

Many have tried to wrench the door of the datacenter open with ARM processors, but Qualcomm, which knows a thing or two about creating and selling chips for smartphones and other client devices, has perhaps the best chance of actually selling ARM chips in volume inside of servers.
The combination of a rich and eager target market with a good product design tailored for that market and enough financial strength and stability to ensure many generations of development are what are necessary to break into the datacenter, and the “Falkor” cores that were unveiled this week at Hot Chips were the third leg of that stool.
While many of the details of the future “Amberwing” Centriq 2400 processor remain under wraps, the techies who created this chip know plenty about server chips and have clearly been working with the hyperscalers to make sure it has the features they need to make it a credible alternative to an Intel Xeon chip for many of their workloads. And, importantly, a contender against Cavium’s ThunderX2 chip, which is the main ARM server chip to get any traction in the market and which is still in the very early part of its ramp.
It has taken hundreds of engineers to bring the Amberwing chip, which is the fifth custom ARM processor that Qualcomm has developed, to fruition, and the people steering the project have chip chops. Anand Chandrasekher, who is senior vice president and general manager at the Qualcomm Datacenter Technologies unit that is trying to break into the datacenter, ran Intel’s Centrino and Atom mobile chip businesses as the chip giant tried (largely unsuccessfully) to break in against the wall of ARM processors in mobile devices, and now is trying to smash through a wall of Xeons to get into the glass house. Dileep Bhandarkar, who is vice president of technology at QDT, has been leading chip design efforts for decades at DEC, SGI/MIPS, Intel, and Microsoft, and most of the projects were for server chips. Thomas Speier is chief CPU architect and is one of the original members of the Qualcomm Snapdragon processor design team and worked on PowerPC designs at IBM before that. Barry Wolford who is the chief SoC architect at QDT, and was formerly worked on Power and System z processor designs at Big Blue.
Qualcomm has brought in plenty of server expertise over the past five years as the Amberwing effort took shape, and it is creating a custom core that uses many of the techniques and tools that it employed with its four generations of client chips, but it has created a true server variant that is distinct and tuned for the datacenter. This is exactly what Intel, AMD, and Nvidia do with their server compute engines, and ironically, it is not what the other server chip vendors do because they do not have a desktop foundation on which to stand.
Over the long haul, this, more than any other factor, may be the one that means success or failure among the ARM upstarts.
The Falkor core is compliant with the ARMv8 spec, and unlike other ARM server chips, Qualcomm has ripped out all of the circuits that would deliver 32-bit support and only put in circuits that will support 64-bit processing and addressing. While such backwards compatibility is important for client devices that have long since used ARM chips, server workloads have been running at 64-bits for a decade and a half on most platforms and there is no backwards compatibility issue to address. Chris Bergen, who is senior director of product management for QDT, tells The Next Platform that it is difficult to quantify precisely how much real estate the 32-bit support takes up, but adds that dropping 32-bit support without question has allowed Qualcomm to create a more streamlined core and therefore it can add more cores to the Amberwing die than it might have otherwise been allowed to do.
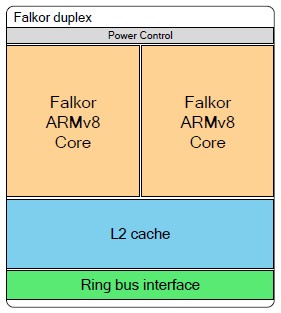
The initial Centriq 2400 ARM server chip has 48 cores, and they do not have simultaneous multithreading (SMT) on the cores to try to virtualize the instruction pipeline and get more work out of the cores on heavily threaded workloads as RISC server processors from IBM, Oracle, and Fujitsu do or X86 server chips from Intel and AMD do. Qualcomm has created a two-core module as the basis for the Amberwing chip, and these are two true cores that can take on a full load of work and that are not sharing components other than L2 cache, power management, and ring interconnect links.
As is the case with many server chips both past and present, these two-chip modules are linked to each other and to main memory controllers, to peripheral controllers, and L3 cache by a ring interconnect. Many of the details of this ring interconnect, which is called the Qualcomm System Bus, have been purposefully obfuscated, and Wolford said that there are actually two rings unlike the diagram above, with one moving clockwise and the other counterclockwise. This ring bus uses a proprietary protocol, and is fully coherent across the caches and I/O in the system on chip, and also have shortest path routing between elements to cut down on latencies. (The ring controller knows how busy each ring is and figures out the quickest way to move data between two points based on traffic and distance, and it does multicast on reads, too, to boost performance.) This ring has more than 250 GB/sec of aggregate bandwidth.
As you can see above in the chip tile diagram, each pair of cores has a shared L2 cache for storing instructions and data as closely as possible in the event that the L1 caches on each core can’t find what they need.
Bergen says that the L1 instruction cache was derived from the mobile chips it has developed, and it includes a 24 KB L0 instruction cache that hangs right off the core with a zero cycle penalty for a hit, and then this is hooked into a 64 KB L1 instruction cache that looks and feels like 88 KB as far as the core is concerned. That cache has a four cycle penalty for an L0 miss and the same for an L1 hit; this two-level instruction cache is exclusive, so the L0 cache is not copied into the L1. The L1 data cache weighs in at 32 KB, and there is a three cycle latency for a hit on this cache. Bergen says that this L1 data cache gets the performance of data caches with twice the capacity on other chips.
The full specs for the L2 cache sizes were not revealed, but we expect something on the order of 256 KB to 1 MB per core. It all depends on what die size Qualcomm can push with the 10 nanometer process it is using to etch the chips. (The company has not revealed its foundry, but we presume it is Taiwan Semiconductor Manufacturing Corp and we are pretty damned sure it is not Intel and it is very likely not Samsung. It could be GlobalFoundries, of course, but probably not.) The kinds of cloud workloads that Qualcomm is targeting with its initial ARM server chips need lots of L2 and L3 cache, but perhaps not as much as is needed for traditional enterprise applications like relational databases or even some HPC workloads.
What we can tell you about those L2 caches on the Amberwing die is that they are inclusive of the L1 caches (meaning they keep local copies of what is in L1 inside of L2) and that they are eight-way associative with 128 byte lines and are interleaved for performance with 32 bytes per direction per interleave per cycle. Bergen says that it takes about 15 cycles for a latency hit to the L2 cache, and that is on par with Intel, which took 12 cycles for the 256 KB L cache in “Broadwell” Xeon core and 14 cycles for the 1 MB L2 cache in the “Skylake” Xeon core. That Skylake core is bigger and also segmented, with 768 KB hanging off the side, like one of the AVX units, so that may be part of why it has more latency. This might suggest that the Amberwing cores have something more like 1 MB of L2 cache, which would be a lot, and perhaps a smaller L3 cache, as Skylake server cores do. It is hard to say. As is absolutely necessary for server workloads, the Amberwing chip has ECC error correction on both the L2 and L3 caches, and the L0 and L1 caches have parity protection with autocorrect.

The pipelines on the Falkor core are heterogeneous – meaning they have lots of different kinds of instructions they can process – and the pipelines are of varying lengths so those different kinds of instructions and data can be run through the core in a way that minimizes idle hardware. The core can issue four instructions and one brand per clock cycle and can dispatch eight instructions per clock. Qualcomm is quite proud of the fact that it has a server-class branch predictor that can stand toe-to-toe with anything that Intel, AMD, IBM, Oracle, or Fujitsu has put into the field. The pipeline can have 128 uncommitted instructions in flight, plus another 70 instructions waiting in registers and buffers for retirement, and the out of order architecture can do loads, stores, ALU instructions, and branches and retire up to four instructions per cycle.
Three of the key features in the Falkor core that make it a server chip are its fine-grained power management, the quality of service on the shared L3 cache that hangs on the ring and is available to all of the cores on the Amberwing die, and native memory compression on the DDR4 memory, akin to what AMD has done with the Epyc X86 server chips it launched back in June.
The cores on the Amberwing die have base and turbo frequencies, and while Qualcomm is not saying what these are, the company did say the chip will run at 2 GHz and higher, which is not too bad for a chip that is going to cram 48 cores on a die. This is about the same frequency as the top bin Skylake part, which has 28 cores, can do, but then again, that Intel core has two 512-bit wide AVX-512 units to do floating point operations. While Qualcomm will have enough floating point oomph to be useful in certain scenarios, no one expects for there to be something on the order of 1.8 teraflops peak like the Skylake can deliver per socket with the 28-core SKU and the pair of AVX-512 units clocking down to 2.1 GHz. (On the Linpack test, sustained performance is more like 1.6 teraflops.)
The Amberwing chip has dynamic voltage frequency scaling so that when parts of the chip are unused the clocks on the cores can be goosed a little higher to squeeze a little bit more performance out of them. The cores have a light sleep mode that gates off the CPU clocks when they are not in use, but voltage is live across registers and caches to retain the state of CPUs for a bit. The caches can be turned off it they go fallow, and then the registers and L1 caches are collapsed and their state is lost. The hardware assist for P states and C states, like that on the Xeon chips, cut back on power draw for the cores, and there are similar power states for the L2 cache, which can gate itself even if the cores are humming along if some of the cache segments are not needed. If both CPUs on the Amberwing chiplet enter a low power state, the L2 cache may enter a retention or collapsed mode as the condition warrants. The basic idea of the power management functions on the chip is that it can do a full shutdown with a fast return on the cores and that it minimizes power in every way practical – something you would expect from a mobile chip maker.
Because L3 cache has such a big impact on server performance, Qualcomm’s engineers did a lot of work on trying to bring down contention for this resource. These quality of service features will be particularly important for the virtualized server workloads that are typical in both private and public cloud infrastructure these days.
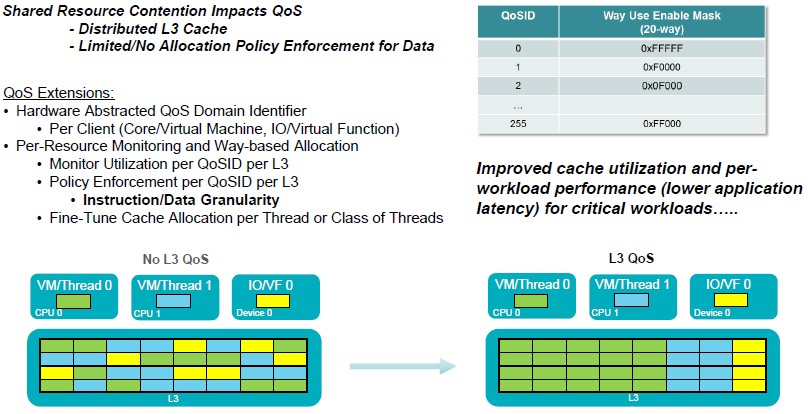
The main function of these L3 QoS features is to partition the L3 cache and provide an affinity between cache segments and particular virtual machines running on a server, as shown above. It is not clear how much this affinity affects performance, but presumably it is above some threshold (say 5 percent) to make it worthwhile to do. The L3 cache can be partitioned so a chunk of it can be reserved for a core, I/O devices hanging off the peripheral controllers as well as the VMs; the L3 QoS function can also be used to create an instruction pool that feeds more directly back into the L2 caches and then into the L1 instruction caches on the Amberwing chiplets. It is not just about smoothing out the performance of VMs.
For memory compression, which IBM added to its Power chips several generations ago, the compression is done inline on the memory controllers themselves, unlike what IBM did with an on-chip compressor and like AMD has done with the Epyc chips.

This inline compression is based on a Qualcomm algorithm and it compresses 128 byte lines in memory to 64 bytes whenever possible, with the ECC encoded with the compression bit. This compression takes from 2 to 4 cycles, which is not much of a hit, and it has the effect of boosting the overall effective memory bandwidth of the processor.
The Falkor core has hardware assist for hypervisor server virtualization (EL2) and TrustZone secure partitions (EL3), and Qualcomm is also adding optional accelerators that support AES encryption and SHA1 and SHA2-256 hashing. It is not clear if these cryptographic and hashing units are on the Amberwing chiplet or on the SoC package hanging off the ring. It could be either, depending on how much capacity Qualcomm wants to put on the die for these functions.
Moving up to a higher level, this is what the Amberwing system on chip looks like:
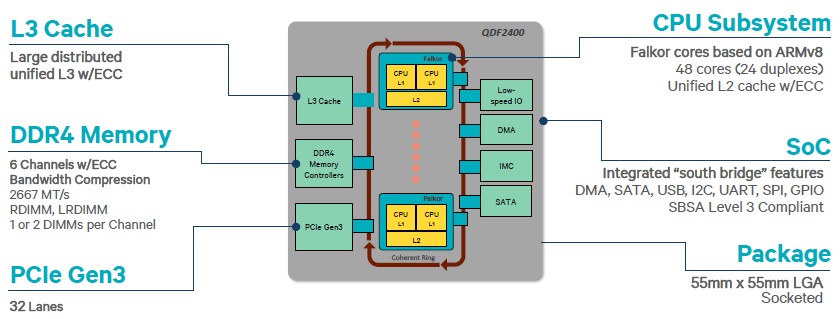
The chip has six DDR4 memory controllers, which top out at 2.67 GHz memory speeds like the more recent X86 server chips from Intel and AMD. Server makers can hang one or two memory sticks off each channel, for a maximum of a dozen slots per socket and, using 64 GB memory sticks that are typically the top end devices customers will buy, that works out to 768 GB per socket, the same as Intel’s Skylake Xeons. AMD has eight DDR4 controllers per socket on the Epyc processors and can hit 1 TB of capacity using 64 GB sticks and two sticks per channel, so it has won on memory.
The Centriq 2400 chip has 32 lanes of PCI-Express 3.0 peripheral capacity, and that probably means it has two controllers with 16 lanes each. Both Intel and AMD have more I/O per socket, with Skylake having 40 lanes of PCI-Express 3.0 and Epyc having a stunning 128 lanes in a single socket configuration and the same in a two-socket setup. The southbridge portion of the Centriq 2400 has DMA, SATA, USB, and other ARM-style I/O controllers. We do not see integrated Ethernet controllers on the SoC, but that does not mean that they are not in the design.
The whole shebang will fit into a CPU package that measures 55 millimeters by 55 millimeters, and it will come in an LGA socket like many server chips do and will not be soldered to the motherboard as is often done with processors used in mobile devices.
The one thing that the Amberwing SoC does not have is support for NUMA clustering across multiple processors. Like AMD, Qualcomm thinks that the cloud and hyperscale customers that it is chasing want to minimize the number of sockets in their machines and reduce the complexity of their nodes and the software that makes use of them. Having 48 full cores makes the Centriq 2400 perhaps a more deterministic chip than a machine that has SMT thread virtualization. Interestingly, Qualcomm has not added the NUMA-like partitioning feature that spans all of the cores on a single socket and snaps it in half to create two virtual nodes within a socket, as Intel has done with the Broadwell and now Skylake Xeons to boost their performance on certain workloads.
So for the moment, there is no NUMA scaling up or down for the Centriq line, but this could change if customers want fatter shared memory. This may not be necessary for a lot of cloud, hyperscale, and HPC workloads. But we still expect that Qualcomm will eventually offer a two-socket NUMA setup and maybe even go as high as four or eight sockets to compete toe-to-toe and node-for-node with Intel. For all we know, these features are dormant in the current design, waiting to be activated. (The designation 2400 seems to imply two sockets, but it might have more to do with the 24 chiplets on the die.)
The Centriq 2400 chip is currently sampling to key early adopter customers, and it is running various Linux flavors as well as an internal version of Windows Server that Microsoft has ported to the ARM architecture for its own purposes on the Azure public cloud. The Centriq 2400 is on track for production shipments in the fourth quarter of this year, says Bhandarkar.
By waiting for 10 nanometer processes to come to market and jumping ahead on these, by not trying to commercialize its earlier development platform, and by lining up Microsoft as a customer and getting it to port Windows Server to its Centriq 2400 chip, Qualcomm has exhibited the patience necessary to build the foundation of an ARM server business. It would have been better, of course, to do this long before AMD put its Epyc X86 server chips into the field. But we think there is still enough clamoring for an alternative to Intel’s Xeon chips – just for the sake of some technical and economic competition – that ARM servers still have a chance to get a slice of the datacenter. It will come down to feeds, speeds, slots, watts, and bucks.

Why TSMC Did A $100 Billion Deal With Trump On US Chip Manufacturing
All presidents of these United States have the bully pulpit from which to lecture the American people and, for the past century, the rest of the world about how the global economy and culture should work. Donald Trump has certainly used this pulpit in his first and now second terms …
India Declares CPU Independence With Aum HPC Processor
At the moment, the most powerful Arm processor on the planet is the 48-core A64FX processor from Fujitsu, which was created as the heavily vectored compute engine for the “Fugaku” supercomputer at RIKEN Lab in Japan. Nvidia is getting ready to ship its 72-core “Grace” Arm CPU, which has yet …

The Other Way To Bring Arm CPUs To Servers
There are at least two – and possibly more – paths to make Arm processors competitive with the Intel and now AMD X86 incumbent processors in the datacenter. The first path, and the one taken by most of the Arm collective to date, is to create a better CPU based …
“This is about the same frequency as the top bin Skylake part, which has 28 cores, can do, but then again, that Intel core has two 512-bit wide AVX-512 units to do floating point operations. ”
Intel has AVX512 units but they are badly brokes, so AMD can match them with only 128b units. So this might not be problem. 😉
I do not think that Intel’s AVX 512 are badly broken it’s just that they drink the juice when used while AMD’s AVX 128 is big enough and AMD saves CPU die space and power by going with the more reasonable 128bit AVX units as most server workloads do not need powerful AVX units. And AMD has its Vega GPUs with their compute oriented micro-arch. So the Vega 10 micro-arch with the full compute/shader complement as seen with the Vega FE/Vega 64 designs made into some Radeon Pro WX SKUs(With the Better Pro Drivers) will be used to complement any Epyc SKUs that also need some FP power for HPC workloads. This using of smaller AVX units for the first Zen Micro-Architecture iteration was intentional on AMD’s part with AMD knowing full well that it has its GPU IP to call on for any heavy FP workload lifting for any Epyc/Vega customers that need to run HPC oriented workloads.
What the press has still not queried AMD enough on is any direct attached Epyc CPU to Vega GPU usage over the Infinity Fabric Protocol rather that using the PCIe Protocol. And I distinctly remember hearing that spoken about on that video where AMD was doing the seismic workload comparison between Epyc and the Xeon competition at that trade event. So with the Infinity Fabric AMD has that, similar for Nvidia’s NVLink, functionality built into AMD’s Epyc CPUs and Vega GPUs for that sort of interfacing! And that also applies to any Vega GPU to Vega GPU interfacing via the Infinity Fabric communication and control protocol. So there is some new implications for those Dual GPU SKUs on a single PCIe card designs that AMD is so fond of creating after it has released the single GPU die GPU SKUs.
AMD’s past Dual GPU/Single PCIe card designs tended to rely on Drivers(“Cross Fire”) in order for the Dual GPUs to communicate across the PCIe card, and this “Cross Fire” was/is not known to have a very efficient scaling for any Dual GPU configurations(Dual GPUs on a single PCIe Card or dual GPUs on separate PCIe cards). So the implications of the Vega GPU Micro-Architecture supporting that Infinity Fabric IP points to AMD being able to create some Dual GPU/Single PCIe card designs that, like the Epyc Multi-Zeppelin die CPU configurations, can see Dual GPUs wired together on that single PCIe card in a manner such that they appear as a single logical much larger GPU to the software because the Dual Vega Die’s can, via the Infinity Fabric IP, be made to scale like the Epyc/Zeppelin CPU SKUs do, without and Infinity Fabric Based GPU SKUs having to use that inefficient Driver Based Cross-Fire software/Driver based solution.
This type of usage with any Vega Infinity Fabric IP for Multi-GPUs on a single PCIe card presages the Navi designs that will take that modular/scalable approach to the next level. So we can see how that Infinity Fabric will play a primary role going forward for all of AMD’s Epyc CPU and Vega/Newer GPU designs.
AMD’s EPYC CPU SKUs do not really need any larger AVX capability as that’s available on its Vega based GPU accelerator SKUs for any Epyc clients that need FP horsepower for HPC workloads.
If they really want this to find a niche, they need to put these processors in the hands of as many system programmers, application developers and power users as possible and make sure mainline Linux support it perfectly.
Mainline Linux already supports it.
I proposed ARM Server beta validation program in 2012 cross practice and vertically multidisciplinary in use make up. That effort placed investment expense across licensee offering’s with ARM Holdings plc for which there was considerable political kick back by some in ARM Holdings, and licensees who presumed their first mover advantage. QCOM is clearly not first mover but follower on any competitive advantage observation and learning curve might determine.
ARM Server vendors themselves see commercial cloud as the primary target on specific application loads and beyond APM and Calxeda were loath to experiment. broadly. There’s no sense the need for market force fueling competitive mass and leverage.
ARM Holding’s answer is cloud timeshare which is available on whose hardware I’m nut sure currently.
Pursuant Linux, Linaro’s answer in relation too competing in Intel time is oh so slow.
Mike Bruzzone, Camp Marketing
Tim,
On paper the new cpu looks good, but any single node / cluster tests and benchmarks did they perform?
– sqlite / relational database
– compress/uncompress files
– compile Linux kernel
– Blender
– Apache Spark
– docker load
– GIS
– Python / R
> “on the order of 3 teraflops like the Skylake can deliver per socket.”
Mmmh, really? Which SKU?
Math error, ironically. But fixed now.