

The tick-tock-clock three step dance that Intel will be using to progress its Core client and Xeon server processors in the coming years is on full display now that the Xeon E3-1200 v6 processors based on the “Kaby Lake” have been unveiled.
The Kaby Lake chips are Intel’s third generation of Xeon processors that are based on its 14 nanometer technologies, and as our naming convention for Intel’s new way of rolling out chips suggests, it is a refinement of both the architecture and the manufacturing process that, by and large, enables Intel to ramp up the clock speed on the prior generation of devices and, in the case of Kaby Lake specifically, support faster DDR4 main memory than prior Xeon E3 chips as well as the shiny new non-volatile 3D XPoint Optane memory sticks and Optane SSDs, both of which debuted in March.
Intel conceded back in the summer of 2015 that the Moore’s Law advance in chip manufacturing processes was changing, with it taking more time to do a transistor shrink than has been the case for more than 40 years. It was stretching from two years to two and a half and then looking like three when Intel conceded that it was getting tougher to shrink transistors and master the manufacturing processes to put the smaller devices into production on increasingly capacious chips. Everyone took this to mean that the pace of advances had slowed, but as Intel painstakingly argued last week in its first-ever Technology and Manufacturing Day, the chip maker is on the same course of halving the cost of transistors every two years that Moore’s Law predicts. It just is taking longer to make each step, even if the steps are bigger.
In the old days, when Dennard scaling still allowed chip makers to crank the clock speed on ever-shrinking circuits, we could get more performance that way, But somewhere between 4 GHz and 5 GHz, depending on the architecture, increasing the clock speed made chips a lot hotter, and we had to use Moore’s Law advances to make machines and their applications more parallel rather than clock higher to get more work done. There are many who say we are running out of the benefits of parallelization for CPUs and that soon, adding cores won’t get us much in terms of added performance.
Intel invented its tick-tock method of rolling out successive generations of Xeon server processors to deal with the issues related to Dennard scaling and the widening of compute elements enabled by Moore’s Law. Using this tick-tock approach, Intel rolled out a new process that shrunk transistors on essentially the same Xeon processor with some tweaks, which was the tick; the tock was the introduction of a new microarchitecture, with varying degrees of improvement in the number of instructions per clock (IPC) processed, usually between 5 percent and 10 percent for integer work and often doubling every generation or so floating point work. With the 14 nanometer Xeon chips, Intel is doing what we are calling a tick-tock-clock. The ticking and tocking are essentially the same, and in this case the “Broadwell” Xeon v4 chips etched in that 14 nanometer process are shrunken variants of the “Haswell” Xeon v3 processors that were a new architecture that made its debut in 22 nanometer processes. And the “Skylake” Xeons v5 are a new architecture that will be implemented in the perfected 14 nanometer process. The new bit is that the interim “Kaby Lake” Xeons are a revved up and more slightly tweaked chip that closely resembles the Skylake but uses a third, charming run at the 14 nanometer process.
As has been the case for many years, the Core client processors used in PCs and laptops get each new process or architecture first, and then soon thereafter, if all is going well, then the entry Xeon E3 processors for single socket servers get it next. Then, the process is used for mainstream Xeon E5 two-socket servers, and then it rolls up to Xeon E7 chips that can be employed to gluelessly create four-socket and eight-socket servers and then backcast in special Xeon E5 processors than can scale to four sockets.
The Haswell E5 rollout was finishing just as the Broadwell E3 processors were starting back in June 2015, so there is a lag as each process rolls out across the Xeon lineup. It doesn’t all just come out in one big bang. The Broadwell Xeon E5 chips for two sockets came out in March 2016, The Broadwell Xeon E7s made their debut in June 2016, and the pattern was complete with the rollout of the Broadwell Xeon E5 chips for quad-socket servers in July 2016. That took almost a full years to move Broadwell Xeons across all server types, and there is no reason to believe that the Skylake and Kaby lake generations will be any different. Ten initial Skylake Xeon E3s were launched in June 2016, right into the belly of the mainstream Broadwells coming out, and we expect for Skylake Xeon chips for two, four, or eight sockets (it doesn’t look like there will be an E5 and E7 distinction) to come out some time this summer. If Intel can keep to an annual cadence, then Kaby Lake Xeons for the “Purley” server platform should come out a year after that. What we know is that with the Kaby Lake Xeon E3s, the new generation is starting just ahead of the Skylake generation finishing up. So, technically speaking, there are multiple overlapping tick-tock-clock upgrade cycles if your granularity is a processor family instead of a chip generation, and Intel supports older processors for many years, too. So the number of SKUs in the Intel Xeon product line is just staggering.
Intel kind of quietly slipped out the Kaby Lake Xeon E3 processors right smack in the middle of its Technology and Manufacturing Day last week, and it did not make a big deal about it. This has sometimes happened with the Xeon E3s, which certainly are deployed in the datacenter but are by no means a workhorse. They are more like a sled dog, and in some instances, they are perfect for certain kinds of workloads.
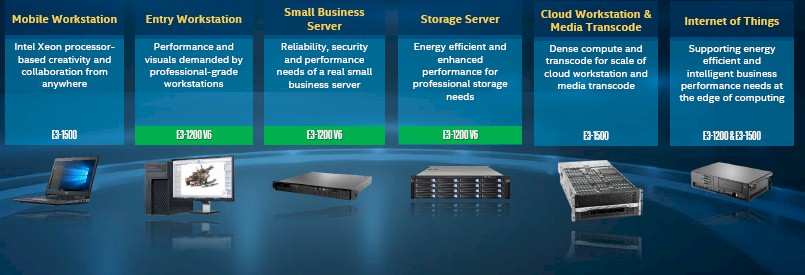
The way Intel sees it, the Kaby Lake Xeon E3 processor is perfect for edge computing for Internet of Things telemetry and analytics workloads and also is suitable for media transcoding and cloudy workstation jobs (which need the same combination of CPU and GPU resources) as well as the motors inside of clustered storage servers as well as entry servers and workstations.
And, as it turns out, they are also employed in clusters for supporting various hyperscale and HPC workloads, and as we have pointed out before, Intel is itself shifting its massive EDA compute complexes from Xeon E5 processors for two-socket machines to Xeon E3 machines that have relatively few cores and relatively high clock speeds because chip design involves running zillions of small jobs that don’t need much memory as quickly as possible and a Xeon E5 is not the right machine for the job. Intel didn’t mention these uses in the chart above, of course. And the Xeon D processor is a kind of Xeon E3 that has more cores and an integrated southbridge chipset in its package, and hyperscalers are definitely using it in their gear for both compute and storage. Facebook has said these Xeon D chips offer 40 percent better performance per watt than Xeon E5s on its software stack. So if you think a Xeon E3 is just in the markets that Intel put in its charts, you are wrong. We think there are probably some of these machines used in high speed trading and other latency sensitive parallel applications, too. But banks and trading companies would never reveal this for competitive reasons.
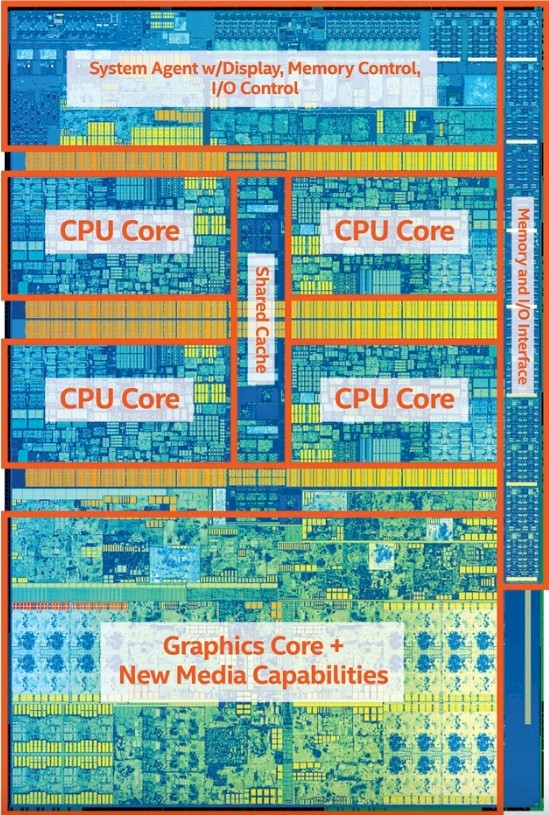
The Kaby Lake Xeon E3 platform does not have a very big memory footprint or large processing profile, but for certain kinds of massively parallel workloads, high clock speed and relatively few threads are more important than these factors.
The Kaby Lake Xeon E3 chip has four cores, just like the Skylake chip it replaces, and it also has an integrated graphics processing unit that is activated in some of the SKUs and dormant (because of yield issues on that section of the chip) in others. At this point, Intel is only launching the E3-1200 v6 variant of the chip, but it may eventually offer an E3-1500 v6 versions tuned specifically for datacenter compute and media streaming as it did with the Skylake Xeons.
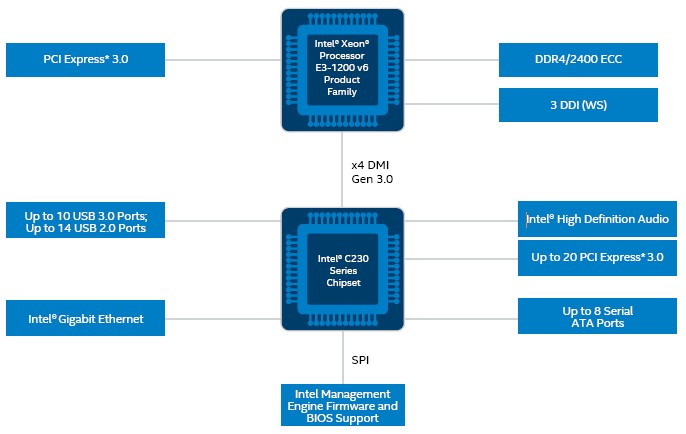
The Xeon E3-1200 v6 processors now support DDR4 main memory running at up to 2.4 GHz rather than the slower DDR3 memory used on the prior Skylake generation; both processors use the same “Greenlow” C236 chipset. The Kaby Lake Xeon E3 has support for error correction on the main memory, which makes it a true server-class product. The chip has an integrated 1 Gb/sec Ethernet controller, which is pretty limiting when it comes to integrated networking; 10 Gb/sec networking would be better at this point. But the Kaby Lake Xeon E3 supports up to 20 lanes of PCI-Express 3.0 peripheral lanes, so in theory a motherboard maker could hang a variety of fat peripheral cards off the chip if more capacious networking were required. The Intel C232 chipset, which is also part of the Greenlow platform, only supports eight lanes of PCI-Express traffic.
The main benefit of the Kaby Lake Xeon E3 processors compared to their Broadwell and Skylake predecessors is the higher clock speed and higher performing floating point units and integrated GPUs (which can through OpenCL also be used to do math) that are in the design. The top bin Kaby Lake Xeon E3 part runs at 3.9 GHz and can Turbo Boost to 4.2 GHz. Like all of the other Xeon E3 designs (excepting the Xeon D), the Kaby Lake Xeon E3s have four cores.
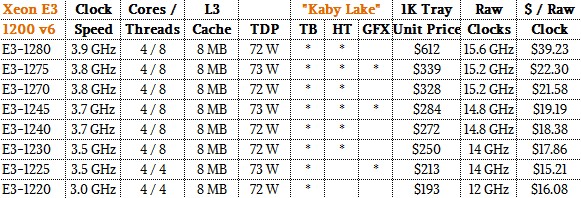
The neat bit is that activating the GPU on one of these Xeon E3 processors only adds a single watt to the thermal profile of the chip and only a few bucks to the cost. As is usual, the top bin Kaby Lake Xeon E3 chip is considerably more expensive, and has much worse bang for the buck, than the remaining chips, which only run 100 MHz or 200 MHz slower. Down at the bottom end of the Kaby Lake Xeon E3 lineup, the clocks drop down to 3.5 GHz, and the performance follows it down.
It is interesting that Intel is comparing the Kaby Lake Xeon E3 v6 processors to the “Sandy Bridge” Xeon E3 v2 processors, which came out five years ago. The top bin E3-1290 v2 chip ran at 3.7 GHz and turboed up to 4.1 GHz, which is comparable to the new Kaby Lake E3-1280 v6 running at 3.9 GHz with a 4.2 GHz turbo speed. But don’t forget about increasing IPC and other factors, like wider vector math units and better fused multiply add (FMA) units. Intel did not provide an integer performance comparison between the Sandy Bridge and Kaby Lake Xeon E3 generations, but said that on the Linpack Fortran test, the Kaby Lake chip had 50 percent more oomph on this floating work, and added that on the SPECfp_rate_base2006 floating point benchmark, it was 49 percent higher between these two generations. Intel did not provide a comparison to Xeon E3 generations between these chips, or across the families. But that is something we are going to attempt to do in a follow-up story.
The Xeon E3-1200 v6 processors support Microsoft Windows Server 2008 R2 and later variants including Windows Server 2012 (R1 and R2), and Windows Server 2016. Canonical Ubuntu Server, SUSE Linux Enterprise Server, and Red Hat Enterprise Linux all run on these machines, too, and the key enterprise-grade hypervisors – that is VMware ESXi, Microsoft Hyper-V, Citrix Systems XenServer, and Red Hat KVM – are also supported on these processors. Just like other Xeon server chips, and that is precisely the point.




Sandy Bridge was v1 and was not marked as such. v2 was Ivy Bridge.