong as we could have been and they attacked those spaces. In the past few years, we have made giant strides to close those gaps, and we have seen the benefits of that work and they are starting to choose RHEL.”
In the end, HPC and AI tools may just become part of the Red Hat Linux distribution, but we think that IBM, once it acquires Red Hat, will probably have some say in how to attack the enterprise with both HPC and AI. IBM needs to quintuple the Red Hat revenue stream to pay for the $34 billion acquisition, and we expect it to grow the number of things that run on RHEL, just as it took the Apache Web server and transformed it into a business with so many moving parts it was hard to keep track of but which generated tens of billions of dollars in revenues over the past two decades. The enterprise mimicking HPC centers is where Big Blue will make the big bucks, and having a stack that can do hybrid cloud and containers is going to be a key to selling that stack, whatever it ultimately is called. It may just be called RHEL.


The Ever-Reddening Revenue Streams Of Big Blue
Speaking in generalities across any aspect of history is always risky, but that is what the job of history is. The first wave of open source software in the enterprise in the 1960s through the 1980s was largely academic, and it wasn’t until the second wave of open source hit …

Ceph Gets Fit And Finish For Enterprise Storage
Ceph, the open source object storage born from a doctoral dissertation in 2005, has been aimed principally at highly scalable workloads found in HPC environments and, later, with hyperscalers who did not want to create their own storage anymore. For years now, Ceph has given organizations object, block, and file-based …

OpenShifting The Hybrid Cloud Into High Gear
The cloud and the related edge already are rapidly influencing almost every aspect of IT, from the technology that is being adapted and created to how that technology is being consumed, as illustrated by the growing numbers of established hardware vendors – including Hewlett Packard Enterprise, Dell, and Cisco Systems …
Be the first to comment