

The last two years have delivered a new wave of deep learning architectures designed specifically for tackling both training and inference sides of neural networks. We have covered many of them extensively, but only a few have seen major investment or acquisition—the most notable of which was Nervana Systems over a year ago.
Among the string of neural network chip startups, Graphcore stood out with its manycore approach to handling both training and inference on the same manycore chip. We described the hardware architecture in detail back in March and while its over $30 million in funding from a Series A is not news, it was made public today that Dell’s investment arm was a major funding force behind the company. Dell Technologies Capital, along with Bosch, Samsung, and other investors have pushed Graphcore past the $32 million mark. Of the Dell angle, Graphcore CEO and co-founder Nigel Toon says they will have deeper reach via Dell’s OEM, channel and product integration prowess.
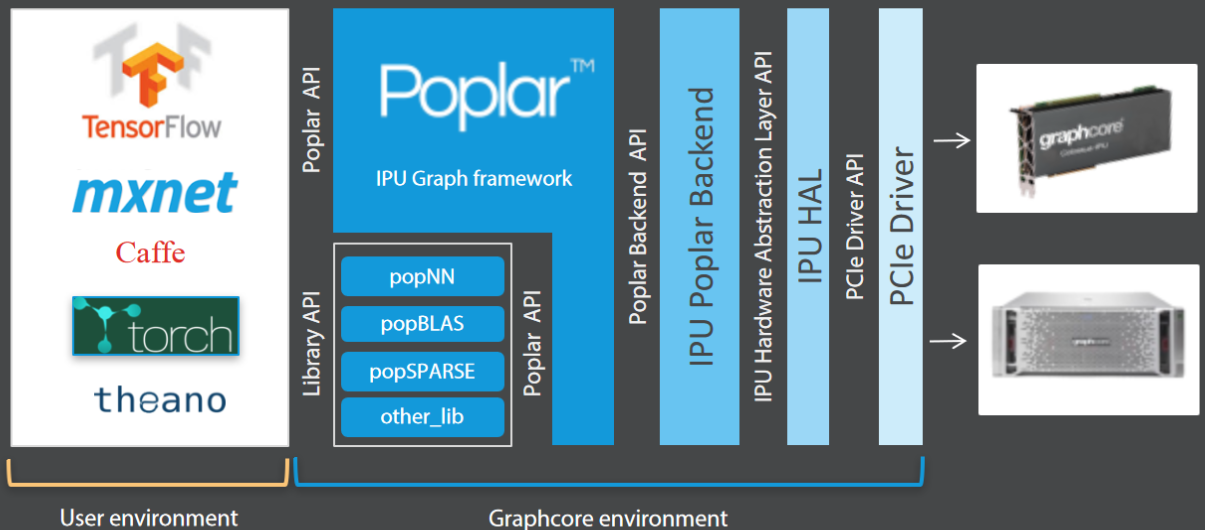
In light of this news today, we wanted to go back to the initial hardware deep dive we provided in March and look at the other aspect of Graphcore’s offering—the software stack. The custom-developed IPU processors at the heart of Graphcore’s PCIe based hardware have a heady task for both training and inference on the same device.
As Toon reminds The Next Platform, deep learning frameworks are capturing a knowledge model from data and the best way to represent those features and represents is via a computational graph. At their core, all machine learning frameworks are, at some level, boiling everything down to a graph—vertices and edges that can represent correlations and connections between features. Those might be representing a connection as a single scalar weight, a matrix, or a tensor that describes a relationship or set of features. Accordingly, making that graph a more explicit representation of this concept with its own hardware device that mirrors the format makes sense—it becomes a matter of taking the deep learning framework and “exploding” it out to show all the vertices and edges then partitioning the graph up to allow for mapping the problem to the many cores on a chip and controlling the communication between those processors so they have the data they need when they need it. Simple, right?
As it turns out, this was a thorny problem at first, but Graphcore slowly built out this explosion, reduction, mapping, and communication problem via the Poplar software framework.
Using Poplar on Graphcore’s IPU hardware, which is a PCIe-based 16-processor element, requires a developer to start in TensorFlow (the team is working on extending library and support mechanisms to other frameworks) then build the description of the neural network they want to train (setting parameters, etc). This is parsed to Poplar, which inserts one of many library elements Graphcore has developed (similar to the cuDNN elements Nvidia has for its GPUs) and it inserts these (for example, convolutions or different primitives to replace the high level description that was made in TensorFlow). Popular then does its “exploding” trick by expanding that into a very full and complex graph with all the vertices and edges exposed. The software maps and partitions that across the processing elements and communication resources inside so it can work the graph and creates a program that is fed to the processors.
One of the aspects of Graphcore’s chip that made it interesting initially was that training and inference could be done efficiently on the same piece of hardware. Toon tells us there is actually nothing about this that involved extensive software work necessarily—it is rather a function of taking a graph approach to the deep neural network problem. “Learning is building a graph and optimizing on it to create the right answers, predictions, inference, and judgements and these are all just different optimization tasks across a graph—they’re fundamentally the same compute. They might take different amounts of computation to perform, but overall, they’re very similar. If I have a piece of compute hardware that can connect together and use a number of processors to speed training, then at a different time I can use other processors on their own for deployment or inference,” Toon explains. “As long as the processor is designed in a way that doesn’t need to be tweaked and controlled in specific ways to get performance, this is possible.”
What is difficult is wrangling change and maintenance across the many libraries they currently support and those that are coming down the pike as new neural network approaches emerge. Toon says the major frameworks are mostly just an API-level problem, but the team will need to do routine, in-depth maintenance on the new and future libraries.
The company will have a cloud-based version of the Graphcore stack available sometime this year. We’ll check in with any early use cases we can scare up when that happens to see what, if any difference, this tailored processing environment can provide over GPU, FPGA, and even those few CPU-only training plus inference workloads.


Next-Gen Insurers Are Going to Need (Way) More AI Horsepower
While involving AI/ML in the complex process of insurance claims now might be piecemeal, the future is bright for insurers to speed time to claim resolution by using image-based data and machine learning models to understand the scope of damage to vehicles or eventually, entire geographic regions. Tractable, a UK-based …
Graphcore Goes Full 3D With AI Chips
The 3D stacking of chips has been the subject of much speculation and innovation in the past decade, and we will be the first to admit that we have been mostly thinking about this as a way to cram more capacity into a given compute engine while at the same …

Graphcore Right on the Money in First MLPerf Appearance
When it comes to a silicon startup bringing a product to market in a tough competitive landscape, nothing is easy. The list of challenges is long but to be taken seriously against the incumbents, a strong MLperf showing is now paramount. As usual, Nvidia and Google swept the MLPerf results …
Be the first to comment