

To Patricia Harris – like most people in the rapidly changing worlds of IT and business – data is central to what she does. Data is what is driving innovation and business decisions, accelerating the development of products and services that quickly are finding their way into the hands of enterprises and consumers alike. It’s also the scaffolding on which hardware and software vendors alike now build the bulk of their offerings – architectures are designed to ensure that data can be collected, stored, and analyzed as quickly as possible, regardless of the amount that is being generated or where it’s created. It’s like what oil has been for more than a century, a generator of vast amounts of value across the entire economy.
“Much like oil, the value of the data comes from what you do with it, how you refine it,” Harris, vice president and head of global marketing of digital infrastructure for Hitachi Vantara, tells The Next Platform. “But that said, we really believe that data is the new, bigger or better version of oil. It is truly what makes the world go around right now. While oil is available in ever diminishing quantities, the data universe is huge. In fact, the unstructured data universe is absolutely huge. What is great about this – but also creating a really specific challenge – is that it’s growing exponentially.”
The focus on data has been going on for several years. The sheer amount of data being created is staggering with IDC look at 175 zettabytes in worldwide expected in 2025 and the data is no longer being created or access only in the datacenter. Data is increasingly being created, stored and accessed in the cloud and the proliferation of mobile devices and the ongoing expansion of the Internet of Things (IoT) means that data can be created and accessed anywhere, from the datacenter to the cloud and out to the still-forming edge. Further complicating the picture is that increasingly the data is unstructured – images, videos, emails and text, social media content, streaming and IoT data – and doesn’t reside only on servers or in data warehouses in the data center. IDC says that by 2025, 80 percent of the data created will be unstructured.
At The Next Platform we’ve talked about a number of top-tier vendors rolling out new hardware and software designed to address the growing challenge of data growth, unstructured data, and the need for architectures that can support modern technologies like artificial intelligence (AI), machine learning, NVM-Express and storage-class memory (SCM), and analytics. That has included Dell EMC, which over the course of less than two months unveiled its PowerStore flash systems and PowerScale, optimized for storing and managing unstructured data. Hewlett Packard Enterprise in June added more intelligence and automation features to its Primera and Nimble storage lineups and Pure Storage last month released Purity 6.0, the latest iteration if its storage OS to enable its FlashArray systems to support both file and block storage natively on the same system.
Most recently, IBM earlier this month ran out new storage hardware and software to help create a portfolio that can better support AI-optimized workloads.
Hitachi Vantara this week came forth with its own new and enhanced storage solutions that, like HPE, Dell EMC and others, can be had via an as-a-service subscription model, another step in the industry’s larger effort to bring more cloud-like capabilities in the datacenter. Hitachi Vantara is the operational technology (OT) and IT business of Hitachi, the Japanese multinational conglomerate that has its fingers in industries and markets all over the world. Hitachi began laying the groundwork for Hitachi Vantara in 2016 when it pulled its industry-specific IoT solutions into an umbrella organization called the Hitachi Insight Group. A year later, Hitachi combined that group with Hitachi Data Systems (its compute and storage business) and Pentaho data integration and analytics unit to create Hitachi Vantara, a company with more than 7,000 employees. In January, the company pulled its Hitachi Consulting unit into the fold.
At its Next 2019 show last year, Hitachi Vantara spoke a lot about DataOps, a maturing methodology leveraging automation and processes to be used by data and analytics professionals to accelerate the cycle time and improve the quality of data analytics.
Keeping its focus on data, the company this week introduced steps it’s taking to enable enterprises to leverage hardware and software solutions to manage the deluge of data that they’re generating. That includes the infrastructure that enables organizations to take advantage of the data, getting easy access to the regardless of where it resides – the datacenter, cloud or edge – and the architecture needed to do all this in a multicloud environment.
“That’s really what most of our customers and most of the market is out there trying to implement,” Brian Householder, president of digital infrastructure at Hitachi Vantara, said during a briefing. “Public cloud is here. There’s a number of public clouds that many companies are all using, not just the main three. There’s lots of SaaS [software-as-a-service] providers, but you need to have a data strategy that really covers whether your data sits at the edge, it sits in your core, or it sits somewhere out in the cloud. That’s what we’re all about in terms of the solutions that we have. It’s clearly a huge trend towards shifting for more as-a-service type models.”
The company in October 2019 expanded its flagship Virtual Storage Platform all-flash array lineup with the VSP 5000, which comes with NVMe and SAS SSDs, upgrade pathways to NVMe-over-Fabric and SCM, and capacity of 21 million IOPS and 69 PB. In April, the company rolled out the VSP e990, an enterprise-class system priced for midrange companies. At the same time, Hitachi Vantara introduced EverFlex, a flexible way to buy and consume products and services, along the same thinking as HPE’s GreenLake and Pure Storage’s Evergreen offerings.

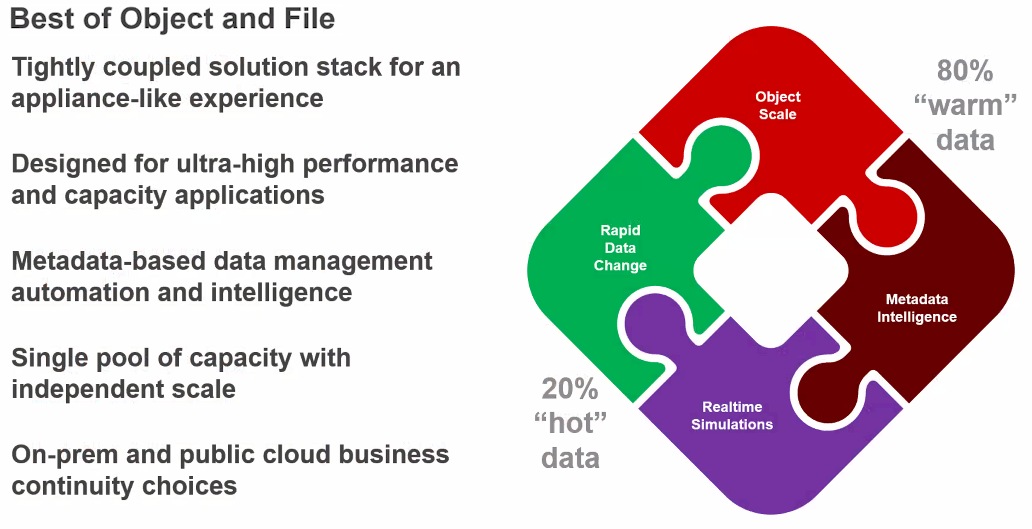
This week, the company announced partnership with WekaIO, which sells a parallel file system aimed at handling HPC and AI workloads that the company has positioned as an alternative to GPFS, IBM Spectrum or Lustre. The partnership with the seven-year-old company will combine WekaIO’s NVMe parallel file system and the Hitachi Content Platform for object storage and address the growing amount of unstructured data. Hitachi Vantara will be able to roll out a new distributed file system and management solution, enabling enterprises to more quickly process and analyze unstructured data.
“Distributed file systems are good for when the data is changing rapidly or unique, [needing] rapid access to that for real-time simulations,” said Colin Gallagher, vice president of infrastructures solutions product marketing. “That’s the hot data that you need to have access to. It turns relatively frequently. But when you’re doing analytics, a lot of times the rest of it is warm – it sits there, it’s not being changed. But when you want to do analytics, you need to retrieve it rather quickly and that data scales massively. That’s what an object store is good for, the unlimited scale capabilities and the ability to apply metadata to that as well. You don’t actually have to open the actual file. You can look at the metadata and perform analytics on the metadata as well. File systems really have very little metadata capabilities and big-time creation size, etc. By marrying WekaIO with our Hitachi Content Platform, you got the best of both worlds.”
The jointly-developed, Hitachi-branded offering will enable Hitachi to address a range of new workloads, including AI and machine learning, life sciences, manufacturing, and oil and gas.
Enhancements to the Hitachi Content Platform includes second-generation all-flash nodes that will bring 3.4 times faster S3 throughput and a 34 percent lower cost. In addition, its s11 and s31 storage nodes now can automatically balance capacity across multiple nodes and the HCP S Series software is driving a three times improvement in performance and scale, read and write performance and capacity in the same rack, up to 15 PB, which translates into more than an exabyte of data in an on-premises, fully scaled-out HCP solution, she said.


Intel Targets DAOS Object Storage At More Than HPC
Intel is looking to position itself as a leader in AI and HPC through a holistic approach that plays to the company’s strengths across a broad swath of the IT ecosystem. This covers not just silicon hardware such as CPUs and ASICs, but also the firm’s expertise in open software …
Australia’s NCI Adds Ceph Object Storage To Lustre File Systems
Object storage has been drawing an increasing level of interest from organizations over the past several years as a convenient way to store and manage the growing quantities of data they are accumulating, especially when that may be a mix of structured and unstructured data and a lot of machine-generated …

Ceph Gets Fit And Finish For Enterprise Storage
Ceph, the open source object storage born from a doctoral dissertation in 2005, has been aimed principally at highly scalable workloads found in HPC environments and, later, with hyperscalers who did not want to create their own storage anymore. For years now, Ceph has given organizations object, block, and file-based …
…because there is lots of “free oil” that powers the world on clouds of something…
Which Chinese made HPC will you buy?