

The talk about ARM-based servers pushing their way into the datacenter has been going for almost a decade now, during which time we have seen companies like Samsung drop their interest before they really got going on it and others like AMD getting an ARM-based chip out but then turning their attention to other initiatives.
We have also seen vendors like Cavium and Applied Micro get chips to market with some levels of adoption. Top system OEMs like Dell, Hewlett Packard Enterprise, Lenovo, and Cray are using these chips to various degrees in commercially available or test servers. And the initial enthusiasm and boasts of prior ARM executives have given way to the quieter optimism of more recent officials who have overseen the grinding work needed to keep the ambitious efforts moving forward.
And other the past two years, there has been some buzz around Qualcomm’s entrance onto the scene, becoming what one industry analyst here at ARM’s TechCon 2017 show called the best bet to be able to plant the ARM flag in the datacenter in a significant way, due to the company’s size, financial resources, and engineering chops. In recent months, Qualcomm has been active in talking about the company’s Centriq 2400 server system-on-a-chip (SoC) in the runup to the expected upcoming release of the product, conducting sessions at both the Hot Chips show in August and the Linley Processor Conference earlier this month to share more details about the processor. And so it was that Satadal Bhattacharjee, director of product management at Qualcomm’s Data Center Technologies group, spoke at a crowded session about Centriq and the datacenter during a TechCon show that put much of its focus on the internet of things (IoT).
Bhattacharjee noted that company engineers had spent a lot of time during the previous shows going through the details of the Centriq 2400, a 10 nanometer SoC that is aimed primarily at cloud providers and similar top-tier hyperscale companies, and while he touched on the key technological features of the chip, much of the talk was spent outlining the market opportunities being created by shifts in the industry toward mobility, the cloud and – yes – the IoT, and why Qualcomm is the company most capable of exploiting those opportunities to carve a path for ARM deep into the datacenter.
“The scale to which datacenters are growing … and the billions of devices that are coming out, most of those devices, including our phones, need processing that has to be done at the datacenter,” he said, pointing to millions of queries constantly hitting Google and the requests being put to digital assistants like Amazon’s Alexa. “It’s not happening on the device. Most of this is happening on the server side. So what does it mean? If there are so many devices coming out – we’re talking about trillions of devices – then the datacenters have to pack a lot more servers. There is a physical limitation in how many servers you can pack within a particular rack, so there is a strong desire to get more out of that rack space and more compute from the power limit that is there.”
That is opportunity before Qualcomm, Bhattacharjee said. Cloud providers and top-tier businesses need servers that are highly power efficient, high performance and flexible to handle the increasingly large number of workloads that are coming into their datacenters. Centriq 2400 is aimed at those use cases, where similar levels of performance can be delivered by a rack system powered by a single Qualcomm SoC when compared to an equivalent system running two Skylake Xeon chips from Intel, he said. Qualcomm was able to create such capabilities in Centriq, whose design can be seen below, because unlike Intel’s server chips, which evolved from the company’s PC processor, Centriq was based on the performance and power efficiency inherent in its mobile SoCs.
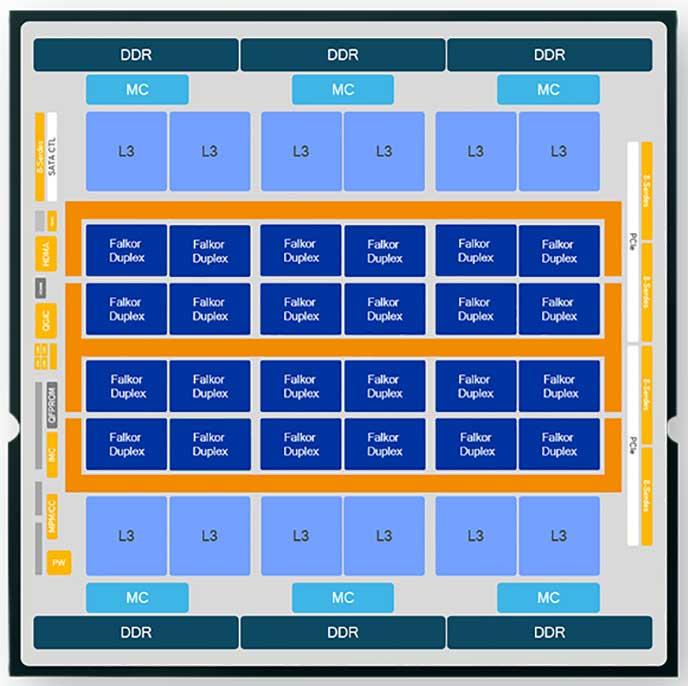
The Next Platform has explored in great detail the technologies and features that have gone into Centriq, and Bhattacharjee touched on many of them. The SoC’s “Falkor” CPU core is fully compliant with ARM’s ARMv8 design, though Centriq is the fifth custom design from Qualcomm engineers. It includes unique features from Qualcomm around such areas as quality-of-service, storage, security and bandwidth, and offers up to 48 single-threaded cores, unlike the hyperthreading that’s found in Intel chips. Bhattacharjee explained that in talking with cloud providers, they were happy enough with the number of cores available in Centriq to not want to risk the performance hit that can come with multi-threading. That said, Qualcomm is looking at adding more cores and threads in future generations, he said. The chip maker has developed two-core modules that officials call “duplexes, that share few components outside of power management and L2 cache, and communicate via ring interconnect links. The ring design – the Qualcomm System Bus – also connects the modules to L3 cache, main memory and various controllers. There’s also memory compression capabilities on the DDR4 memory and server-level power management attributes, integrated south bridge capabilities, 32 lanes of PCIe capacity and network support from 10 to 100 Gigabit Ethernet. Qualcomm has developed two reference architectures – both 1U rack systems, one a single-socket and another a dual-socket – based on Open Compute Project designs.
Bhattacharjee admitted that the Centriq 2400 isn’t a one-size-fits-all piece of silicon. It’s good for the workloads that hyperscalers see, but not as strong for many enterprise or high performance computing (HPC) applications. “For the Centriq 2400, the focus has been on the cloud customers,” he said.
Shifts in the tech industry are helping to open up the datacenter, which is dominated by Intel’s X86-based processors, he said. Not only in fast-growing need for more compute power and greater power efficiency, but also in the transition from licensed software to open-source software (which give customers greater control of their software environments and eases the migration from one chip architecture to another), from manufacturing processes based on laptops to those based on mobile technologies, and from OEMs to ODMs in the supply chain.
“IT consumption is changing from centralized, on-premises servers to more cloud-based systems, and that trend started quite a few years back and it’s not stopping as more and more applications have been shifted to the cloud model,” Bhattacharjee said.
There are still more details to come, such as chip speeds and release dates, but Bhattacharjee said the company is in it for the long haul. The roadmap includes three generations – the Centriq 2400, which is going into general production, another in development and a third in the architectural design phase – and the company has the resources to fund the work, which puts it in better position than some of its smaller rivals in the ARM server space, he said. Whether all that translates into significant market gains against Intel in the datacenter is unclear. Intel during this time has not stood still, improving both the performance and power consumption of its server chips, and more than 98 percent of servers that ship are powered by Intel processors. However, there is a desire among many businesses for a viable alternative to Intel to help drive innovation and lower prices, and the hyperscalers Qualcomm is pursuing have showed they are not shy about adopting new technologies if it means lower costs and more performance.

Broadcom And Marvell Ride The Compute Engine Independence Wave
Nvidia sells the lion’s share of the parallel compute underpinning AI training, and it has a very large – and probably dominant – share of AI inference. But will these hold? This is a reasonable question as we watch the rise of homegrown XPUs for AI processing by the hyperscalers …

Throwing Down The Gauntlet To CPU Incumbents
The server processor market has gotten a lot more crowded in the past several years, which is great for customers and which has made it both better and tougher for those that are trying to compete with industry juggernaut Intel. And it looks like it is going to be getting …
The Looming Arm Server Battle Between AWS And Microsoft
Wouldn’t it be funny if Google ends up being the stalwart supporter of the X86 architecture among the hyperscalers and cloud builders? Amazon Web Services has been pushing its Graviton line for the past several years, and has had Graviton2 in production since March last year and is still previewing …
It’s not Intel that Qualcomm needs to fear, but AMD. Thepeople that want Intel, they are going to stick with Intel So that leaves that people that “want something different than Intel”. Most of those are likely going to choose AMD. So in my opinion, Qualcomm should set its eyes on AMD as it’s #1 target.
Yes and no, as there will be Epyc x86 sales where there where Intel sales before as the Epyc Benchmarks on Phoronix and ServeTheHome show that Epyc can very well outperform Intel’s new precious metals branded parts for a much lower cost on some workstation/server workloads. And AMD has its Vega 10 die based GPU/AI accelerator IP to complement its Epyc CPUs for any heavy DP FP workloads or AI/Infrencing workloads and quite easily put Intel’s AVX 512 units in the rearview mirror if needed for HPC workloads.
What AMD has not announced is the status of that Other Jim Keller led project in addition to the Keller led x86 Zen Project. So there was a Keller led K12 custom ARM, ARMv8A ISA running, CPU microarchitecture that was supposed to share the same underlying DNA with the x86 Zen design and it was only that the K12 custom CPU core would instead be engineered to run the ARMv8A ISA.
So AMD’s K12 custom ARMv8A ISA running design could be just as wide order superscalar as the x86 ISA running Zen design with K12 having 6 integer execution units and on the FP side two multiply ports and two ADD ports(or some ARM Neon units). K12 could also support SMT and the same cache structure as Zen and the Infinity Fabric IP that will be/is included on every processor product that AMD makes from now going forward for CPUs as well as GPUs.
We will have to wait for some time in 2018 to get here to find out the final status of AMD’s K12 project but I’m sure that AMD’s Seattle Opteron A1100(Based not on K12 but an ARM holdings A57 reference design core) Arm server customers would most certianly like a K12 custom update that may be of a twice as wide(plus a little more) order superscalar than the Arm Holdings A57 in the form of a K12 custom ARM core from AMD.
Do look up some information on that The Project 47 supercomputer that is powered by 20 AMD EPYC 7601 processors and 80 Radeon Instinct MI25 GPUs. That AMD CPU/GPU based Project 47 Supercomputer Packs 1 Petaflop in a Single Rack and that will just be the first of these systems from AMD/Server partners.
I really hope that AMD will not be abandoning it’s K12 custom ARMv8A RISC ISA running design and there is really no reason AMD could not take the ARMv8A ISA and even engineer a custom design that is closer to Power8/Power9(one of widest of the wide order superscalar desings with 16 execution ports(power8) and SMT8, the Power9 comes in SMT4 at 24 cores and an SMT8 at 12 cores variants. Power is also as RISC ISA and AMD could probably get an even wider order superscalar design out of K12 using the ARMv8 ISA than even It’s Zen x86 design does with the x86 ISA. The RISC ISA designs take a lot less silicon real estate to implement and it woud be wise for AMD to stay with some form of in-house ARMv8A ISA running offerings for any future where ARM will be an even larger presence in the server room.
Also AMD really needs a custom ARMv8A ISA running CPU microarchitecture to pair with its GPU/graphics in an APU form as that x86 ISA is never getting down much fruther than only the most power hungry Tablet form factor devices. And Intel had very little success in breaking into the larger Mobile Tablet/Phone market with that x86 legacy bloat encumbered ISA and Intel wasted Billions in Contra Revenue and other resources trying without much to show for those Billions using x86.
And how are those AMD Epyc processsors doing since launch (in June)? Not much, really aside from the announced few partners (Baidu,Tencent and JD), there is little to no presence in the datacenters nor in the supercomputer sector yet. Meanwhile Intel’s Xeon Scaleable processors are now filling up he datacenters quickly (examples like Amazon, Ericsson, Tencent, Baidu, Google, Microsoft, etc) and have immediate effect on Intel’s Q3 2017 earnings even though it was launched a month later. Datacenter chips always makes the most money and highest margins. If we look at AMD’s Q3 207 earnings on the EESC (Enterprise, Embedded, and Semi-Custom) division’s income versus revenue ratio then its quite evident that AMD has not sold much of them at all (and looking like mostly console chip sales for holiday season). This points to AMD’s historical problem of delivery issues still plaguing the company. You can blame it on the slow ramp (which is the fab’s responsibility) but more likely AMD’s Epyc was rather late in the evaluation, validation and finalization phase (thus full production ramp was not initiated much earlier before launch). Additionally the lower Q4 2017 guidance, again suggests then AMD’s Epyc processors isn’t making any impact in AMD’s bottom line anytime soon.
As for AMD’s Seattle (Opteron A1100 series), pretty much abandonware already. Try looking for any server products featuring this processor other than the lone SoftIron (which probably got those chips for free). Also reports and feedback seems to indicate that AMD’s Seattle (Opteron A1100 series) is broken with problematic PCI Express bus and memory compatibility issue. This led to cancellation of the Huskyboard, plus subsequently the indeifinite delays and limited quantity of LeMaker’sCello boards. Perhaps that is why we don’t see any from major server vendors and OEMs/ODMs (HPE, SuperMicro, Tyan, GigaByte, ASUS, etc). And as for AMD’s K12, its abandoned before it ever hits silicon. Already known varporware from the beginning (never got started given Jim Keller’s short tenure and sudden departure) and exists only on old roadmaps. In recent earnings conference calls, AMD’s executives has already stopped talking about both ARM and K12 project. Likewise no longer appear on any recent AMD’s future roadmaps as well. Once AMD’s Epyc came to fruition, those ARM “side projects” gets flushed down the drain.
For your information, that Project 47 supercomputer “1 petaflop” was based on single precision (FP32) and was not based on double precison (FP64). Also most of that came from AMD’s Radeon MI25 GPUs. Quote from https://www.top500.org/news/amd-demos-petaflop-in-a-rack-supercomputer/ summarizes it nicely – “AMD is claiming the system delivers 30 gigaflops per watt of FP32 operations, which would put it at or near the top of the Green500 list if somehow those FP32 operations could be transformed to FP64. Alas, these latest Radeon parts have little 64-bit capability, making the comparison somewhat irrelevant. The current Green500 champ is TSUBAME 3.0, which turned in a power efficiency of 14.1 gigaflops of performance based on (FP64) Linpack”. In the end, that doesn’t seem to convince supercomputer vendors (like Cray) whose majority of current and future systems still mainly based on Intel and Nvidia chips. Typically supercomputers are planned from very early stages and often includes future processors. An example https://www.top500.org/news/retooled-aurora-supercomputer-will-be-americas-first-exascale-system/ and that Intel’s third-generation “Knights Hill” have not even been launched yet. Yet strangely we don’t hear anything like that for AMD’s Epyc.
We are well aware of the limitations of Epyc and Radeon Instinct, and frankly our analysis of the Project 47 cluster was better because we also brought up the money angle:
https://www.nextplatform.com/2017/08/08/shape-amd-hpc-ai-iron-come/
We adding in the floating point for the Epycs — not much, mind you — and then thought about the price delta at list price between a Xeon-Tesla cluster and then what street price has to be for AMD to make deals:
“For a frame of reference, running double precision Linpack, the most power efficient machine on the planet is the Tsubame 3.0 system at the Tokyo Institute of Technology, which is a cluster of Intel “Broadwell” Xeon E5 processors and Nvidia “Pascal” Tesla P100 coprocessors networked with Intel’s 100 Gb/sec Omni-Path interconnect. This machine encapsulates 3.2 petaflops of peak theoretical performance and burns 142 kilowatts of juice, so its comparable peak efficiency number – the one most like the calculation that Su did – is 22.6 gigaflops per watt. But you have to be careful of these peak numbers since they are, in fact, theoretical. When the Linpack parallel Fortran test was run on Tsubame 3.0, it was able to do just under 2 petaflops at double precision, and its actual power efficiency was 14.1 gigaflops per watt. At single precision, Tsubame 3.0 would in theory be able to deliver 45.2 gigaflops per watt, which is 50 percent better than the Project 47 cluster, but the bill of materials is smaller for the AMD-based system and therefore the cost should also be smaller. Our math suggests that it had better be somewhere around 35 percent cheaper to build a rack of CPU-GPU hybrids to at least to be on par, from a dollars per watt per flops perspective, and it will have to be cheaper still to win deals against Xeon-Tesla hybrids. We happen to think Epyc and Radeon Instinct will be a lot cheaper at street prices, and that server makers using these parts will win deals.”
https://www.nextplatform.com/2017/08/08/shape-amd-hpc-ai-iron-come/
The Radeon crew needs to get DP going, as we pointed out. But there are plenty of workloads where the Epyq-Radeon Instinct combo can work, if companies want to take a risk on AMD and can get the parts, of course.
Thanks for the reply and great information.
AMD’s Epyc is the only chip that is capable of taking on Intel’s Xeons, but looking around there doesn’t seem to be much happening yet. As mentioned earlier, supercomputers are planned very early and if AMD’s Epyc was chosen then some news would have been leaked out before its launch. That’s why I suspected that AMD’s Epyc is quite late in its development and finalization phase (with slow initial production ramp that follows), thus most of the supercomputer manufacturers simply could not commit to using them yet (as timeline for full volume production and delivery can remain uncertain). Companies like Cray has been affected by AMD in the past by such delays thus not keen to repeat the same mistake again when it comes to building new supercomputers with yet-to-be-launched future processors. Until AMD can correct this (delivery) problem, supercomputer companies will either place AMD as lowest priority or even pushed aside. This situation could be also similar for the datacenter market (which is why most of those companies operating cloud services still chose Intel despite AMD’s processors costing less).
Looking at the current supercomputer trends, NVIDIA simply dominates the accelerator space (followed by Intel with their Xeon Phi processors). NVIDIA’s long established dominance (with both their hardware and software APIs like CUDA) is hard to shake off, even with AMD lowering prices on their Radeon cards. As evidence of that, look at AMD’s initiatives like the recent HIP (Heterogeneous-Compute Interface for Portability) to allow cross compiling of CUDA. This is a move aimed at trying to get more people and companies to adopt/accept AMD’s Radeon cards as a good alternative to NVIDIA’s cards. Perhaps the lower prices may spawn smaller companies into the supercomputer scene (in niche applications where single precision is fine). However that will not grab a large chunk of the market share yet (which mostly belongs to big contract based installations). Additionally progress on NVIDIA’s side has been getting better all the time as NVIDIA’s latest Volta could prove to be a monster if results like this http://www.luxmark.info/top_results/LuxBall%20HDR/OpenCL/GPU/1 shows (almost double that of the previous generation). Meanwhile even AMD’s latest generation Vega architecture still lags behind NVIDIA’s current/older Pascal (especially noticeable in gaming as well). Thus, it is not simple nor easy as AMD still have to play catch up with a smaller market share and less revenues (thus smaller R&D funding).
To summarize – besides the need to create a breakthrough product and get higher acceptibility in many areas, AMD also have to solve their supply and delivery issues at the same time if they want to go head-to-head with both juggernauts (Intel and NVIDIA) in all competing markets. However processors and GPUs alone will not win everything in both datacenter and supercomputers, as shown by Intel by diversifying into FPGAs and neural computing chips while NVIDIA is adding tensor hardware into their new GPUs. Incoming future processors may be more varied than previous years, as shown by Intel’s example of having FPGAs integrated with their Xeons. Can postulate that A.I or neural chips could be next. The goal posts can move all the time in these coming years.
This part “then turning their attention to other initiatives” isn’t quite right, as AMD had been an x86 server chipmaker all along. Their new Epyc series is just another generation (displacing the highly disappointing Bulldozer based server chips). Its certain to say AMD’s efforts in ARM servers is dead and abandoned (including the future K12). Not s single news about AMD’s Opteron A1100 series (Seattle) in any enterprise server products or deployments for the whole year. That mysterious design win AMD touted was actually SoftIron (after so much speculations) since its the only company that makes products using AMD’s Opteron A1100 series. Also looking at how all the big names (like Dell, HPE, Lenovo, SuperMicro, Tyan, Gigabyte, etc) never took any interest in AMD’s Opteron A1100 chips even though they had other ARM-based server solutions certainly pose some serious questions about AMD’s initiative (or lack of it) as well possible issue with their ARM server chips.