

Scaling the performance of machine learning frameworks so they can train larger neural networks – or so the same training a lot faster – has meant that the hyperscalers of the world who are essentially creating this technology have had to rely on increasingly beefy compute nodes, these days almost universally augmented with GPUs.
There is a healthy rivalry between the hyperscalers over who has the best machine learning framework and the co-designed iron to take the best advantage of its capabilities. At its F8 developer conference, Facebook not only rolled out a significantly tweaked variant of the open source Caffe framework that comes out of the University of California at Berkeley, but it also turned around and open sourced its enhancements and packaged the whole shebang up as the Caffe2 framework, distinct from the original Caffe project that was developed by Yangqing Jia when he was a student at Berkeley and that was popular for image classification applications.
Like Caffe, the new Caffe2 is written in C++ and has interfaces to both Python and MATLAB, and both support OpenMP parallel interfaces for CPUs and CUDA parallel interfaces for offloading model training to Nvidia GPUs. Both iterations of the Caffe framework have a slew of pretrained models available and they support convolutional and recurrent neural networks, but Caffe was stuck in single-node mode. So a training model could only be as large as the memory in the CPUs and GPUs in the box and could only be chewed on as fast as the CPU and GPU motors that could be stuffed in that single box could be handled. Back in October 2015, Intel did a fork of the Caffe framework, tuning up its math libraries so they could run in multi-node mode on “Haswell” Xeon E5 and “Knights Landing” Xeon Phi processors, but this was never intended for production use.
The tweaked Intel Math Kernel Libraries were commercialized as IMKL 2017 back in September 2016, and the scale out was performed by a tweaked version of Intel’s MPI library, which implements the Message Passing Interface (MPI) distributed memory and compute protocol that is commonly used in traditional simulation and modeling applications in HPC centers. On its tests, Intel was able to scale its forked Caffe running on top of MPI up to 64 nodes, all based on two-socket servers using 14-core Xeon E5-2697 v3 processors, taking the time to run an image recognition neural network training run from 150 hours on a single CPU down to 5.1 hours on a 64-node cluster. (This was using the ImageNet image library training on the AlexNet neural network.)
Facebook, Nvidia, and Intel have taken the next step and collaborated to make multi-node support part and parcel of the Caffe2 framework. Our first thought was that Facebook was doing what Intel did, which was to take the MPI protocol from the HPC simulation realm and bring it on over to the hyperscale machine learning realm. Others, including D.K. Panda of Ohio State University, have similarly extended Caffe with MPI. Oak Ridge National Laboratory has similarly added MPI to Caffe and scaled it across 18,688 Tesla K20X GPUs to run an ensemble of neural networks at the same time, on top of InfiniBand, much as the HPC center runs multiple iterations of weather models with slightly different starting conditions to do large-scale climate forecasts.
As it turns out, the Caffe2 framework is going multi-node in a more low level way, Ian Buck, vice president of accelerated computing at Nvidia, tells The Next Platform. “Facebook wrote its own custom communication layer using InfiniBand Verbs, which is lower level than MPI. They did not use MPI. It is not a shared memory management layer, just a communication layer to distribute the training over multiple nodes.”
While Facebook worked on a communication layer that ran over InfiniBand, it has worked very tightly with Intel and Nvidia to tune up Caffe2 for both the latest Xeon and Tesla processors for both machine learning training and inference workloads. The training is important mostly for the Teslas and the inference work can be done by either CPUs or GPUs. On the Nvidia GPUs, Caffe2 makes use the latest deep learning libraries available from the graphics chip maker, including cuDNN, cuBLAS, and NCCL, which are respectively the CUDA deep neural network library, the CUDA implementation of the Basic Linear Algebra Subroutines popularly used in both HPC simulation and machine learning, and the Nvidia Collective Communications Library, which Nvidia created and open sourced to allow MPI-style (but not MPI-derived) collective communications across multiple GPUs within a single node.
Nvidia took the new Caffe2 framework out for a spin on its DGX-1 system, which is a two-socket Xeon server with eight of its “Pascal” Tesla P100 GPU accelerators on board. The Pascal accelerators are lashed together coherently using the NVLink interconnect and protocol, and the cluster of GPUs is linked to the CPUs over PCI-Express switches in this box. As you can see from the chart below, the Caffe2 framework performance on the three different image classification neural networks tested were linear:
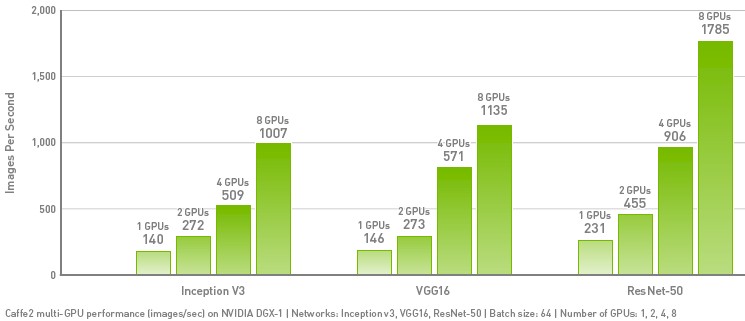
Of course, Facebook does not use the DGX-1 server and makes its own iron, including the original “Big Sur” hybrid CPU-GPU server from late 2015, which crammed two Xeon E5 processors and eight Tesla K80 co-processors into a single chassis, and the new “Big Basin” machine unveiled at the Open Compute Summit earlier this year, which has eight of the Tesla P100 accelerators coupled together with NVLink and four PCI-Express switches that link the GPU cluster to an adjacent two-socket server as well as to each other above and beyond the NVLink ports. Big Basin supports multiple topologies inside the box, and as it turns out, is equipped with InfiniBand interconnect to scale across multiple boxes – something we did not know back in March.
In its own tests, Facebook scaled up a cluster of eight of the Big Basin machines using what we presume was 100 Gb/sec InfiniBand and brought together the aggregate 64 Tesla P100 accelerators together to run the Caffe2 framework against its own image recognition workloads. In that test, those 64 Tesla P100s were able to analyze and qualify 57X as many images as a single Tesla P100 card, which is pretty close to linear scaling. It is unclear how fast the scaling drops off after 64 accelerators, but odds are there are network contention issues as the cluster of machines gets larger. (This could be mitigated a bit by a move to 200 Gb/sec InfiniBand later this year when it becomes available from Mellanox Technology.) Our point is that this eight-node scalability is now baked into Caffe2 today and it is tied to InfiniBand, not using MPI and not using the more pervasive Ethernet that hyperscalers by far prefer.
Intel is not talking at all about scale across nodes for machine learning training, but it is obviously keen on demonstrating that the Caffe2 framework plus its tweaked math kernel libraries makes it a good fit for machine learning inference workloads. (Facebook is widely believed to be using GPUs to do inference, but for all we know it uses a mix of CPUs and GPUs, depending on the load on its social network.)
To show off a bit on its collaboration work with Facebook at the F8 event, Intel trotted out some benchmarks showing the inference performance of the AlexNet neural network running on Caffe2 using the latest “Broadwell” Xeon E5-2699 processors. The machine that the two tested pitted the Intel MKL and Eigen BLAS libraries against each other on a two-socket box with a total of 44 cores running at 2.2 GHz and 128 GB of DDR4 memory running at 2.13 GHz; the system ran Caffe2 on top of the CentOS 7.3 distribution of Linux. Here is how they stacked up;
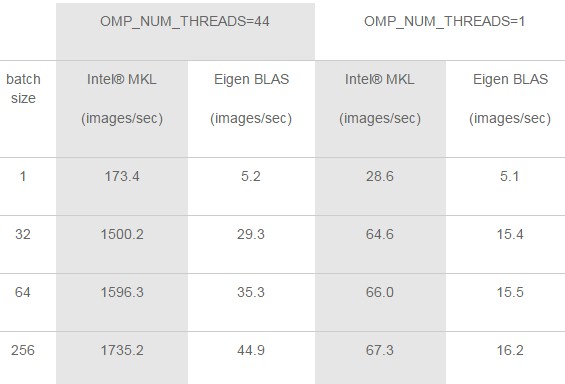
Obviously, the Intel BLAS libraries scale a lot better as the image batch size increases and just has a lot more oomph on the same iron regardless. Intel is looking ahead to later this year, when the “Skylake” Xeon processors come to market with more cores than the Broadwell Xeons – the roadmaps we published back in May 2015 said 28 cores for the top bin Skylake Xeon, but we are hearing murmurs that it might have been jacked up to 32 cores – and when they will also get other tweaks that will help with inference performance. Specifically, Andres Rodrigues, senior principal engineer in the AI Products Group at Intel, said that Skylake would have a 512-bit wide Fused Multiply Add (FMA) unit that is part of the expected AVX-512 vector engine. These are twice as wide as the 256-bit AVX2 vectors used in the Haswell and Broadwell. The Skylakes will also support larger L2 caches on each core and support faster DDR4 memory, which should also boost machine learning inference performance. All of these enhancements would also help boost the performance of machine learning training on Xeons, but this work is done on GPUs and possibly someday on parallel Xeon Phi processors in the “Knights Mill” processor with mixed precision and then the “Knights Crest” follow-on that will add in technology from its Nervana Systems acquisition.
While Facebook has chosen to write its own communication layer based on InfiniBand for Caffe2, there is no reason why Intel can’t donate its MPI work to the cause and add it to the Caffe2 project and there is no reason why it cannot tweak that low-level communication protocol to work atop its own Omni-Path InfiniBand derivative as well. It will be interesting to see what Intel does here.


Intel Decides To Engineer Its Fab-Filled Future After All
Newly anointed Intel chief executive officer Pat Gelsinger held the coming out party for his strategy to get the world’s largest chip manufacturer and designer back on track, called “Intel Unleashed: Engineering The Future,” on Tuesday after the market closed. It was a strange echo of an essay we wrote …

Pandemic Compute Needs Drive Intel’s Data Center Group
The first half of last year was relatively weak for Intel’s Data Center Group last year, but despite the coronavirus pandemic – and in some cases, we think because of it – the world’s largest datacenter chip manufacturer is looking to not only have a good first quarter, as it …

With Cloud HPC Toolkit, Google Pursues HPC, Intel Pushes OneAPI
The people running Google Cloud can see the tides of HPC changing and know that, as we discussed only a few months ago, there is a fairly good chance that more HPC workloads will move to cloud builders over time as their sheer scale increasingly dictates future chip and system …
Re use of verbs directly vs use of MPI. The released version of caffe2 in github use support for MPI but has no code that directly uses IB verbs (grep didn’t turn up a single ibv_* call).
Perhaps the more optimized version not using MPI is FB-internal only right now?
The NVIDIA graph looks exponential because the performance as a function of the number of GPUs is almost linear and the number of GPUs is doubling in each successive bar in the graph.
Is there a technical reason Facebook is using InfiniBand in Big Basin/Caffe2 instead of ethernet? Or are they interested in HPC/hyperscale convergence?
Regarding IB and no Ethernet: I’m one of the authors of said layer and can say it’s by no means tied to IB — in fact, we tried hard to make sure it is NOT tied to IB. The 57x weak scaling number we got by running our ResNet-50 example trainer using our TCP transport layer on 50GbE. It all depends on the size of the model (in case of ResNet, not big) and the bandwidth of your pipe, since most reductions can be executed during backprop (i.e. communication is free as long as GPUs are doing useful work).
Bill, you can find all ibv calls on in the Gloo repository (referenced as third party dependency for Caffe2) — see https://github.com/facebookincubator/gloo/tree/master/gloo/transport/ibverbs
“the Caffe2 framework performance on the three different image classification neural networks tested were better than linear and look to our eye to be going a bit exponential.”
That’s because with the bar chart doubling GPU count with each increment along x, and a linear y axis, you’ve effectively created a linear-log plot. Even sublinear scaling will appear “exponential.”
Really looking forward to seeing how Caffe2 goes.