

If you want an object lesson in the interplay between Moore’s Law, Dennard scaling, and the desire to make money from selling chips, you need look no further than the past several years of Intel’s Xeon E3 server chip product lines.
The Xeon E3 chips are illustrative particularly because Intel has kept the core count constant for these processors, which are used in a variety of gear, from workstations (remote and local), entry servers to storage controllers to microservers employed at hyperscalers and even for certain HPC workloads (like Intel’s own massive EDA chip design and validation farms). In a sense, it is now the Xeon E3, not the workhorse Xeon E5, that is literally driving Moore’s Law in terms of chip design. (Ironic, isn’t it?)
In the wake of the recent “Kaby Lake” Xeon E3 v6 server chip announced, which we covered here in detail, we decided to take a look at how the Xeon E3 has evolved over time, complete with details tables and charts comparing the performance and price/performance of the family of single-socket server chips over their lifetime and specifically compared to the “Nehalem” Xeon 5500 processors from March 2009 that represent the resurgence, both economically and technically, of the Xeon platform in the datacenter after a few years of AMD’s Opterons gaining considerable share.
To get started, let’s just line up the feeds and speeds of the various generations of chips, ranging from the “Sandy Bridge” chips from 2012 through the Kaby Lake chips this year.
As we have done for past Xeon family comparisons, we have calculated the aggregate and relative oomph of each processor by multiplying the clock speeds by the core counts to give a kind of aggregate peak clocks for each chip. This is called Raw Clocks in our tables, and you can reckon a cost per gigahertz of clock speed to get a very rough relative performance metric. We have also ginned up a more precise relative performance metric, called Rel Perf, that takes into account the instructions per clock (IPC) enhancements from each Xeon core generation, and then scaled this with the clock speed enhancements and core expansion in the Xeon lines. We created this Rel Perf metric for the first time when comparing the Xeon E5 processors from the Nehalem Xeon 5500 processors in 2009 through the “Broadwell” Xeon E5 v4 processors that came out this time last year. We reckoned the relative performance of each processor SKU across all of the families against the performance of the Nehalem E5540, which was a four-core processor with eight threads that had a 2.53 GHz clock speed. The top-bin Broadwell Xeon E5-2699 v4 processor, which has 22 cores running at 2.2 GHz, for example, has 6.34X the performance of this baseline Nehalem E5540 processor. (Intel did not have the distinction between the E3 for uniprocessor and E5 for dual-socket machines back then.)
The relative performance metric presumes that the workload is not memory capacity or memory bandwidth constrained, of course. Meaning, it fits in a relatively small memory footprint and is not bandwidth sensitive. A lot of workloads are like this, particularly for hyperscalers and HPC shops.
Here is the full lineup of the Kaby Lake Xeons just unveiled last week:
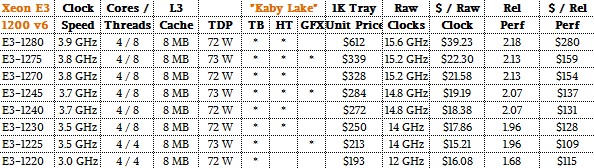
As you can see, the top-bin Kaby Lake chip, which has four cores running at 3.9 GHz, has only 2.18X the performance of that baseline Nehalem E5540 processor. About 54 percent of that 118 percent performance increase comes from clock speeds alone, which have been enabled from the shrink from 45 nanometer to 14 nanometer processes. The rest of that performance bump (and this is really a gauge of integer performance) is due to improvements in IPC in the cores and tweaks in the cache hierarchy. Floating point performance has increased by leaps and bounds over these years, of course, and so has the integrated GPU performance, which can be used to do calculations with OpenCL if you are adventurous.
You will note that the L3 cache sized on the Xeon E3s do not change that much; it is usually 8 MB, sometimes 4 MB or 6 MB in special cases.
With the core count and L3 cache constant, and only IPC and process changing, there is just not the same room to expand performance (as measured by throughput) as can be done when you let Moore’s Law push the core counts up and the clock speeds down. What is interesting is that the successive process shrinks have allowed Intel to boost the bang for the buck on E3-class chips considerably over the past eight years. The Nehalem E5540, which definitely could be deployed in a single-socket machine cost $744, or $744 per unit of relative performance as we reckon it since it is the touchstone in our comparisons. As you can see, the top bin – and therefore most expensive in terms of performance – Kaby Lake E3-1280 v6 part costs $612, and that yields a $280 per unit of relative performance rating. That is a factor of 2.65X better bang for the buck. And for the mainstream Kaby Lake Xeon E3 chips (those that have HyperThreading activated on their cores), the price/performance is averaging around $142 per unit of relative performance, and that is a factor of 5.4X better price/performance compared to that baseline Nehalem Xeon E5540. The Broadwell Xeon E5s have a bang for the buck that ranges from a low of $159 to a high of $649 per unit of relative performance. In other words, those top bin parts in the Xeon E5 have lots more throughput, but they have lower clocks and they have not shown the same kind of price/performance improvements.
This is how Intel has really benefitted from its manufacturing process prowess. Intel has, we think, been able to wring a lot more profit out its Xeon E5 parts and the middle line (operating profits) of the Data Center Group shows it. Our point is this: Intel has profits to burn when and if ARM server chip makers and AMD with its X86 alternatives get aggressive. How it will make up profits it sacrifices to maintain market share remains to be seen. But it will take some cajoling to keep the server makers of the world in line, and this time around, the hyperscalers do exactly and precisely what the hell they want to – unlike in 2003 when the Opterons plan was unveiled and 2005 when they were shipping in volume and kicking Intel’s tail.
Here is how the “Skylake” Xeon E3 processors, including specialized ones that were announced last June for datacenter and media processing uses and implemented in 14 nanometer processes like Kaby Lake Xeon E3s, line up:
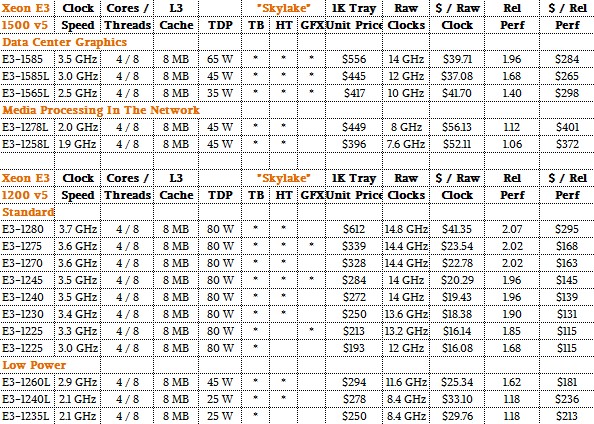
The Skylake Xeon E3s were focused more on low power consumption than performance for these specialized parts, but the more standard Skylake Xeon E3s have higher wattages but not really much higher relative performance.
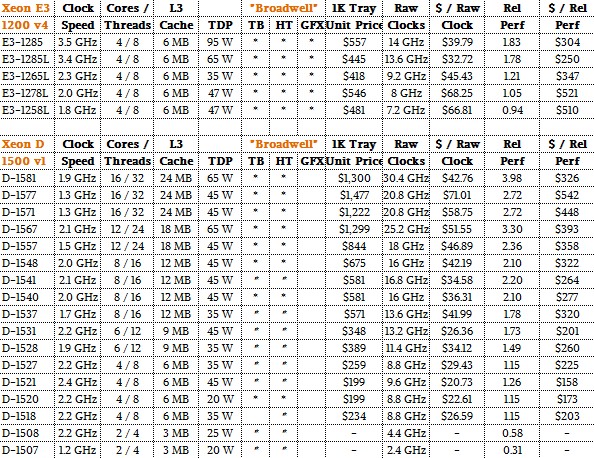
Things got interesting back in the Broadwell generation, shown above and also using 14 nanometer wafer etching, when Intel did regular single-socket Xeon E3 processors and also kicked out specialized Xeon D system-on-chip designs for Facebook and, we presume, others. The Xeon D chips were single socket processors, but had an integrated southbridge on the package and a lot more cores. They also had much higher price tags, and Intel charged a hefty premium for low voltage versions that had higher performance. These are not Xeon E3 processors, per se, but they are close to a Xeon E3 than they are to a Xeon E5.
Here are the “Haswell” and “Ivy Bridge” Xeon E3s, implemented in 22 nanometer processes, stack up:

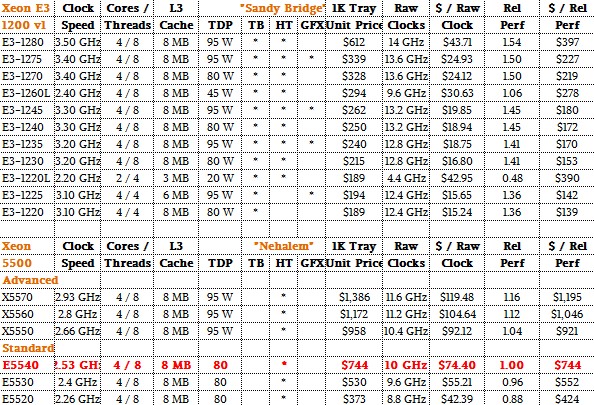
And finishing up, here are the 32 nanometer Sandy Bridge Xeon E3 parts and the 45 nanometer Nehalem 5500 parts:
That is a lot of tabular data to chew on, so we made some arts and charts to get some general trends. The first is a trend line showing the performance and price/performance of the top bin Xeon E3 parts over time compared to the top bin Nehalem X5570, which had four cores running at 2.93 GHz, and the top bin Xeon D-1581, which had sixteen cores running at 1.9 GHz. As with other Xeon processors, the price/performance curves have flattened out.
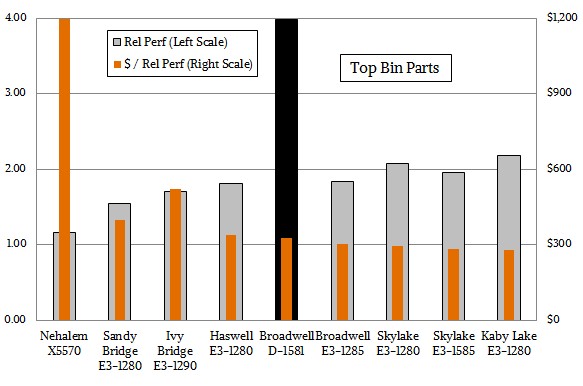
And that curve, dear friends, represents Intel’s profits. We think Intel is able to make chips a lot cheaper over this same period of time, and the company spent the better part of a whole day last week bragging about this very fact. In great and glorious detail. We think Intel always suspected it would eventually get competition again in datacenter compute, and it has been making hay – tons and tons of it – while the sun was shining on its fields alone.
This is really smart. Even right up to the moment that it encourages intense competition that causes a compute price war, which we think is coming this year. It is better to make the money between 2010 and 2017 than not make it – that is for sure.
As you can see from the top bin chart, the Xeon D really sticks out, and if offers about the same bang for the buck as the real Haswell and Broadwell Xeon E3 parts. Over the past eight years, performance has gradually trended up, but again, it has only slightly more than doubled for the real four-core Xeon E3 variants. (FYI: We have picked the Xeon E3 chips without a graphics processor in the package or on the die wherever possible to get the rawest X86 compute comparison.)
Now, let’s step back from the top bin and see how it looks:
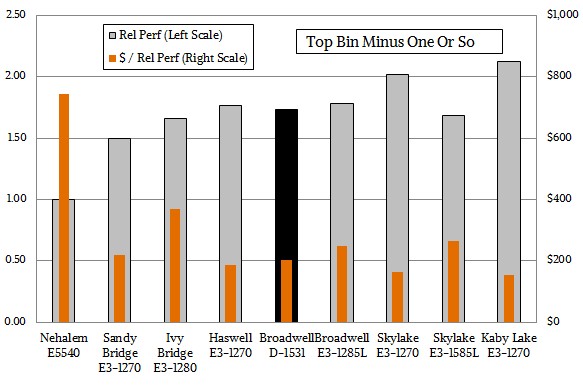
As you can see, the bang for the buck for these chips has fallen lower, but the performance and price/performance curves are not that different. And the Xeon D does not stick out so much like a sore thumb, either. (It is also interesting that there is not a Skylake or Kaby Lake Xeon D. Hmmmm. . . . )
And at the low end of the Xeon E3 lineup, the performance gains are more choppy and so is the price/performance:
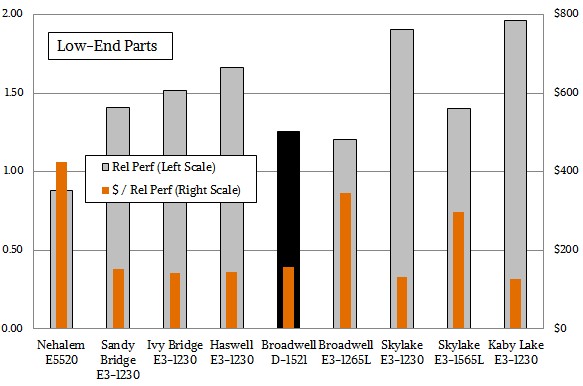
In fact, after the Nehalems, Intel kept the price/performance dead steady except for the Broadwell E3-1265L and the Skylake E3-1265L, both of which are specialized low voltage parts that fit the performance profile we were looking at. You could draw any number of charts from this data, and you have our full permission to do so. Have fun.




Given software licence costs for a lot of workloads, it would be nice to have a much larger L3 Cache in exchange for a lower core count. Yet Intel will only offer large L3 Cache with more cores then you often need for SQL Server etc. (And yes I do want memory and memory bandwidth as well without having more cores.)