
There is a battle heating up in the datacenter, and there are tens of billions of dollars at stake as chip makers chase the burgeoning market for engines that do machine learning inference.
Running inference on FPGAs, GPUs, DSPs, or customized ASICs is not a new thing. We have covered many of the different approaches in the past several years here on The Next Platform. But several years into the machine learning revolution, the world is bracing to do a lot more inference than training as machine learning gets embedded in all layers of applications. And, yes, while Intel can brag that 95 percent of inference is done on its Xeon CPUs today, there is a swarm of chips that are attacking like piranhas that want to keep Intel from getting any more of the inference market, much less ride this expanding market up, up, and away.
The pile of cash at stake is immense, according to FPGA maker Xilinx, which talked about the total addressable market for machine learning training, inference in the datacenter, and inference at the edge at the launch of the first of its “Everest” Versal FPGAs last week. We analyzed the numbers that Xilinx presented, and machine learning training looks like it is going to peak at around $6.5 billion by 2021 and stay steady, while by 2023 inference at both the edge and in the datacenter will drive 4.6X times as much semiconductor sales. So those who do inference well are going to do well.
We looked at the architecture of the Everest family of FPGAs from the event last week, and now we are going to do a deeper dive in the performance figures that Xilinx has provided on the initial devices and also take a look at the relative price/performance of these devices compared to other alternatives. Not all alternatives, mind you. There are something close to 90 startups that are designing machine learning chips in one form or another and a slew of CPUs on top of that, Nvidia pushing its Tesla P4 and now T4 GPU accelerators, and Google etching its own Tensor Processing Unit (TPU) chips for inference and soon a combination of inference and training on the same device.
With the Everest chips not yet coming to market, Xilinx is basing its first homegrown accelerator cards, dubbed Alveo, on its prior generation of UltraScale FPGAs, which are etched with the 16 nanometer processes from foundry partner Taiwan Semiconductor Manufacturing Corp. The future Everest FPGAs will be manufactured in 7 nanometer processes from TSMC, and the shrinking of the transistors is going to allow for 50 billion transistor devices in the middle of the Everest line; Xilinx is not saying how high the transistor count can go for the high-end Everest parts, but it has confirmed to us that they will go a lot higher. We shall see. We suspect that the Premium Series coming in 2020 will be considerably heftier than the AI Core Series (aimed at inference specifically) and Prime Series (aimed at network function and storage acceleration as well as inference) that Xilinx will deliver in the second half of 2019, and that the HBM series, which will marry a hefty Everest chip with High Bandwidth Memory when it comes out towards the end of 2020, will be a true beast. Think something that smells like a Volta GPU, but with malleable circuits.
While Xilinx was talking about the AI Core Series and Prime Series variants of the Everest chips at its launch event, the new Alveo line of accelerator cards, based on its Virtex UltraScale line and with parts that have features that lie between existing devices it has been selling. These Alveo cards are just to seed the market and set the stage for the Everest chips and to get FPGAs as broadly and widely deployed as possible, just like Nvidia had to do with Tesla GPU accelerators in the early days of commercialization after a few years of academics and hyperscalers playing around.
The Alveo U200 card has a Virtex UltraScale FPGA that has 892,000 look-up tables (LUTs) on the die, somewhere between the VU125 with 716,160 LUTs and the VU160 with 926,400 LUTs. The FPGA is a full height, three-quarter length, dual slot PCI-Express 3.0 x16 card that has 64 GB of DDR4 main memory latched to the FPGA, capable of 77 GB/sec of memory bandwidth into and out of the device. The FPGA is configured with 35 MB of on-chip SRAM, which can push 31 TB/sec of bandwidth, which is nearly 400X the bandwidth of the main memory. The Alveo U200 card has two 100 Gb/sec Ethernet ports for linking to the outside world and it burns 225 watts in either a passive or active card configuration. The device has a peak performance of 18.6 teraops chewing through INT8 data, which is a popular format for machine learning inference. This card has something else you normally don’t see for datacenter-class accelerators – a list price. It costs $8,995.
The fatter Alveo U250 card has the same basic form factor, but it weighs in at 1.341 million LUTs, which puts it somewhere between a VU190 and a VU440 in the regular Virtex UltraScale line. With the increase in logic comes an increase in SRAM capacity and bandwidth, in this case there is 54 MB of SRAM that has a combined 38 TB/sec of bandwidth. All of the other salient characteristics of the Alveo U250 are the same, but due to the increased performance, the price for a single unit runs to $12,995.
Volume discounts will, of course, be applied to larger orders.
What we want to know is how the Alveo line performs at inference work compared to alternatives, and also try to reckon how the future Everest-based Alveo accelerators will stack up to the current ones and the alternatives. Here is a summary chart that shows the performance of the Alveo U200 and U250 cards against a bunch of different options:
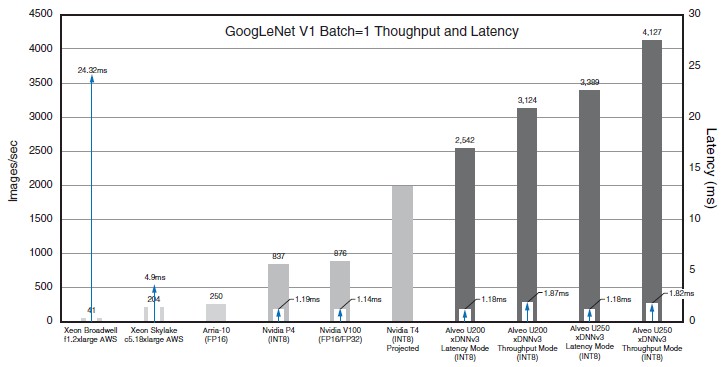
In this case, the benchmarks are for running the GoogLetNet V1 convolutional neural network framework, with a batch size of 1. (Meaning that items to be identified are sent through in serial fashion rather than batched up to be chewed on all at once.) This framework came close to beating humans at image recognition, but it took Microsoft’s ResNet in 2015 to accomplish this feat, with a 3.57 percent failure rate compared to humans at 5.1 percent.
The baseline for performance that Xilinx chose was the smallest F1 FPGA-accelerated instance on the EC2 compute cloud at Amazon Web Services. This instance has a single Virtex UltraScale+ VU9P FPGA on it, which has 1.182 million LUTs, which is attached to a server slice that has eight vCPUs (Based on the “Broadwell” Xeon E5-2696 v4 processor and 122 GB of main memory. (This is an eighth of the physical server at AWS, which has 64 vCPUs with 976 GB of memory plus eight of the UltraScale+ VU9P FPGAs in it.) That F1 f1.2xlarge instance was able to process 41 images/sec, but the latency was a pretty unimpressive 24.32 milliseconds. Moving to a c5.18xlarge instance on AWS based on the “Skylake” Xeon SP-8124 Platinum processor, which has a total of 72 vCPUs and 144 GB of memory, the performance was boosted to 204 images/sec, and latency dropped by about the same amount to a much better 4.9 milliseconds.
Xilinx dropped an Arria 10 FPGA in the mix, showing that it could process 250 images/sec, based on Intel’s own tests, which did not give latency figures. The Intel/Altera FPGA performance is a bit more complex than this, of course. Intel also has the Stratix 10 line, and both lines support mixed precision, which can increase throughput even if it does reduce accuracy a bit. Here is what Intel says the performance profile of the latest Arria and Stratix chips, compared to Nvidia’s prior Tesla P40 accelerators (which were aimed at beefier inference jobs), looks like running GoogLeNet for image recognition training and then running inference on the accelerators:
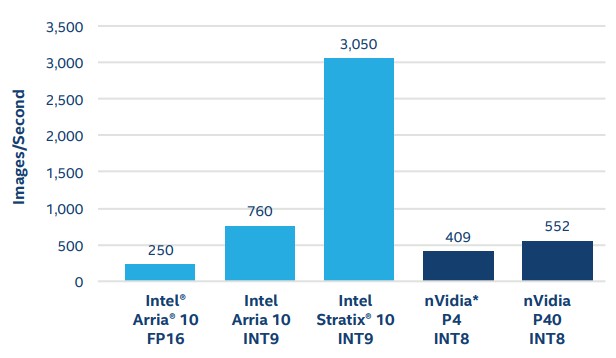
The data above comes from a performance white paper that Intel put out recently.
Dropping down to the INT9 format boosts performance on the Arria 10 by a factor of 3X, and the beefier Stratix 10 running in INT9 mode can do 3,050 images/sec, which is pretty good. It is interesting to us that this data was not added to the Xilinx chart. But remember, trying to drive lower latencies – something below 2 milliseconds – could drop these Intel FPGA numbers lower. We just don’t know from the data we have.
The Nvidia numbers in the chart put together by Xilinx above came from a performance report that Nvidia put out for doing inference on its GPUs. In that report, Google is cited as suggesting that 7 milliseconds is an acceptable turnaround time for an inference. So rather than pushing down to 2 milliseconds or less, Nvidia let the latency drift up and pushed more inferring through the GPUs. Here is a more complete set of data, however fuzzy:
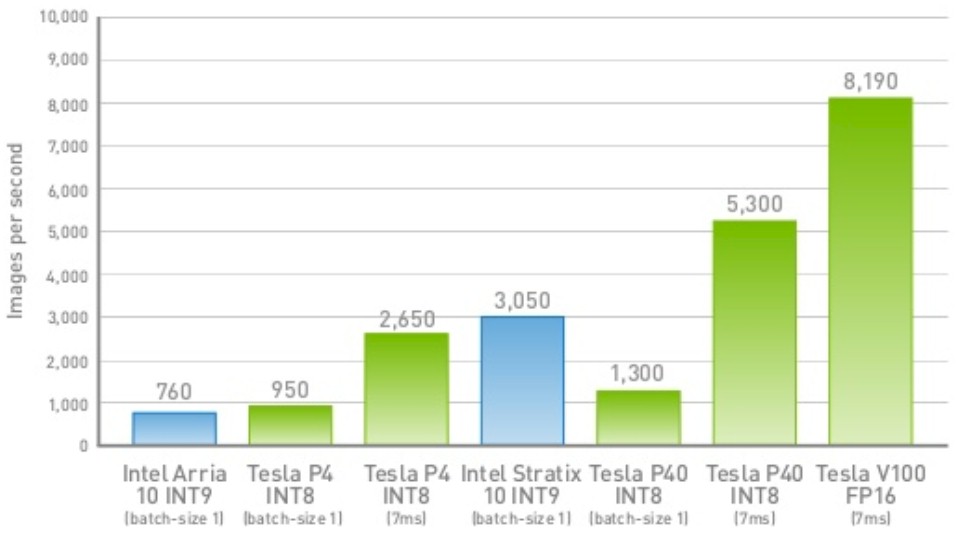
Xilinx, by the way, is positioning its accelerators as low latency devices, one of the key differentiations of the FPGA over other kinds of motors, and thinks that 2 milliseconds is a better level to shoot for. That is why it is citing Tesla P4 and Tesla V100 figures with low latency in the chart above as well as making projections for the new “Turing” Tesla T4 accelerator. The Tesla P4 was able to figure out 837 images/sec at a 1.19 millisecond latency, and the new Tesla T4 was projected to do 2,000 images/sec running GoogLeNet when this Xilinx report was put together. The Tesla V100 was using the mix of FP16 and FP32 processing used in the Tensor Core units, and it only delivered 876 images/sec at a latency of 1.14 milliseconds.
If you are getting a sense that we need properly audited machine learning benchmarks, complete with latency requirements, whether it is 7 milliseconds or 2 milliseconds for average response time, we agree with that sentiment.
Xilinx ran the GoogLeNet inference tests with the Virtex UltraScale FPGAs running in two different modes: one geared for low latency close to 1 millisecond and another for high throughput where the latency was closer to 2 milliseconds, and you can see that shifting the latency just that little bit upwards resulted in a 23 percent and 22 percent boost in throughput in the Alveo U200 and U250 accelerators, respectively. We suspect that drifting them up to 7 milliseconds would let the Xilinx accelerators push even more images through the FPGAs in a second to be categorized. It is hard to say for sure, but we would love to see such performance numbers for better comparison.
Xilinx did a better job in some ways in characterizing the performance of the forthcoming AI Core Series of the Everest chips, bracketing the performance based on inference workloads that are not latency sensitive (in batch mode) and for inferences that had to be done in 7 milliseconds or 2 milliseconds. But it did not provide the raw data behind these charts. We have done our best to tease the numbers back out again based on the chart above.
Here is what the comparisons look like for high batch mode inference on GoogLeNet:
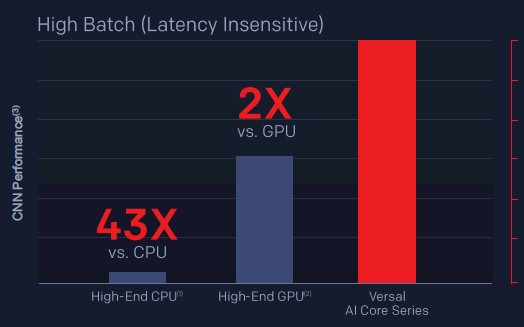
The high-end CPU instance shown is the same c5.18xlarge instance on AWS based on the “Skylake” Xeon SP-8124 Platinum processor shown in the first chart above, and the high-end GPU is the same Nvidia Tesla Volta GPU in that chart. So, based on this, the particular AI Core Series FPGA in the Everest family can process twice as many images/sec, but we have no idea how many these are or what Everest part this might be. And the comparison does not include either the Tesla P4 or T4 cards that are, in many ways, aimed at the same in-server datacenter inference workloads as the current and future Alveo cards.
Then, Xilinx crunched the latency down to below 7 milliseconds:
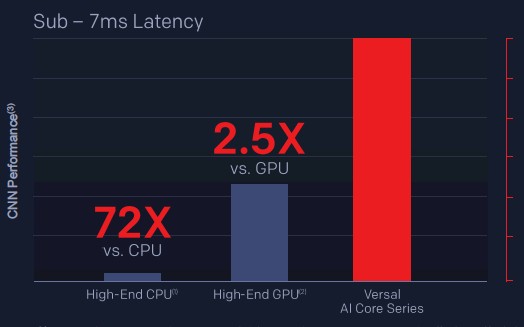
With the latencies down at or below 7 milliseconds, the gap really opens up between that AWS Skylake Xeon SP server instance and the Everest chip, and the gap opens up a tiny bit compared to the Tesla Volta GPU.
If you push the latency down to 2 milliseconds, the CPU system can’t even do the inference job, and the Everest FPGA now can do 8X the inference work, according to Xilinx:
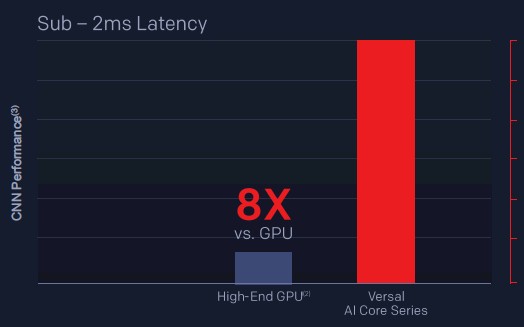
Xilinx gave another hint, saying that an AI Core Series FPGA with the same 75 watt performance envelope would be able to deliver sub-500 microsecond – not millisecond – performance on image inference using GoogLeNet and that the throughput would be better than the Tesla T4 by a factor of 4X, presumably at the same latency or the comparison does not make a lot of sense.
The following chart talks about the three different generations of GPUs running at sub-2 millisecond latency – that’s Tesla P4, V100, and projected T4 performance – compared to the current Alveo U250 card and the expected performance of the Everest AI Core Series FPGA on the same output from a trained model on GoogLeNet with a batch size of 1. Take a gander:
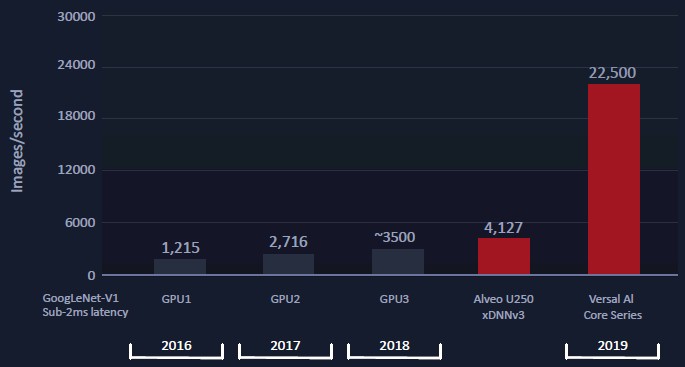
This is something that we can work with a bit, since the latencies are normalized and we can reckon prices a bit and we have wattages for the devices. But before we get into that, there is one more twist. Xilinx bought DeePhi Tech back in July, and Xilinx has every intention of using its pruning and quantization compression techniques in its Versal FPGAs to push the performance envelope on inference work even further. Like this:
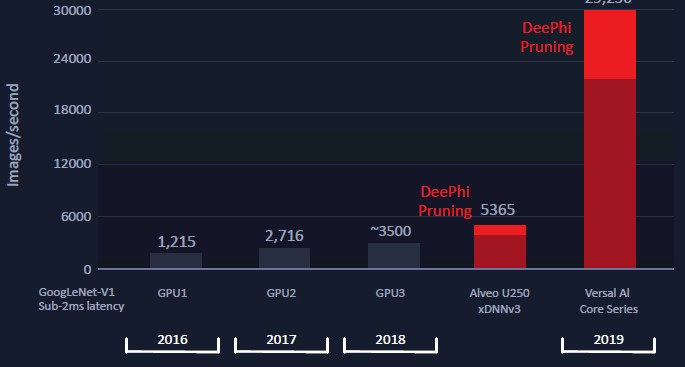
The DeePhi pruning and quantization techniques boost inference performance on the Alveo U250 and on the future card based on one of the AI Core Series FPGAs by 30 percent, which is a good reason to buy DeePhi and keep it out of the hands of the enemies.
To stack up the relative merits of various inference engines properly, the comparisons would show performance per watt, performance per dollar, and performance per dollar per watt for the CPUs, GPUs, and FPGAs compared and at the same latencies. A lot of the data that we have is incomplete to do this because the latencies are not held constant (or even known) for the chips that were tested. Vendor pricing is not even publicly available for many of these devices. All of this is a serious shortcoming and does not allow for proper comparisons to be made. The emerging MLPerf benchmark might help here, if it is done correctly.
We did the best we could with the data we have, which is exactly what customers have to do until real benchmarks – and audited ones at that – become available. In any event, here is the best we can reckon for the data shown in the chart above to do this:

We have had to estimate the price of the Tesla T4 accelerator, which we have been told would be similar to the price that Nvidia charges for the Tesla P4. These are our best estimates of list prices to end users – given supply and demand, the prices of GPU accelerators have fluctuated wildly and, in fact, have risen for even older GPUs in the Nvidia line, as we discussed back in March. We also reckon that Xilinx will want to charge a premium for Alveo cards based on the Everest FPGAs, but given the competition, the performance is probably going to rise a lot faster than the price does. (Unlike many things in the HPC space.) It is a guess. We will see.
In terms of performance per watt for the things you can buy today, the Tesla T4 wins and beats the Alveo U250 card pretty handily in this regard. And on price/performance, the gap is even wider, with the Alveo costing about four times as much per unit of work. Adding in the DeePhi pruning and quantization, the gap closes, but it is still three times as expensive. But look at what happens if you look at it in terms of dollars per performance per watt: It is almost a dead heat between the Tesla T4 and the Alveo U250 with the DeePhi goodies. And look at what happens next year if Xilinx holds the price a bit and just hammers home the performance on inference. Now Xilinx can close the price/performance gap and get better on the performance/watt vector, too, and then clean up by a factor of 5X to 6X on the price/performance/watt. Nvidia will have to react to this, obviously, and Intel is not just going to sit on the sidelines.
The cost per image inferred line in the table is just for your amusement and to remind you that for companies that are just doing some inference, the cost is vanishingly small. This takes the cost of the accelerator and runs it full out for three years doing images. If you need to do millions of images, that is really not much at all. But if you have to do billions or trillions, well, those costs are gonna really mount up. What applies to images applies equally well to any and all machine learning workloads and the data types they will be processing. Hence, all that wonderful competition for inference. Our point is, we think Xilinx is going to give Nvidia a run for the inference money, and vice versa. Heaven only knows where all of those startups will crack the datacenter, or if they can. They have a chance out on the edge, for sure. But the datacenter is going to be ground that Nvidia, Intel, Xilinx, and maybe even AMD defend pretty aggressively when it comes to inference.

Now Comes The Hard Part, AMD: Software
From the moment the first rumors surfaced that AMD was thinking about acquiring FPGA maker Xilinx, we thought this deal was as much about software as it was about hardware. We like that strange quantum state between hardware and software where the programmable gates in FPGAs, but that was not …
The Once And Future FPGA Maker Altera
Back in 2015, when we were launching The Next Platform, a lot of stuff was going on all at the same time, which is part of the zeitgeist that we were tapping into and that we wanted to chronical upon and participate within. And Intel was front and center of …

Time in the Sun Coming for Cloud FPGAs
Keeping an eye on how the largest cloud providers choose to invest in hardware is always interesting but it does not often shed much light on how emerging workloads are driving new investments. As an Amazon, Google, Microsoft, or other cloud, bringing the best in breed processor is simply a …
Using price/perf/watt doesn’t make sense because it gives higher power accelerators a better score. Both price and power are costs, so using perf/(price*watts) would be a more appropriate normalization.
Looking at the list price of the fpga is a bit misleading. They charge way more for the developer license!
Now that the T4 is out and numbers are available it would be interesting to see an update to this article. I think T4 performed better then the estimates at 1.6 latency it does 4919 images.