
Enterprises continue to struggle with the issue of data: how to process and move the massive amounts that are coming in from multiple sources, how to analyze the different types of data to best leverage its capabilities, and how to store and unify it across various environments, including on-premises infrastructure and cloud environments. A broad array of major storage players, such as Dell EMC, NetApp and IBM are building out their offerings to create platforms that can do a lot of those things.
MapR Technologies, which made its bones with its commercial Hadoop distribution, is moving in a similar direction. The company has been working over the past several years to remake itself as a data platform company, with the cornerstone being its Converged Data Platform, which is based on MapR-FS Posix file system and integrates Hadoop, Apache Drill and Spark with database technologies and enterprise-level storage to manage big data workloads. Earlier this year, the company brought container support with the introduction of Converged Data Platform for Docker, agile analytics with a connector for Teradata, a big data platform-as-a-service (PaaS) and MapR Edge, aimed at pushing data processing and analytics closer to the network edge to address the growing amount of data being generated by the internet of things (IoT).
It appears to be working. Company officials this week said that MapR in the first quarter saw revenues jump 81 percent from the same period last year, attributing much of the growth to increasing numbers of customers and the rollout of new offerings.
The IoT is playing a key role in what many customers are struggling with now, according to Bill Peterson, senior director of industry solutions for MapR. Organizations are not only being inundated with data, but that data is coming from a range of places and in multiple formats, from containers and cloud-native applications to traditional enterprise software. A challenge enterprises are facing is storing the data in a unified manner to allow for faster access and easier analysis.
“The data is spread globally and is very dispersed,” Peterson told The Next Platform. “In some instances, organizations can’t do analytics very easily or very well on the data for a number of reasons. Some of it is siloed for historical reasons. In the last year-plus, we’ve seen a lot of interest at the edge from organizations that always had the data center. Then it was data center and cloud. Now it’s all three. It does require a different approach.”
The use of the data also varies. It can be hot, warm or cold, and it needs to be tiered to address their different uses. To address this, MapR officials are expanding the platform farther, this time into the world of cloud storage with the rollout of MapR-XD, a cloud-scale data store that is designed to give enterprises a single way to access and process the data and applications regardless of whether they come from on-premises systems to those at the edge or in the cloud. It supports containers and files, leverages flash storage and delivers scalability to support trillions of files and exabytes of data that are either on commodity servers or in the cloud.
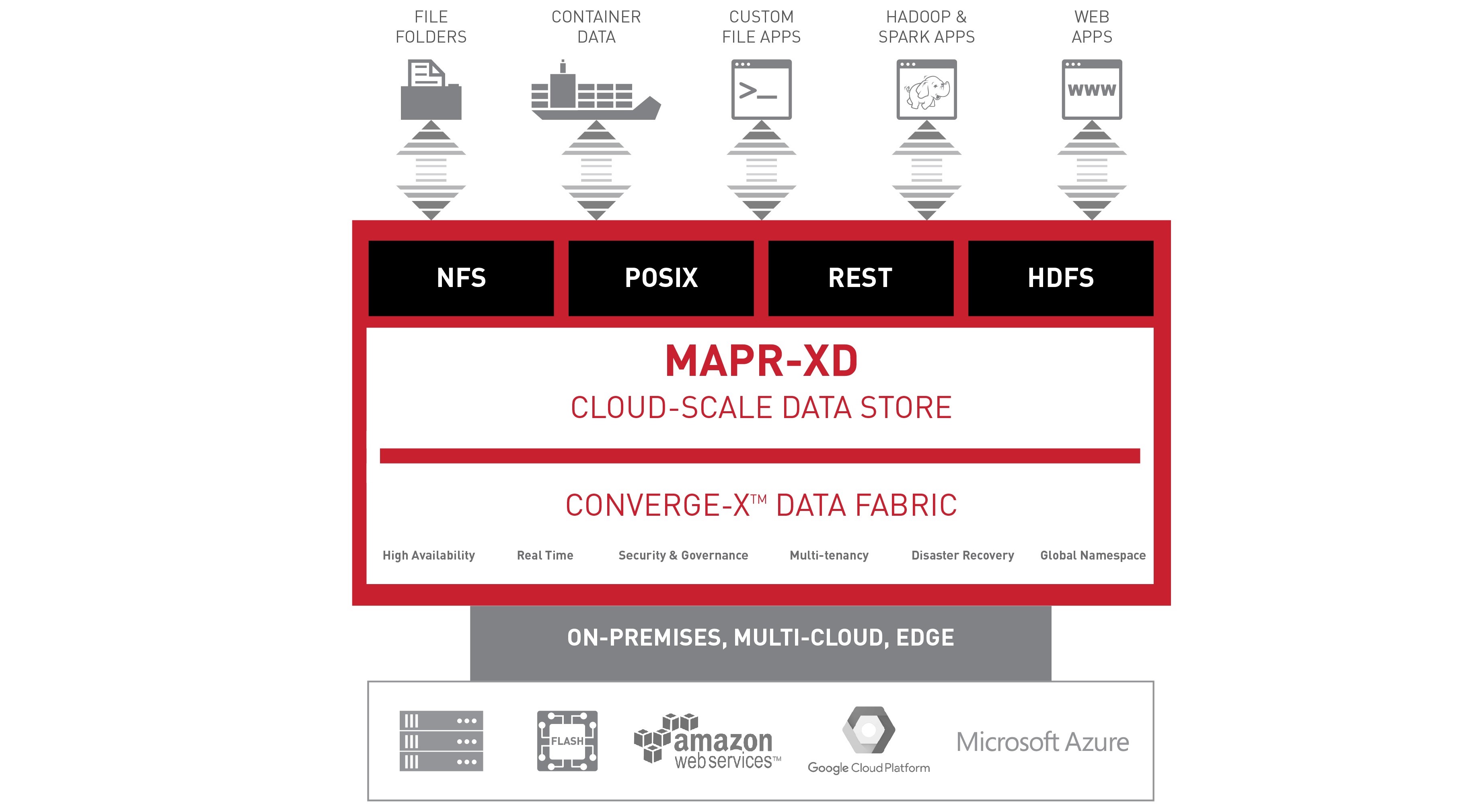
“The notion here is for storing and managing files and folders, containers and container images [and] application data – vertical apps, custom apps, what we call intelligence apps, which are the integration, operational and analytical apps – combining those in one global data space to create new apps,” he said. There’s also “the edge, and IoT falls into that bucket. We see a lot of machine learning happening out there at the edge. And then big data apps – Hadoop apps, Spark apps, any kind of apps in the big data space.”
Key to MapR’s efforts is the ability of MapR-XD to store the data and make all of it accessible through a single global namespace, giving users a single view of the data. In addition, organizations can access the data using interfaces to NFS, Posix, HDFS and Amazon’s S3 cloud storage technology. MapR-XD includes a Posix client that officials said offers 10 times the performance of a traditional NFS gateway and an optimized container client that works with Docker, Mesosphere, Kubernetes and Swarm and supports legacy and container-based applications.
MapR is offering MapR-XD – which is available now – for disk and flash, but not block storage because of the lack of metadata, which means users can’t run analysis against it. “We’re going to focus today on unstructured data for files, containers and objects,” Peterson said.
Flash is becoming increasingly important to customers given the performance it offers and the declining price points, according to Vikram Gupta, senior director of product management at MapR.
“Analytics historically has all been on disk because of density and cost,” Gupta told The Next Platform. “Over last six months, we have started to see most of our large customers, as they are going through their hardware upgrade cycles, are now looking to flash, even for analytics. It doesn’t mean they all are going to use flash in the short run, but to me it’s the canary in the coal mine to how hot flash is happening for analytics as well. Right now, it’s a flash-and-disk story, not a flash-or-disk story.”
Despite the amount of data being generated and collected, organizations are pushing to be able to save everything indefinitely, driving the need to provide a solution that can scale for the cloud.
“Everything today has to be in the image of cloud-scale,” Peterson said. “We have a number of existing customers and we hear two words a lot: ‘retain forever.’ It’s interesting because you get these customers who think they want to store all this data forever. … That’s our whole notion – putting it in one cluster and eliminating siloes and one global name space because if you do think as a customer you want to retain everything forever, you might as well have access to it and run analytics on it if you’re going to do that. Otherwise, you’re just saving it for the sake of saving it. That’s where our global name space comes in. It doesn’t matter for us – edge, data center or cloud – we can combine all of this in one cluster that to MapR looks exactly the same.”

Be the first to comment