
With the launch today by AMD of the “Seattle” Opteron A1100, that makes three 64-bit ARM processors that are finally in production for servers, storage, and switches in the datacenter. The long-anticipated delivery of the Opteron A1100, which is more than a year late coming to market, nonetheless marks the increasing maturity of the ARM server ecosystem. Now it is up to the market to tell us precisely how useful the Opteron A1100 chip will be in the datacenter.
AMD has some stiff competition in the ARM chip arena now that Applied Micro has its X-Gene 1 out and X-Gene 2 chips ramping and Cavium is also shipping its first-generation ThunderX processors, both of which bring much more computing to bear than AMD’s Seattle. Few of the ARM server chip makers believe they can take on Intel’s hegemony in the datacenter with the Xeon processors head on with their first products, and they are being very careful to target their initial ARM processors at very specific workloads on the periphery of the core compute complexes at most organizations where the Intel Xeon prevails.
This is not a bad strategy, of course. This is precisely how Intel toppled proprietary minicomputers and mainframes and RISC/Unix platforms in the datacenter with the Xeons, starting from the PC and working its way up from file servers to core machines running mission critical applications. As The Next Platform has pointed out time and again, the attack usually comes from below when the processing technology changes in the platform, and in this case, the ARM upstarts are taking the chips preferred by smartphones and tablets and beefing it up to take on server jobs. The idea, according to ARM Holdings, the licensee of the ARM architecture, is to provide an increasingly broad and deep chip lineup across multiple vendors and by 2020 to take at least 25 percent of the server shipments in the world. It is an ambitious plan, and one that has had its bar raised from 20 percent only a year ago.
AMD has been a part of this plan for several years now, and with the delivery of the Opteron A1100, it hopes to get a little revenue return on its development investment and set the stage for the future “K12” ARM server chips expected in 2017. Daniel Bounds, who took over as senior director of datacenter solutions at AMD last October, did not mention the K12 effort as part of the prebriefings concerning the Seattle chip. But with the Opteron A1100 launch, all eyes will turn to the future even as AMD tries to keep its partners and potential customers rooted in the present, which is still early days for the ARM assault on the datacenter.
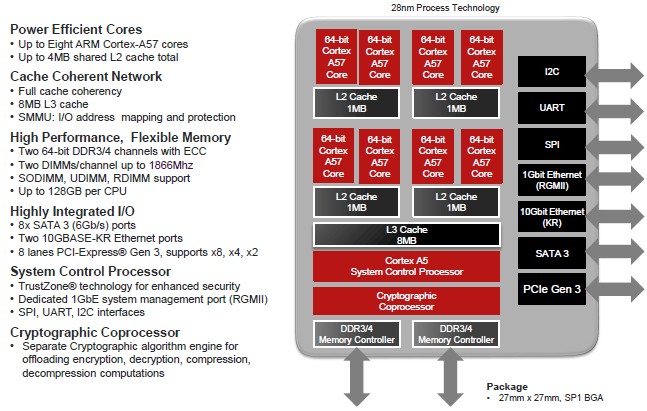
The basic feeds and speeds of the Opteron A1100 have been out since the middle of 2013 and the chip has been sampling since March 2014, but with the actual launch, we now get a sense of the SKUs and the pricing for the Seattle chips. Bounds also gave us a sense of the performance of the chips, but don’t get too excited. Like other ARM server chip makers, the data is thin and largely anecdotal.
To recap briefly, the Opteron A1100 was designed to compete with the four-core Xeon E3 processors that Intel partners use in workstations and low-end servers, and to basically have twice as many cores and twice as much main memory, giving it a leg up over the Xeon E3s and some ability to compete with the low-end of the Xeon E5 line for certain workloads. To get its first ARM processor out the door quickly, AMD decided to use ARM Holding’s stock Cortex-A57 cores in Seattle rather than design its own cores, as it is doing with the future “K12” ARM chips.
That speed didn’t happen as plans. The time between when the world knew about the Seattle project and when AMD is actually delivering is many years, and that left Intel with plenty of time to cook up the “Broadwell-D” Xeon D processor, which launched last March. The Xeon D is a stop gap that takes a real Xeon E5 and gears it down and adds a chipset on the package to compete with the ARM upstarts and their system-on-chip designs. (Xeon D also calls into question Intel’s own Atom server chips.) In November last year, Intel expanded the Xeon D line and provided some performance benchmarks for the key compute, storage, and network function virtualization workloads that it is aiming the Xeon D processor at, largely among the hyperscalers. Intel now has a dozen Xeon D parts, which scale from 2 to 8 cores running at between 1.2 GHz and 2.4 GHz, with 3 MB to 12 MB of L3 cache on the chip, and with thermal envelopes ranging from 20 watts to 45 watts. Intel is not providing pricing on the two lowest SKUs with only two cores, but on the other variants of the Xeon D, the prices for a single 1,000-unit tray range from $199 to $581 for each processor.
We presume that Intel is perfectly happy to provide customized versions of the Xeon D processors, as it has done for the Xeon E5 and Xeon E7 processors, but Bounds said that with the Seattle chip, AMD is not intending to offer custom parts to potential customers. There are three different SKUs of the Opteron A1100s, and that is it. Here they are:
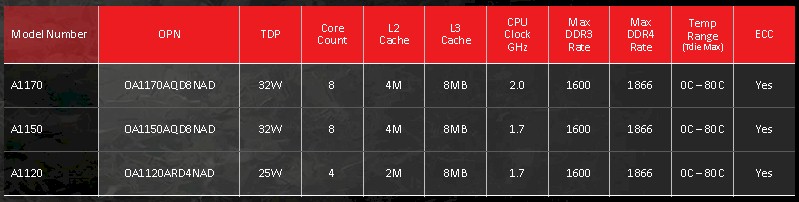
AMD is not releasing pricing for all of the Opteron A1100 chips, but Bounds tells The Next Platform that the top-bin part, with eight cores running at 2 GHz, 8 MB of L3 cache, and a 32 watt thermal design point, will cost under $150. Pricing on the other chips will scale down from there. If you put a gun to our heads, we would say the eight-core part running at 1.7 GHz would cost about $120 and the four-core part will go for maybe $80. But those are just wild guesses. What is obvious is that the Opteron A1100s are much less expensive than the Xeon D chips. The question, of course, is what performance can you get for the money? We asked.
“While we have synthetic benchmarks, we decided it is more important to make sure we are empowering our partners, and you will see more characterizations come out for particular workloads,” Bounds explained. “I will tell you anecdotally that we compare favorably to Atom on an apples-to-apples compiler perspective. When we get into higher frequency, more robust cores, we have to look at the situation a little differently. Because the book has not been completely written on these workloads and use cases, we think that in the next couple of months when customers begin to put this product on the bench and test it out, we will learn from that as well.”
With 14 SATA 3 ports and two 10 Gb/sec Ethernet ports being driven from the system-on-chip, the Opteron A1100 is a natural choice for storage servers where compute needs are modest. So it is not surprising that one of the key target workloads for the Seattle processor is Ceph object and block storage and OpenStack Swift object storage. AMD also thinks there is some play for the Opteron A1100 in Hadoop and Cassandra data stores, too. The machines are also being targeted at the traditional LAMP stack, where Linux, Apache, MySQL, and PHP or Python underpin Web serving, Java application serving, and Squid or Memcached caching workloads. AMD is also pitching the chip as a host for data plane, virtual function I/O, deep packet inspection and similar network jobs as well as for modestly powered OpenStack compute clouds. AMD is also keen for developers to use Seattle machines to port their applications from X86 and Power architectures to ARM.
More than anything else, AMD believes that Seattle can be the mainstream part that the ARM ecosystem has been waiting for.
“Mainstream is a critical part of this,” said Bounds in reference to the Seattle launch. “In the past, there have been fits and starts with ARM In the datacenter, whether that be in a traditional compute environment or whether that be in the networking or comms environment or whether that be in a storage environment. All of these kind of matriculate back to the need around core mainstream features and being able to take advantage of a 64-bit design, and enabling that design with elements like ECC memory or different flavors of Linux that are developed, tested, and most importantly supported for this platform.”
While AMD is certainly larger than either Applied Micro or Cavium, the fits and starts with the Seattle product and the rewriting of its product roadmap as it killed off its “SkyBridge” unified X86-ARM platform last year did not help build confidence. That is all water under the bridge now, but still people want to know what took so long. Bounds offered this explanation:
“There was maturity in the silicon that we had to work through. For the server space, this is the first time this business unit had brought to market an enterprise-class part. It took a little bit longer – significantly longer – than we originally intended. However, in many respects, when we look at the readiness of the ecosystem, a lot happened in 2015. So in terms of lost time, I am not sure we lost a lot of time. We would have loved to have this part out much earlier, but the fact remains we are happy to be in production at the beginning of 2016, our partners are there in lockstep with us, and we think there is tremendous opportunity this year.”
One of the things that AMD is doing to stir up support for the Seattle chip is offer a ten-year guarantee that parts will be supplied – something it has done for embedded versions of its X86-style Opterons in the past.
As for initial partners for the Opteron A1100, there are a few. SoftIron, an upstart server maker that has been part of the ARM movement for a few years, will deliver a version of its Overdrive3000 systems using the chip and is also working on a range of storage products. CASwell, which is part of the Foxconn IT and consumer gear manufacturing conglomerate, is rolling out an NFV platform based on Seattle, and the 96 Boards effort to make cheap development servers that cost hundreds of dollars rather than thousands of dollars is also working on a Seattle machine.
Hopefully others will follow. But we suspect that what the system makers of the world want to know – including OEMs, ODMs and their hyperscale customers, and more than a few HPC centers – is what the Opteron K12 ARM chips will look like and how they will compete against the “Skylake” Xeons of the 2017 timeframe.


Throwing Down The Gauntlet To CPU Incumbents
The server processor market has gotten a lot more crowded in the past several years, which is great for customers and which has made it both better and tougher for those that are trying to compete with industry juggernaut Intel. And it looks like it is going to be getting …
Making Dollars And Sense Of Arm Holdings
The only thing stronger than having absolute control, as happens in monopolies and oligopolies, is the strength that comes from numbers. Both are economic principles as well as technical ones, and they both come together powerfully in the IT sector in general and in the semiconductor industry specifically. In this …

The Steady Hand Guiding AMD’s “Prudently Expanding” Datacenter Business
The old AMD – the one before Lisa Su took over – was often brilliant with its instruction set architecture and CPU designs, but sometimes perplexingly careless with its design choices and chip roadmaps. And so it had a bit of a boom-bust cycle in its epic battles with archrival …
Simple answer: NO. They are too late not much and they do not offer enough compelling difference to other ARM players out there
Until K12 gets to market, and Jim Keller hopefully has baked SMT capabilities into K12’s DNA. Simultaneous MultiThreading (SMT) in a custom ARMv8A ISA running micro-architecture will make more efficient use of the K12 core’s execution pipelines by hiding any processor thread latency and keeping those execution pipelines running at as close to 100% utilization as is feasible! Let’s hope what Jim Keller alluded to in some of those YouTube video interviews that both his Zen(x86) and K12(ARM) design teams where sharing many CPU core design tenets among their respective projects, and there will be a custom ARM K12 with SMT, and similar Caching design, and Other similarities in the K12 to the Zen x86 design that AMD will be introducing this year. So maybe AMD’s K12 and Zen cores have a lot of their design in common, and it’s only that they have been engineered to run their respective ISAs!
If for just getting AMD’s ARM based software stack in order while producing revenues for the future, Seattle will be worth the effort until K12 arrives to hopefully give AMD an edge in the ARM based server market.
Don’t think it will matter much K12 is too late too and if doesn’t allow customization they are doomed because who’s going to buy it? All the big players want customization or are in process of building their own ARM-based server chip in the meantime (like Amazon). So there will be no market as usually AMD is too late.
Your back to your usual, saying it’s so because you say it’s so, but if K12 has that SMT ability then it will be able to get much better CPU execution resources utilization than the other ARM maker’s SKUs that don’t have any SMT ability in their ARM based CPU cores. And Amazon could potentially be an AMD ARM customer, even for some semi-custom ARM K12 cores built for Amazon’s exact needs.
If AMD can make custom console SKU’s for the Xbox One and PS4, I’m sure that AMD could make a nice AMD K12 based server APU on an interposer with the K12 custom ARM cores wired directly into a Polaris GPU accelerator via that interposer’s silicon substrate and have a complete value added package and Amazon could fund a semi-custom K12 SKU from AMD and have it for their exclusive use just as the console makers have funded their console SKUs for their exclusive use. Unless Amazon could perhaps hire Jim Keller with its Wods-O-Cash, but still a from the ground up design will take Amazon at least 3, or more years to do, even with someone like Keller on board.
AMD’s APU’s on an interposer, ARM or x86 based, will have something that the others do not offer and that is devices made from separately fabbed CPU cores, and separately fabbed GPUs, FPGAs, other processing elements, and HBM, so potential customers may just be able to mix and match the components they need for many types of server workloads simply by asking AMD to add more processing horsepower on that interposer package, and AMD even has FPGA’s added onto the same HBM memory stacks between the bottom HBM controller logic die and the HBM memory dies stacked above, for a Dagwood sandwich of in memory FPGA compute for specialized server workload acceleration on the HBM memory stacks. I think that for custom ARM based server chips the next step for getting better utilization for CPU core resources is SMT, and added to that it’s GPU acceleration for the number crunching that may be needed with any ARM based server SKUs that are needed for other than web serving, storage management workloads, etc.
Those interposer direct links between CPU cores and a GPU’s cores will most definitely offer more bandwidth than any 16X PCIe lanes with interposer based APUs having potentially thousands of traces running directly from CPU to GPU carrying whole blocks of Cache, and other data/instructions, in a single clock or half clock, to and from CPU cores and the GPU’s cores, and maybe even unified cache memories with cache coherency traces running between CPU and GPU with cache coherency processor/s functional blocks keeping things synchronized in the background while both CPU/s and GPU/s go about doing their intended workloads. Just look at the bandwidth of HBM2 with 1 Terabyte per second of potential effective bandwidth and 4096 traces clocked at about 7 times less than GDDR5 memory, and maybe the CPU to GPU connection interposer traces counts could be even wider than 4096 traces and it would not be hard to transfer whole blocks of data at a time. There is other IP that AMD can add to their ARM based offerings that the other ARM based makers lack.
Amazon already own an ARM soc-customized blue-chip designer company since a couple of years. I don;t think they need AMD nor do they need Jim
For those wondering what happened to AMD’s “Seattle” Opteron A1100 series and why there are still no major server OEM/ODM (e.g. HPE for Moonshot servers) nor manufacturers (including AMD’s own SeaMicro) adopting it , just read the following clues below…
First https://www.phoronix.com/scan.php?page=news_item&px=AMD-No-Cello-Or-HuskyBoard quote quote “From one ARM board distributor I contacted, they’ve been given “the silent treatment” from LeMaker over the status of the Cello’ and likewise ‘For the HuskyBoard, it’s no longer listed on the 96Boards site under their enterprise boards. The HuskyBoard page is still there though and it says, “This board is not yet in mass production, but an alternative version created by LeMaker and called the Cello Board is available for pre order with shipments expected by the end of Q2 2016.””
Later http://www.phoronix.com/scan.php?page=news_item&px=AMD-ARM-Dev-Boards-End-2016 quote “Since writing that article last month, I heard from a trusted comrade that a technical obstacle has delayed AMD’s ARM SoCs”
Finally these appeared http://www.expreview.com/50198.html and lookit https://nl.hardware.info/nieuws/49717/amd-krijgt-pci-express-slot-van-arm-platform-al-maanden-niet-werkend hints that AMD’ Seattle’s PCI Express bus is broken and the problem hasn’t been solved for many months already despite new firmware being promised.
More confirmation http://mrpogson.com/2016/09/01/lemaker-cello-news/ quote “Appologize to delay the Cello board again. We produced 10PCS samples on sencond-stage in July and sent to Linaro and AMD to debug. Still the problem is on the PCIE connector. The PCIE power rails, clock, reset signal and tx lane are all work, but only the rx lane can not get the signals”
This is also why AMD’s Hierofalcon, also based on AMD’s Seattle chip, simply disappeared off the roadmaps as well. Furthermore most likely AMD’s K12 is scrapped for good as AMD had stopped talking about it. Currently AMD’s Seattle ended up at a small and obscure company named SoftIron http://softiron.co.uk/products/ still as a “development” platform, even after “sampling” for very long time. Question is whether that company is aware of the PCI Express problem.
I don’t agree, read: https://www.theregister.co.uk/2016/01/14/amd_arm_seattle_launch/