

For years, researchers have been trying to figure out how the human brain organizes language – what happens in the brain when a person is presented with a word or an image. The work has academic rewards of its own, given the ongoing push by researchers to better understand the myriad ways in which the human brain works.
At the same time, ongoing studies can help doctors and scientists learn how to better treat people with aphasia or other brain disorders caused by strokes, tumors or trauma that impair a person’s ability to communicate – to speak, read, write and listen.
Tom Mitchell, the E. Fredkin University professor at Carnegie Mellon University who helps lead a neurosemantics research team, for the past several years has been marrying brain imaging technologies like functional MRI (fMRI) and magnetoencephalography (MEG) with machine learning techniques to develop models for better learning how the brain understands what it reads and sees and to answer an array of questions that cascade from that – including whether neural representations are similar from one person to another, if anything changes depending on language and how the brain handles not only single words but adjective-noun combinations, verbs, phrases and full sentences. In addition, they’re developing computational models for predicting the neural activity on the brain by words and phrases.
At The Next Platform, we’ve talked about the use of machine learning in brain research. In the end, what Mitchell and his team are trying to do is unlock the mystery of how the brain interprets what it reads, sees and hears – essentially the algorithms it uses to understand and process language.
“How does neural activity encode word meaning?” he asked during a webinar on the subject this week. “If I say to you ‘coffee’ and I say to you ‘baseball,’ it’s the same brain but different patterns of neural activity in your brain as you think about [the words]. What are the patterns? How can we identify what word is being thought of?”
In a brisk talk, Mitchell walked through steps researchers have taken down this path to answer the questions put before them, and then the question that arose from those answers. They first used fMRI to show reactions in the brain when thinking about different words, like “bottle” or “hammer,” or by seeing images. Then they trained a classifier using these fMRI brain images, enabling it to determine which word the person is thinking of. The classier becomes a “virtual sensor,” able to “observe neural activity and figure out what they’re thinking of,” Mitchell said.
Through that, researchers have been able to determine that the neural representations in the brain of words are similar from one person to another, from one language to another, such as Portuguese and English, and between words and pictures. Concrete nouns and emotional nouns – such as “anxiety” and “fear” – were easier to decode than abstract nouns or verbs (unless the verbs were placed in context, such as doctors “cut” into a patient). The next question was about developing a predictive model using machine learning.
“Can we build a computational model and … give it any noun and it would predict neural activity?” he said.
Initially it was a two-part process. Give the computer the word “celery,” and the first step it would take would be to pour through a trillion-word collection of text from the web and see how often the word is used with an array of verbs, from “eat” to “drive.” The next step is predicting the neural activity in each of the 20,000 locations in the brain when the word is used with any of 25 verbs. For “celery,” that ranges from the most likely verbs like “eat” and “taste” to the least likely, “break” and “ride.” For “airplane,” the most likely was “ride,” the least likely was “manipulate.”
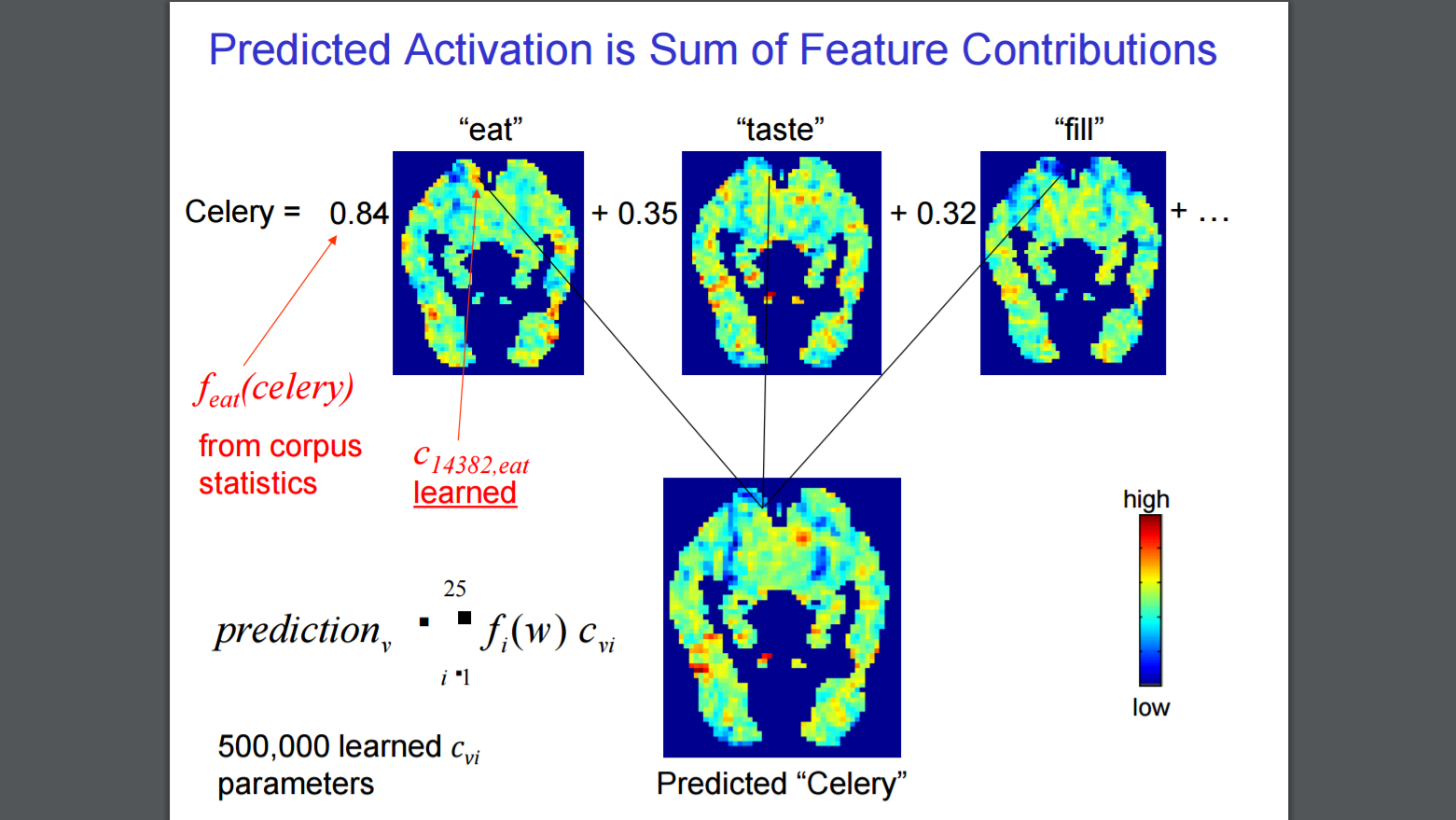
To test how the predictive model worked, the researchers trained the model on 58 words, but left out “celery” and “airplane,” and then have the model predict for the two words. The images generated weren’t perfect, but showed promise, Mitchell said. In another test, they left the two words out while training the model, then present the words to the system and have it decide which one is “celery” and which is “airplane.” The model got it right 79 percent of the time – three out of four times, it could distinguish the brain images of two words it hadn’t seen before. What the test showed was that the neural encodings for nouns are not random but are composed, and in a structure that built from more primitive semantics.
From there the testing grew to replacing the refined corpus features that included word and verb co-occurences with 218 20 Questions-like questions – such as, Is it heavy? Is it bigger than a car? Can it swim? Does it use electricity? A PhD. student then decided that rather than train a model for each person using fMRI data, it’d be better to train a model using data from 20 fMRI sessions at the same time. The student used the canonical correlation analysis and the 218 questions to create an even more accurate model and the ability to bring even more data into the equation.
Mitchell and his researchers also are using machine learning techniques to study the brain’s ability to comprehend words, which brings the MEG brain imaging into the mix. The fMRI takes an image about once a second, which is too slow. Most people comprehend a word in 400 milliseconds; the MEG takes an image every 1 millisecond. What they wanted to see was how neural activity runs over time.
Another PhD. student divided the brain into 72 regions and trained some 1 million classifiers to look at different parts of the brain through a 100-milliscond time window. He then applied the 218 question semantic features, tried all time windows in all 72 regions of the brain. What resulted was video-like imaging showing that the semantic features trickle through different parts of the brain over time – some appearing earlier than others, some last longer, some disappear while others pop up in different parts of the brain. Information is flowing around the brain.
Below are what the brain images look like at 100 milliseconds, 250 milliseconds and 400 milliseconds:
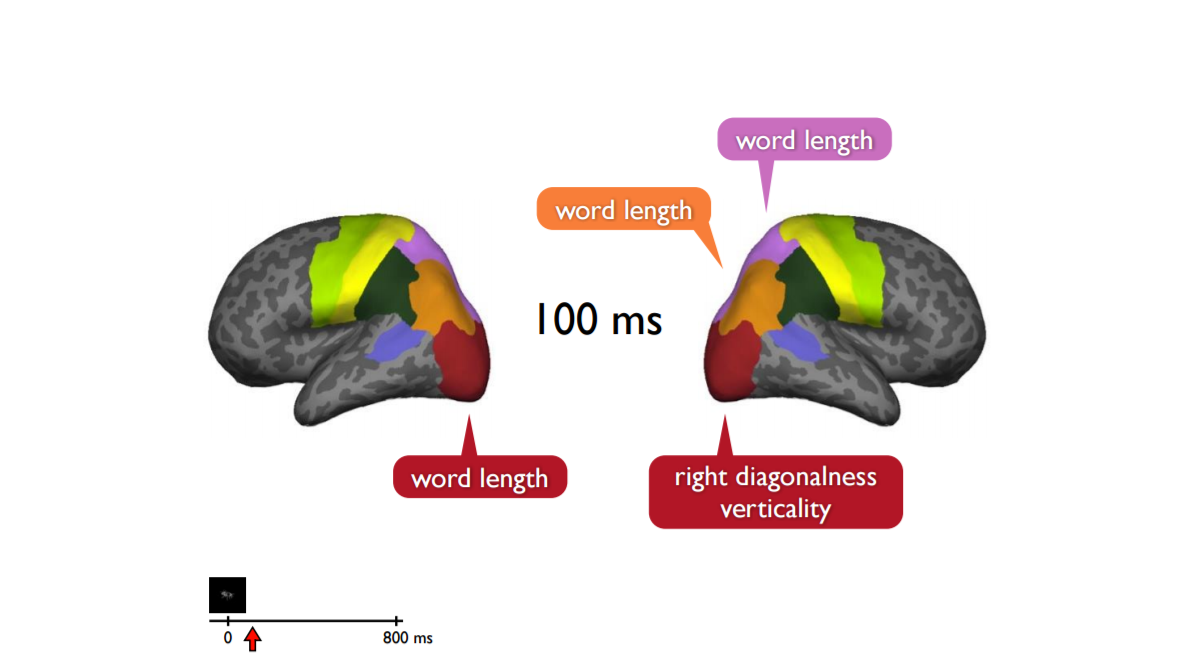
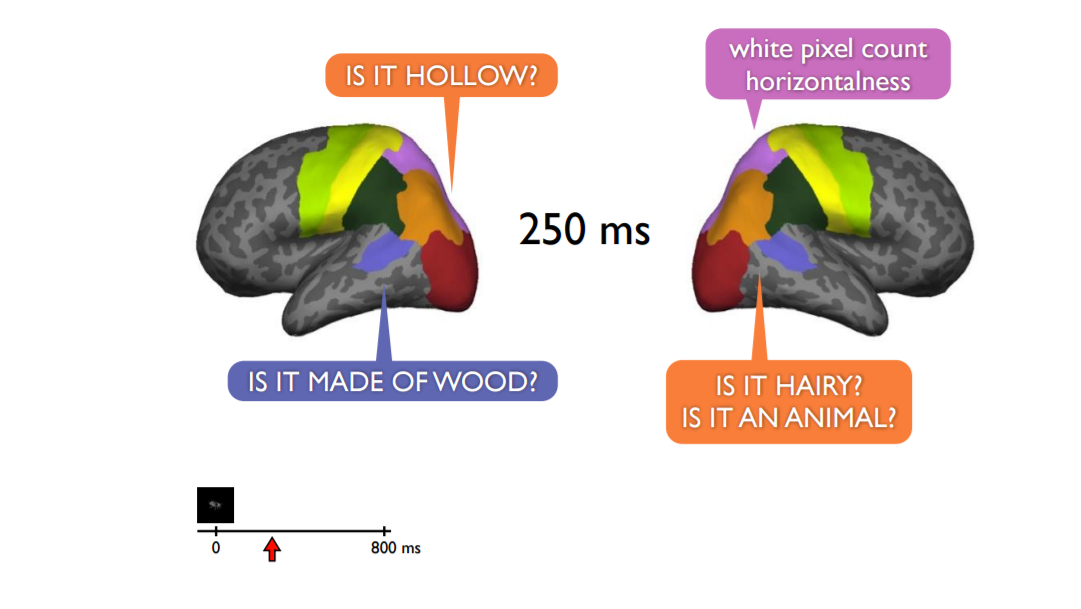
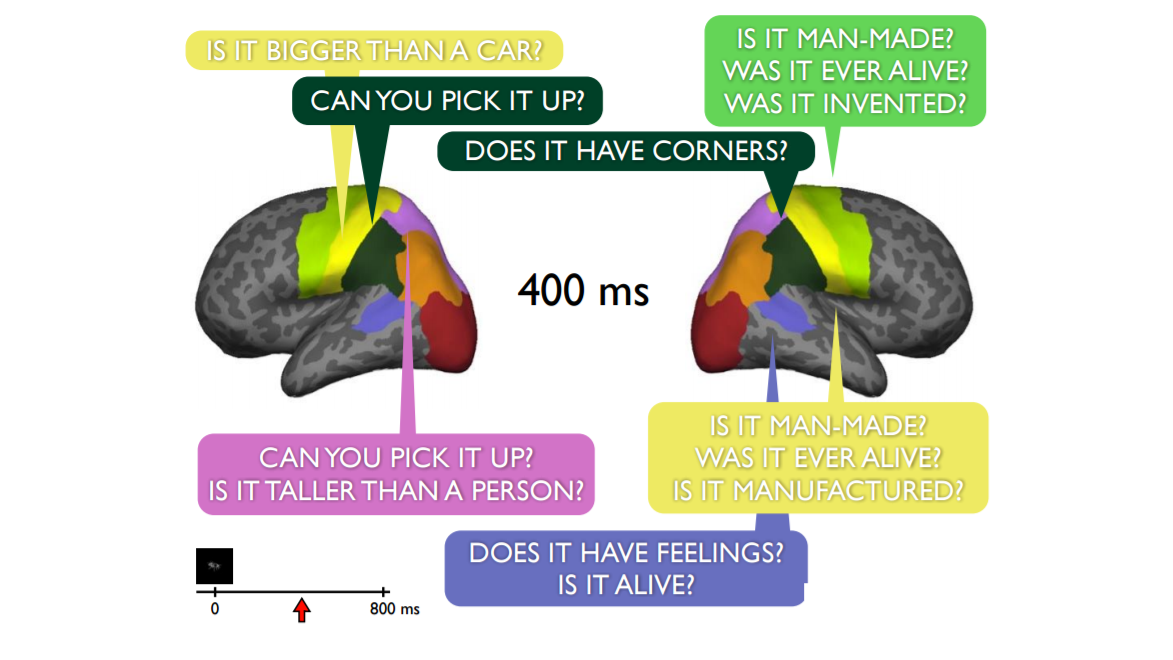
The researchers learned that the 20 most accurately decoded semantic features of the 218 involved size (Is it bigger than a loaf of bread?), manipulabilty (Can you pick it up?), animacy (Is it man-made?) and shelter (Can it keep you dry?)
Now researchers are moving beyond words and phrases and are using machine learning and brain imaging as people read chapters in books, finding the computational models they’re creating can be as much as 75 percent accurate in predicting neural activity. In addition, they’re finding that as the person reads a sentence, the brain reactivates code for certain words at multiple times. It’s all part of the process, Mitchell said.
“We don’t know everything about how the brain decodes words, but we know much more than we did,” he said.

Be the first to comment