

Intel has planted some solid stakes in the ground for the future of deep learning over the last month with its acquisition of deep learning chip startup, Nervana Systems, and most recently, mobile and embedded machine learning company, Movidius.
These new pieces will snap into Intel’s still-forming puzzle for capturing the supposed billion-plus dollar market ahead for deep learning, which is complemented by its own Knights Mill effort and software optimization work on machine learning codes and tooling. At the same time, just down the coast, Nvidia is firming up the market for its own GPU training and inference chips as well as its own hardware outfitted with the latest Pascal GPUs and requisite deep learning libraries.
While Intel’s efforts have garnered significant headlines recently with that surprising pair of acquisitions, a move which is pushing Nvidia harder to demonstrate GPU acceleration (thus far the dominant compute engine for model training) for deep learning, they still have some work to do to capture mindshare for this emerging market. Further complicating this is the fact that the last two years have brought a number of newcomers to the field—deep learning chip upstarts touting the idea that general purpose architectures (including GPUs) cannot compare to a low precision, fixed point, specialized approach. In fact, we could be moving into a “Cambrian explosion” for computer architecture — one that is brought about by the new requirements of deep learning. Assuming, of course, there are really enough applications and users in a short enough window that the chip startups don’t fall over waiting for their big bang.
Among the upstarts that fit the specialization bill for deep learning is Wave Computing, which in many ways could have served as a suitable acquisition target for an Intel (or other another party) over Nervana Systems. Although the execution and technology are different from Nervana, the fundamental belief that it is practical to do large-scale deep learning training on ultra-low precision hardware with low-level stochastic rounding and other techniques is the same. And while the company’s Jin Kim tells The Next Platform they see high value in their own technology for companies like Intel, the Nervana acquisition is actually a positive element for the field overall because it proves that there is a need for non-general purpose hardware for such a market.
One could make the argument that Intel was just as interested in Nervana for its Neon software framework as it was for the chip, but Wave Computing’s Kim says that there is another unmet need that has companies scrambling. “There are development boards and accelerator boards, but as we talk to people in the field they want a single system that is designed for the specific needs of deep learning.” Of course, something like this already exists in Nvidia’s DGX-1 appliance, which is outfitted with Pascal-generation GPUs and has all software ready to roll for both training and inference. However, Kim says that they have mastered both the hardware and software and can (in theory—they don’t yet have a DGX-1 appliance on hand) beat out Pascal with lower thermals and far faster training times. More on that in a moment; for now, however, the key point is this is one of the first systems to take on deep learning aside from DGX-1, but of course, it is based on a novel architecture.
The Wave Computing approach is based on a dataflow architecture via their DPU processing elements. Like Nervana, Wave has a highly scalable shared memory architecture (with hybrid memory cube or HMC) at the core. “We are both taking the perspective that there are some familiar characteristics of deep learning compute workloads—this means we can take advantage of the fact that these algorithms are resilient to noise and errors. That, coupled with data parallelism and the opportunity to reuse data are just a few things that give this an advantage over general purpose hardware.”
Instead of selling accelerator boards, Wave is focused on delivering a full system for both training and inference. This is designed as what Kim calls a “plug and play node in a datacenter network with native support of TensorFlow as well as Hadoop, Yarn, Spark, and Kafka.” The systems will come in 1U and 3U configurations starting in Q2 of 2017. They have a 28nm test chip that was delivered two years ago they have been validating with, but the forthcoming 16nm FinFET chips, which are being taped out now with delivery late in the year will offer a sizable boost. The first 28nm implementation could put 16,000 of the simple processing elements on a piece of silicon, but with the 16nm FinFET chips coming soon, they can scale up to 64,000, Kim says. These will first be available via a private cloud to foster early users who want to experiment before the systems become available. “Our business model is not to deliver services via our own cloud, but demand is high and private cloud offers a faster option for those who want early access.”
So, just what is inside the dataflow architecture (DPU) chips and the systems?

Get a load of all of that memory–and the all-important memory bandwidth capabilities here. This is actually just as (if not more) important than the dataflow processing elements themselves since, after all, even the cleverest of processors is useless without a way to move data. Of course, this is just moving instructions for the most part–another key feature that fits the bill for deep learning workloads where the reuse of data can lead to significant boosts in efficiency.
Each of the 8-bit RISC-oriented processors has an instruction RAM and local registers to hold on to a lot of the memory data being operated on locally so data is not being moved, rather, instructions are. There is an instruction queue with the basics (multiply, add, shifting, etc.). Each of the processing elements group together into a cluster with 16 of the elements sharing the arithmetic units (each has 2). These clusters make up the core compute engines and can be teamed together to do 8-bit work alone or with up to 64 bits together (variable length arithmetic).
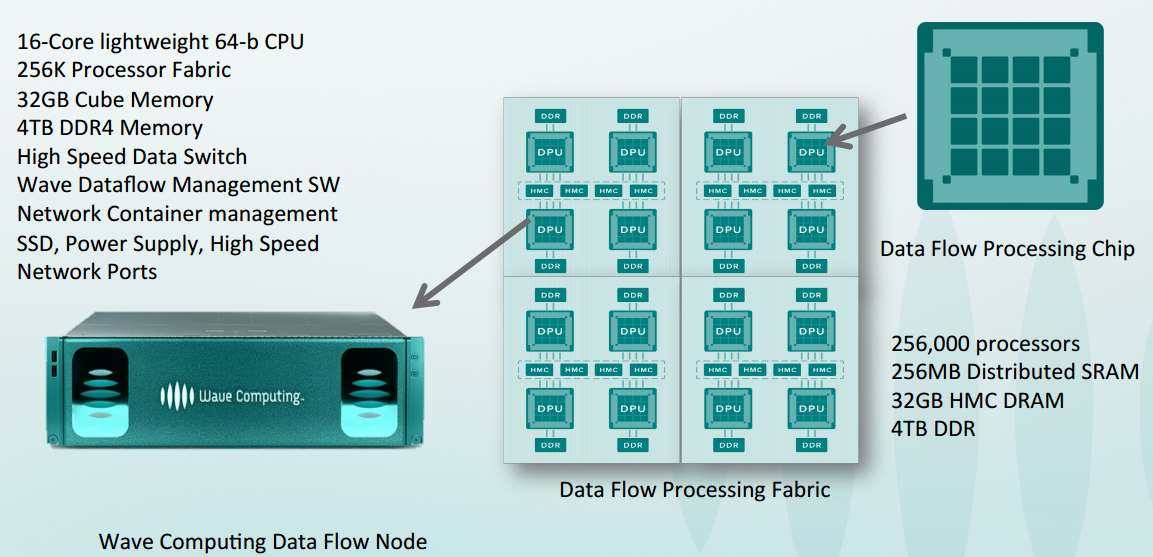
The general idea is simple. Each of the DPUs are grouped together and can do multiple tasks. It is a NIMD architecture (versus control flow) and can support very high memory bandwidth. The first generation chips ran between 6.7 GHz and 8 GHz and were in the 150 watt to 200 watt range but Kim did not comment on the next generation ones due this winter. Each of the dataflow processing units (DPUs) becomes part of a cluster. It is scheduled statically via a toolkit the team developed for tactical scheduling without running into memory consistency issues because it is clear which portion of the algorithms are running on specific parts of the DPU.
There are 24 “compute machines” per DPU and as you can see above, the architecture can support serious random access memory with the four HMC and DDR4 memory comprising the core fabric element that tiles these together. In the case of Wave’s 3U configuration, they can put 16 such machines together.
And of course, key to the difference between general purpose processors is the low precision, fixed point math capability. “We are focused on highly parallel operation on multiple threads at the processing element level. We are also focused on high memory bandwidth capabilities. This is real-time reconfigurable, so it is possible to get hardware support for stochastic rounding to do mixed precision math. That is on the right side of trends in deep learning toward low precision to save on memory bandwidth—as long as you can accumulate results at a higher precision, you do not lose accuracy,” Kim says.
“The whole idea is that this becomes a TensorFlow compute server node for the enterprise datacenter—all TensorFlow models work with minimal modification. Partitioning runs efficiently on a scalable dataflow architecture as well, so the entire system lets us take advantage of shared memory so we can scale better than GPUs and without CPU overheads.”
At the core of Wave’s approach is that one can use fixed point with stochastic rounding techniques and many small compute elements for high parallelism. “Using fixed point and low precision arithmetic, as long as you round carefully the convergence with floating point is virtually identical,” Kim says, pointing to research from IBM and Stanford, as seen below.
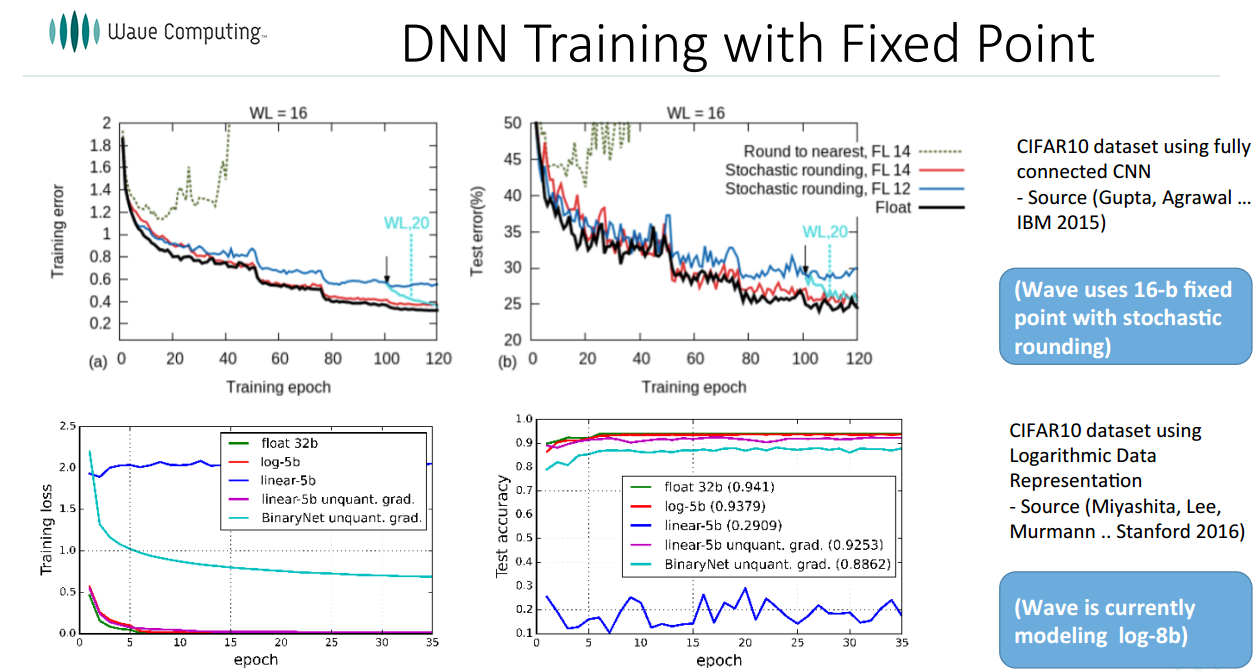
It cannot be too expensive to run inference on models, which is why work on deep compression (like this from Song Han at Stanford via the EIE effort) matters as well. The top green line that shoots up is using low precision, fixed point without clever rounding. This research is fed by a few years prior when people thought floating point was required. In fact, says Kim, if you do stochastic or logarithmic based rounding, training using fixed point is almost identical to floating point. See the bottom black line, which is floating point with red and blue as fixed.
In terms of performance at a system level, this is still anyone’s game since the DGX-1 appliances from Nvidia aren’t hitting many shelves in a way anyone will discuss yet. However, based on available data about the performance of the P100 inside Nvidia’s deep learning box and actual benchmarks on the Xeon, Wave has shared the following metrics.
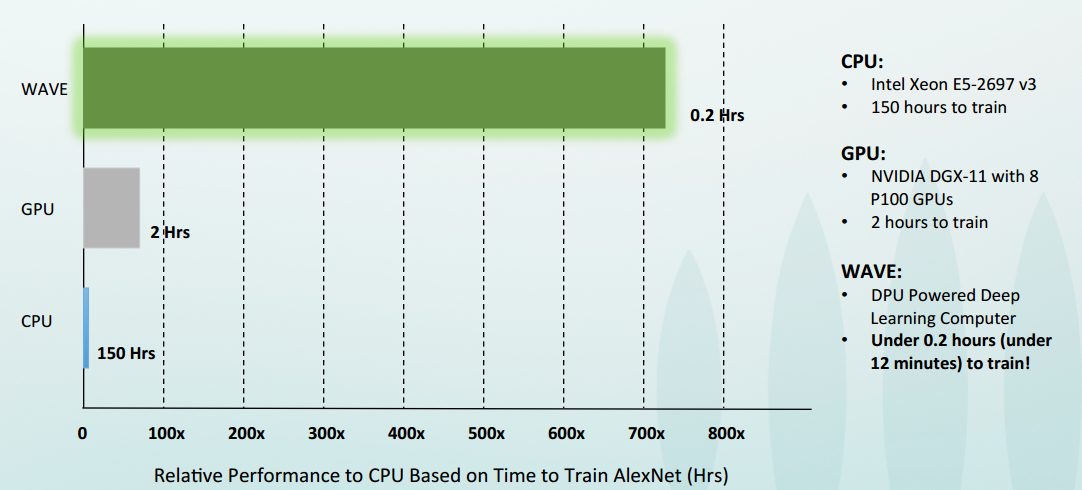
One can imagine a few possible outcomes for Wave Computing, the most likely of which is swift acquisition on the part of a large company looking for a systems hook for deep learning—one that can beat Nvidia on price and performance. Of course, it also has to have the requisite software stack in place as well, which is an area that Nvidia has been ahead with its own CUDA libraries to hook into most well-known deep learning frameworks.
Wave Computing’s system will be container based to support a microservice oriented architecture with an SDK based on TensorFlow for running and executing models (with a Python or C++ API for TensorFlow) as well as a low level SDK for large datacenters that want to support different languages. The goal, Kim says, is to make TensorFlow models run far faster out of the box with as much hidden away from the user as possible. This sounds a lot like the DGX-1 appliance, however, Kim says it will be competitively priced. Whether that means thousands less or at the same price, one cannot tell yet.
On that note, we should mention that Kim is not suggesting that this is a replacement for CPUs or GPUs for all users. “In some cases, the way TensorFlow partitions, some parts of the graph will run on the DPU, some on CPU, some on GPUs. The goal is accelerate with the best mix and match.” How that shapes into the systems people buy and how they’re implemented remains to be seen, but we expect that we will see someone snatch up Wave before the end of next year as the emphasis moves from a novel architecture and deep learning stack to putting that into practice in an actual system for real users.


Doing The Math On CPU-Native AI Inference
A number of chip companies — importantly Intel and IBM, but also the Arm collective and AMD — have come out recently with new CPU designs that feature native Artificial Intelligence (AI) and its related machine learning (ML). The need for math engines specifically designed to support machine learning algorithms, …
Intel Pits New Gaudi2 AI Training Engine Against Nvidia GPUs
Nvidia is not the only company that has created specialized compute units that are good at the matrix math and tensor processing that underpins AI training and that can be repurposed to run AI inference. Intel has acquired two such companies – Nervana Systems and quickly right after that Habana …
Google Stands Up Exascale TPUv4 Pods On The Cloud
It is Google I/O 2022 this week, among many other things, and we were hoping for an architectural deep dive on the TPUv4 matrix math engines that Google hinted about at last year’s I/O event. But, alas, no such luck. But the search engine and advertising giant, which also happens …
Interesting but you lost me there when it is TensorFlow only. No one is using TensorFlow besides google and deepmind (which has been forced by its parent company google to move to TensorFlow from Torch). I rather would hope they would support open platforms like Caffe and Torch or Theano. Other notes I have no one is using AlexNet anymore it is a tiny network so how does it perform with larget networks like VGG-16,-19 or Resnet-50,-101,152 these are big networks pushing current GPU architectures to the max in terms of memory consumption. Here the utility to go to lower precision would really pay off massively
Spark support is mentioned but without any details whatsoever. Is it only for accelerating Machine Learning or it’s more than that?
I’m not a hardware engineer but 6.7-8GHz on 28nm @ <200W seems too good to be true if all processors/DPU are active. Is it a confirmed number?