

The line between Intel’s high end desktop, midrange workstation, and low end servers has always been a blurry one, and changing the naming conventions on its products has not really changed the Intel strategy one bit.
It is with this in mind, and the substantial competitive threat that AMD’s single socket Epyc processors present, that we contemplate Intel’s “Coffee Lake” Xeon E-2100 processors launched today. While these Xeon E chips are ostensibly designed for workstations, they are also suitable for lower cost and single socket servers, although we found it curious that Intel did not really bring this up during its presentation of the Coffee Lake Xeon chips, which under normal circumstances would have been branded the Xeon E3-1200 v7 chips, following on the heels of the “Skylake” Xeon E3-1200 v5 chips that launched in June 2016 and the “Kaby Lake” Xeon E3-1200 v6 chips that were quietly launched in April 2017.
The Xeon E3 family of processors have traditionally been used for entry servers for small and medium businesses and in more recent years positioned as edge computing engines or, in the case of those processors that have their integrated graphics units activated, as video streaming machines that have accelerated encoding and decoding. This class of chips has also found its way as X86 motors inside of switches and as modest processors for cold storage arrays. Back at the dawn of the microserver revolution, which coincided with initial attempts at Arm servers as well as a few feints with Tilera or MIPS architectures, the Xeon E3s showed some promise. But the Xeon E3 chips have always had crimped memory and I/O capacity, owing to the fact that they are really designed for more modest workloads rather than for the kind of jobs that a two socket Xeon machine has traditionally handled.
But with AMD coming out strong with the “Naples” Epyc 7000 multichip processor, which crams four chips onto a single package that presents up to 32 cores, up to eight memory controllers and up to 2 TB of capacity, and up to 128 lanes of PCI-Express traffic per socket, the Xeon E3 and now the Xeon E-2100 are absolutely going to have a tough time competing for server workloads – especially with the latest Xeon D chips in the mix, too. As we have said, Intel needs to respond to the competitive threat from the single socket Naples chips from AMD. Despite the Xeon E-2100s being significantly improved over the Skylake and Kaby Lake versions of the Xeon E3, we don’t think they will see as much traction as they otherwise might. But still, we think there will be some – especially considering the volume discounts that Intel will probably give to server makers – who will opt for servers based on the Xeon E-2100s in the datacenter provided that they can live within the I/O and memory footprint and the bang for the buck is good enough.
Taking A Splash In Coffee Lake
The Coffee Lake Xeon E processors are implemented in Intel’s second revision of its 14 nanometer processes, commonly called 14++ nanometer in the nomenclature that the chip maker developed in the aftermath of its tick-tock manufacturing method – doing a process shrink tick and then an architecture change tock within a single server platform – running out of gas a bit. Historically we would have been expecting 10 nanometer Xeon E3-class processors by now, but because of manufacturing and yield issues at Intel’s fabs, that ain’t happening. And so, Intel is relying on architectural tweaks, core and memory and peripheral expansion, and pretty hefty price reductions on the Coffee Lake chips to give them a competitive chance against low-end AMD Epyc and Cavium ThunderX2 processors that are looking for homes in niche roles in the datacenter.
Let’s take a look at the Coffee Lake chip:
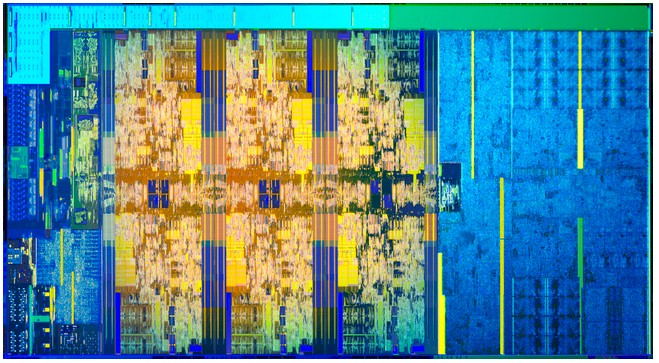
The chip is very similar to the Kaby Lake die, and in fact, it has the same UHD P630 (also known as GT2 Gen 9.5) GPU on the die as was used in the Kaby Lake Xeon E3-1200 v6 chip. (In the image above, the cores are the goldy bits in the center, the GPU is on the right and various controllers wrap around the rest on the top and left.)
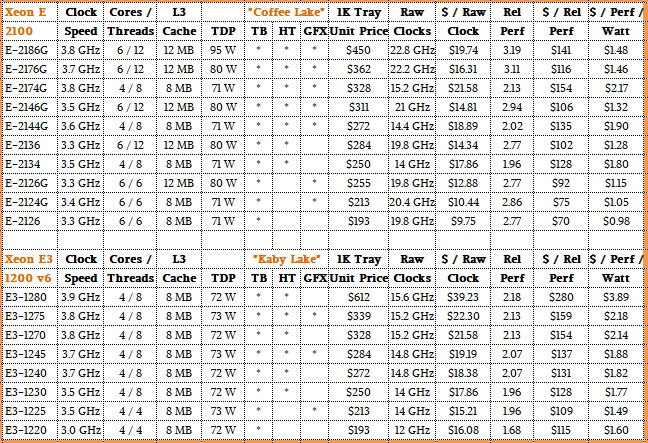
The big difference with Coffee Lake Xeon E-2100 chip is that the core count has been upped by 50 percent to six cores maximum, the L3 cache has been increased by the same 50 percent to 12 MB maximum, and the process tweak has allowed some of the Turbo Boost clock speeds to be jacked up by a few hundred megahertz. On the top bin parts shown in the table below, the Turbo Boost speeds are 4.7 GHz compared to a baseline 3.8 GHz or 3.7 GHz and on the lower end parts it is 4.5 GHz except for the low end four core Xeon E-2124, which has only four cores and 8 MB activated and which also has HyperThreading turned off.
Turning off HyperThreading is one way that Intel has dropped the price on the Xeon E3s for years; turning off the on-chip graphics chip is another way Intel does it, but honestly, it really doesn’t drop the price all that much. It is hard to say for sure with the way Intel has worked the SKUs with the Xeon E-2100s, but it looks like it is around $20 for the GPU and around $30 for the HyperThreading to be activated, as best we can figure from the table of features and pricing of the ten Coffee Lake Xeon E-2100 processors below, along with their Kaby Lake predecessors:
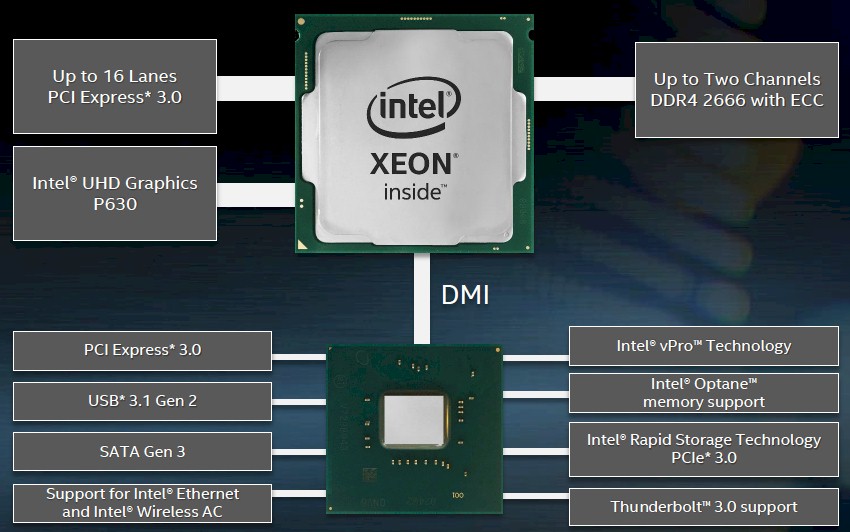
We reached out to Intel to get the single precision floating point math performance of both the Coffee Lake cores and the UHD P630 graphics engine on this chip, but we have not heard back as yet. We suspect that it offers very good bang for the buck, and that the double precision floating point is good on the chips, too, considering what they are. Let’s not kid ourselves – these are AVX-2 not AVX-512 vector math units, so the oomph here is limited. But there are plenty of compute workloads in the datacenter and at the edge that could offload math to the floating point units on the CPU or GPU in a Coffee Lake chip, and do so at excellent price performance.
The issue comes down to memory capacity and bandwidth. The Coffee Lake Xeon E-2100 has memory controllers that support DDR4 memory running at up to 2.67 GHz, but there are only two of them and they only support two memory sticks per channel and only 16 GB capacity per stick, so they cap at 64 GB of total main memory. This ain’t much in a modern day and age. The combination of the PCI-Express 3.0 controllers on the C246 Series chipset and on the Coffee Lake die itself yields a total of 40 PCI-Express lanes of traffic, with sixteen lanes coming off the chip and the rest coming off the chipset. This is not bad compared to the Xeon E3 predecessors. But a single low end Epyc 7000 has 128 PCI-Express lanes, a factor of 3.2X more, and can house 256 GB of memory using the same 16 GB memory sticks, a factor of 4X, while also offering 4X the memory bandwidth. The eight SATA 3.0 ports are useful for I/O, but are not speed demons for sure.
Thanks to the increase in the cores and caches, Intel says that the single socket Coffee Lake Xeon E-2100 will offer between 36 percent and 45 percent better performance on the array of financial services, 3D modeling, and compute intensive applications it tested compared to its Kaby Lake predecessor. That is less than expected given the core count and cache increases, but remember there are no substantial changes to the cores in terms of instructions per clock. Coffee Lake has to run a little slower and make it up in core and thread volume.
Just for reference as we get into more detailed comparisons, here are the feeds and speeds of the Skylake Xeon E3-1200 v5 chips:
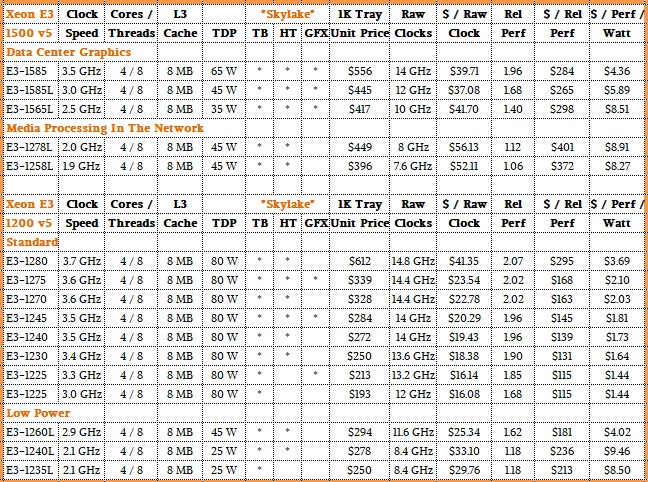
If you want to get the feeds and speeds all the way back to the entry “Nehalem” Xeon 5500 processors and see details of the chips between there and Skylake Xeon E3s, check out this detailed story we did last year.
In the tables above and charts below, we are trying to characterize the relative performance, price/performance, and cost per performance per watt of the entry Xeon servers that are suitable for datacenter and edge use in the general Xeon E3 class. To reckon a rough relative performance from Nehalem through Coffee Lake, we take the number of cores on each chip and multiply by the clocks and then adjust this for the IPC of each Xeon architecture. The Skylake, Kaby Lake, and Coffee Lake core are essentially the same at the core, and the L3 cache changes really help deal with delays in the on-chip communication ring that links the cores together. As in the past, performance is reckoned against the Xeon E5540, which is a four core Nehalem chip from 2009 that ran at 2.53 GHz, had four cores and eight threads, and 8 MB of L3 cache.
Just for fun, we are updating the comparisons across the generations that we put together with the Kaby Lake chips last year, starting with the top bin parts in each family of Xeon chips. Take a look at this chart, which shows the relative performance and bang for the buck for each generation’s most capacious processor aimed at single-socket workloads:
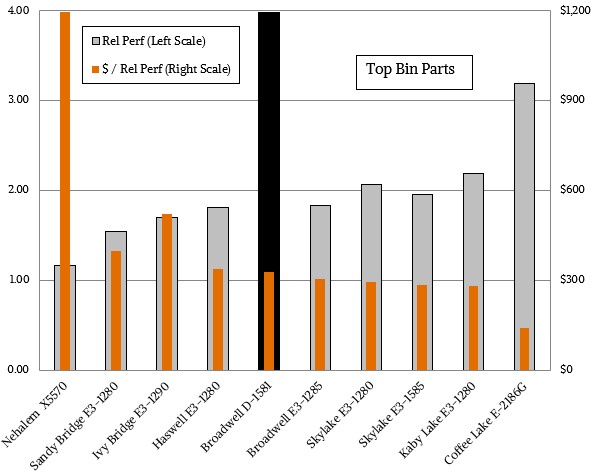
We had added in the Xeon-D chips from the “Broadwell” lineup to the comparisons, and as you can see, this chip still sets the high water mark for raw multithreaded performance in a single socket. But with the move to the six core Coffee Lake chip, the IPC improvements with the “Lake” series of cores, and increased clock frequencies compared to the Xeon-D chips (which top out at sixteen slower cores), the Coffee Lake Xeon E-2100s are catching up in terms of oomph and are offering considerably better value at the very low prices that Intel is charging. The Xeon D-1581, which as sixteen cores running at 1.9 GHz with 24 MB of L3 cache and a 65 watt thermal envelope was a microserver processor of choice for Facebook and others, but at $1,300 each at list price when bought in 1,000 unit trays, it delivered just 3.98 units of relative performance at a cost of $326 per unit and importantly a very low (for the time) $5.02 per unit of performance per watt. The Broadwell Xeon E3-1200 v4 chips of the time cost less than half as much, but with only four heftier cores, didn’t have but half as much performance.
For the top bin parts shown above, which we try to not include a graphics chip wherever possible from the SKU stacks, the Coffee Lake Xeon E-2100s represent the kind of step function in price/performance that we saw in the move from “Ivy Bridge” to “Haswell” processors several years back. It is nothing at all like the vast price drop from Nehalem to Sandy Bridge, mind you, but the performance boost of 54 percent (raw peak) from Sandy Bridge to Coffee Lake is pretty big at the top of the stack.
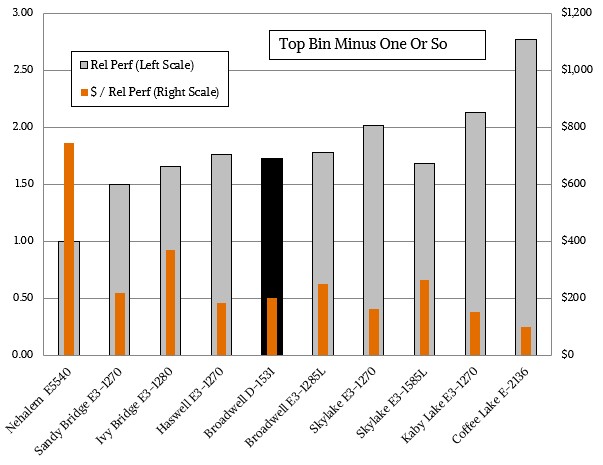
If you step down the SKU stacks across time and go with a more modest processor also near the top of the stack, the performance increase for Coffee Lake is pretty big over Skylake and Kaby Lake, and the value for dollar is also improving a tiny bit. Less than at the top bin, as is usually the case. Take a look:
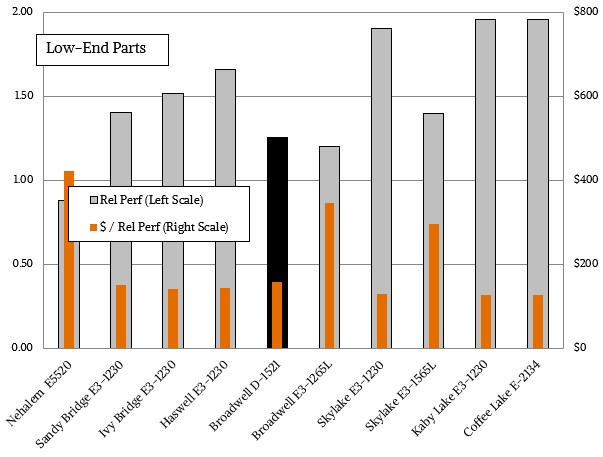
For the entry chips, the Coffee Lake chip is essentially the same as the Kaby Lake chip, since both have four cores running at 3.5 GHz at a cost of $250 each. The difference is that the Coffee Lake chip only needs to have four of its cores working properly and the GPU part of the chip can be a complete dud and it still can be sold. The improvement in the 14 nanometer process, which means there is higher yield inherently in every wafer, and the fact that it can sell partially dudded parts equates into Intel being able to drop its prices on what is effectively still the Xeon E3 line for servers. This means that it can lower the prices across the board for the Xeon E-2100s and better hold off the onslaught from the Arm collective and AMD. Here is how the entry Xeon chips in the E3-class stack up over time:
As we have said before, we think Intel needs a real single socket chip with lots of I/O and memory capacity or it is going to lose some of the two socket market to AMD and Cavium. Time will tell if we are right.

Intel’s Datacenter Business Goes From Bad To Worse, With Worst Still To Come
Everybody expected that Intel was going to turn in a pretty bad final quarter in 2022, and even before it posted its numbers yesterday after the market closed, there were plenty of signals that it was going to be worse. And it was. And the worst is still yet to …

Intel Back To Playing The Long Game, Not The Wrong Game
The supply chain is holding back the server business, and not just in the way you are thinking. Yes, there is a limited supply of manufacturing and packaging capacity for server-class processors based on the most advanced semiconductor nodes. It’s in the less obvious ways, such as the availability of …
In The Absence Of A Xeon Roadmap, Intel Makes Us Draw One
One of the oldest adages in the systems business is that customers don’t buy processors, but rather they buy roadmaps. The trick with being a server compute engine supplier – whether you are talking about CPUs, GPUs, or any other kind of device – is to reveal enough of the …
It is my impression that these new Xeon chips are physically the same as the i7-8700 6 core chips released in October last year: https://www.anandtech.com/show/11859/the-anandtech-coffee-lake-review-8700k-and-8400-initial-numbers/2 with ECC enabled for the RAM.
If so, then the floating point performance and per GHz clock rate should be identical.