

While companies are beginning to think at the rack scale and hyperscalers like Google, Facebook, Amazon, and others have long since been thinking about computing at the scale of an entire datacenter, it is important to remember that computing happens at the server node and therefore the server node architecture matters.
This, more than anything else, was the message from Shekhar Borkar, Intel Fellow and director of extreme-scale technologies at the chip maker. Borkar spoke recently at the ISC 2015 supercomputing conference, laying out the challenges that all server makers have as they try to create energy-efficient and cost-competitive nodes that can be used to build exascale-class machines. There is a wide variety of opinion about how this is to be accomplished, both within IT companies and across them. The good news is, there doesn’t have to be just one answer to the question of how we will get there.
The challenges that system architects face as they try to get to exascale and beyond are daunting, but we would remind everyone that the jumps from mega to tera to peta were not exactly cake walks, either. The one consistent theme that we keep hearing is that we need a new, more efficient memory subsystem design and one that can accommodate different kinds of memory (fast and slow DRAM, fast and slow NVM, and maybe disks and tape) to provide balanced performance as data moves from cold to hot and back again in the system. Borkar concurs with this and adds that the massively parallel machines he envisions as a possible future for HPC – and therefore, inevitably for commercial uses as enterprises follow suit – will require extreme parallelism while dealing with issues of data locality and will have to have a new programming model that will have a modicum of what he calls “introspection” and “self-awareness” so we can get these massive machines to do the amount of useful work their feeds and speeds will suggest they can accomplish.
Borkar was also very clear that the theoretical machine that he envisions is not an Intel product, so don’t get confused by the thinking about how a future exascale system node might be actually built and the though experiments that Borkar has put together to show how it might be done with a clean slate. There is rarely a clean slate in the IT market, after all. But as an Intel Fellow, Borkar is paid explicitly to think big and to think different. He also took the time to walk through the issues at a very fine grain to build his case for a specific kind of node design for exascale systems.
Here are the key elements of such a futuristic server node, as Borkar sees it:

One of the key parts of the picture, which you would expect, is to bring the voltage and therefore the power consumption of processors down using near threshold voltage (NTV) techniques that Intel has been working on for years.
“Supply voltage scaling is not dead,” Borkar said emphatically.” It is only for those who know how to do it. I am a circuit designer, and with near threshold voltage, I know how to do this. If you reduce the supply voltage, the energy comes down, but it comes with its own challenges, such as variability. And if you know how to take care of the variability in circuits, you can do it. But don’t do this at home. Leave it to us. We know how to do this.”
So clearly NTV technologies could play as big of a part in future processor designs from Intel as does the Moore’s Law transistor shrink, the pace of which even Intel has conceded is slowing. As for system-level power management, which is a key aspect of a future exascale machine, Borkar says that this technology is only in its infancy, with some power management on laptops and maybe at the rack level in a datacenter. The components in the system will likewise have to be equipped with many more sensors and a means of quickly analyzing and reacting to data to do the “introspection” or self-management that a very large system with perhaps billions of threads will require.
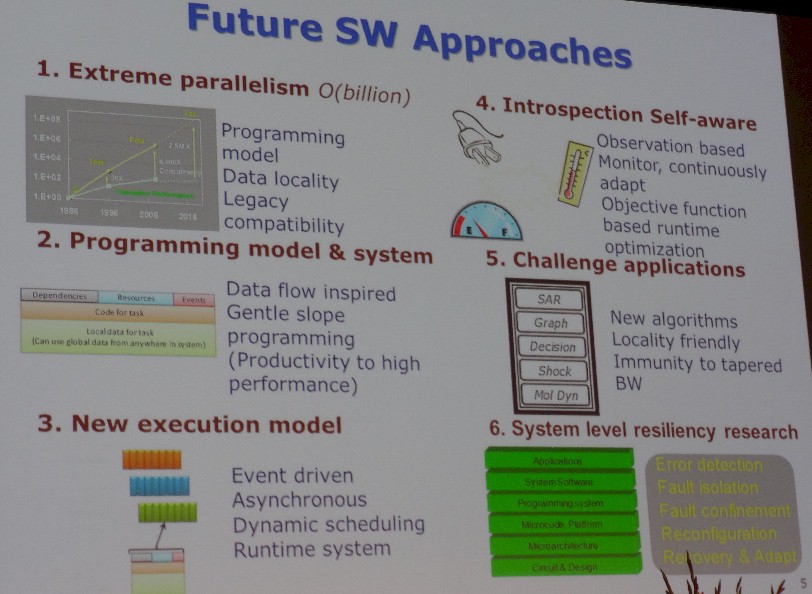
The scale of this machine will require the overhauling of the memory subsystem inside nodes and a new programming model that can comprehend and use those billions of threads and resiliency features that will allow large applications spanning those threads to keep running even as servers crash left and right inside the cluster.
The first argument that Borkar made about the future exascale machine – at least an energy efficient one as he envisions – was that it will have to be extremely parallel, and that is precisely because transistor scaling is running out of gas, with this effect:
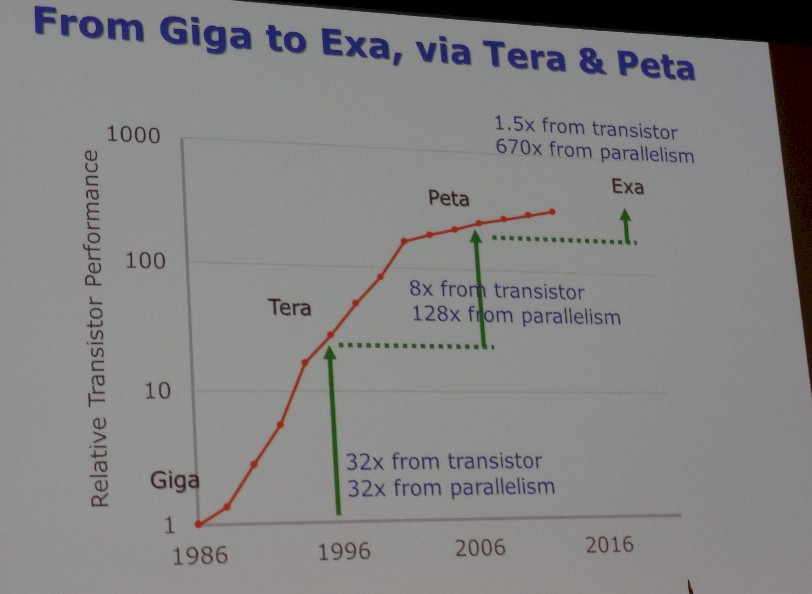
“What will happen with exascale?” Borkar asked rhetorically. “If we are lucky, we can get 50 percent performance from transistors, and the other 670X has to come from parallelism. I always wonder when people talk about Amdahl’s Law, does it really make sense here? Because we have been increasing the parallelism and still our system performance is increasing. So I don’t believe in Amdahl’s Law.”
A stunning statement, but Borkar makes a valid point. (As you would expect an Intel Fellow to do.)
He makes another valid point when he flashed up this little beauty of a chart, showing the relative efficiency and performance of different processor architectures that have been deployed over the past several decades, all with the idea of increasing the throughput of integer and floating point units.
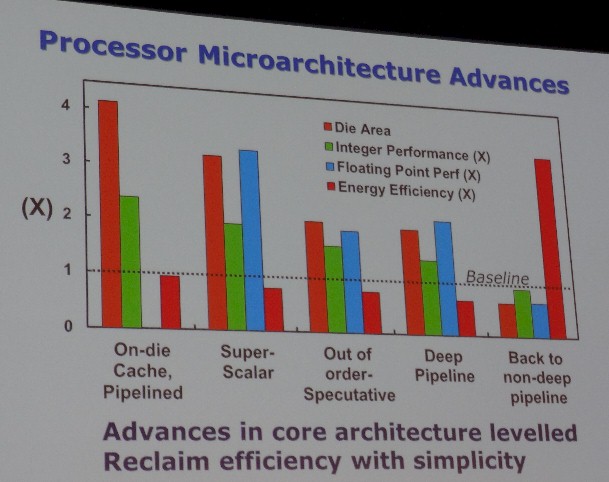
The on-cache die with pipelines was an 80386 design, Borkar said, and the super scalar, out of order speculative, and deep pipeline architectures were used with various generations of Pentium-class chips.
“With each generation, the energy efficiency has gone down until we went back to non-deep pipeline architectures,” explained Borkar, who has a wry sense of humor if you haven’t noticed. “So I wonder, do architects really worry about energy efficiency? I don’t think so. They are more worried about programmability and usability than energy efficiency. Clearly the advances in core architectures have leveled off. As a circuit designer, when it comes to energy efficiency, I don’t go to the architects. We want to reclaim the efficiency with simplicity and keep the architects away from designs.”
The big problem, Borkar demonstrated again and again in his presentation, was that interconnects are eating far too much energy. Not the CPU, not the memory. Look at the difference between past 45 nanometer chips all the way out to 7 nanometer chips that Intel will be making many years hence:
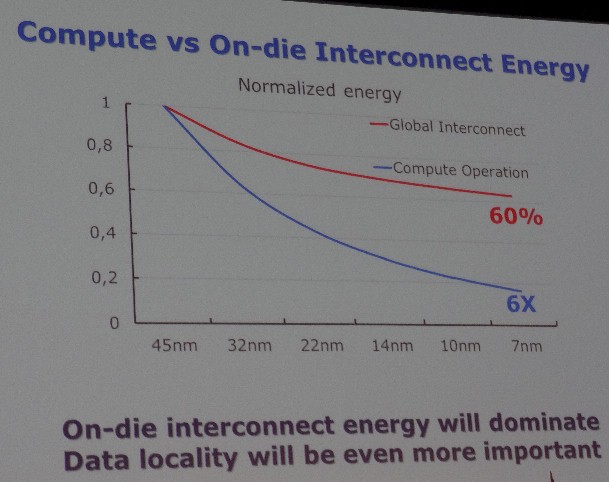
If you look at the compute versus on-die interconnect energy use, which is normalized for chip die area in the chart above, the interconnects are projected to only reduce their energy consumption by 60 percent between the 45 nanometer and 7 nanometer nodes, but compute operation energy consumption is projected to fall by 6X over the same span. (Intel debuted 45 nanometer chip manufacturing in November 2007, and could debut 7 nanometer technologies in 2020 or 2021.) The important thing is that Borkar and his fellow researches see that the on-die interconnect energy will dominate, and that the data locality, even on the chip, will start becoming even more important. You want to move data as little as possible, and for as little energy as possible.
The reason is, picojoules add up, and they add up bigtime and quickly in an exascale machine. Do the math along with Borkar on a basic compute loop.
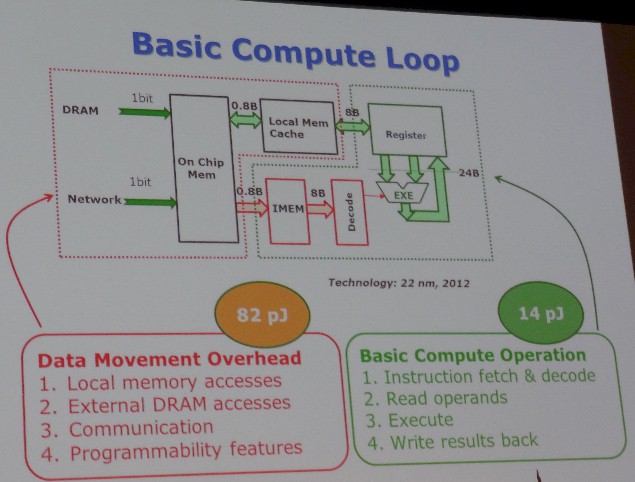
“On a 22 nanometer chip, the loop consumes 14 picojoules, and on a exaflops machine that means 14 megawatts just to do a simple operation. If you look at the data movement overhead to support this, which is local memory access, external DRAM access, communication, and some programmability features, it is 82 picojoules, and on an exascale machine, that works out to 82 megawatts.”
How will that trend down over time? Not nearly fast enough, as this chart shows:

With nodes using processors based on 22 nanometer chip making technologies, it will take close to 100 megawatts to have a system doing an exaflops worth of loops, and it will still be close to 40 megawatts at using 7 nanometer chips. The process shrink helps, but not nearly enough.
The problem is, as Borkar has pointed out above, the interconnects in the die, and as one example, he did a detailed energy analysis of the interaction between a processor and DRAM main memory:
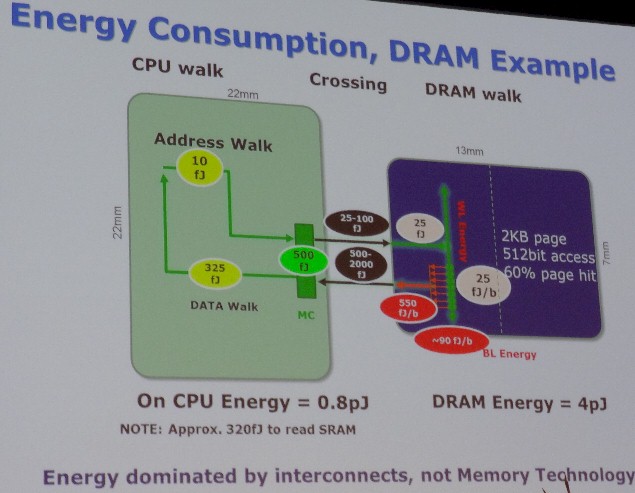
The thing to note in this chart is that actually reading the data from memory requires very little energy – about 25 femtojoules per bit. But look at how much energy is consumed by other parts of the CPU and memory complex. It ends up being about 4.8 picojoules in total.
“Clearly, the energy for memories is dominated by interconnects – not by the memory technology,” said Borkar. “There is so much hype out there about memory technology for reduced energy, and when you go and look at this data, it clearly shows it is not the memory technology that matters when it comes to node memory. Similarly, the access times are dominated by the interconnects and not by the memory technology. So where does the memory technology matter? Cost and for other things like non-volatility. ”
Because Borkar is precise and thorough, he put together a series of comparisons showing the maturity, memory cell size, density, cycle time, energy consumption, and endurance of key memory technologies, including SRAM, DRAM, flash, phase change (PCM), spin transfer torque (STT), ferroelectric (FeR), magnetic (MRAM), and resistive (RRAM) memories.
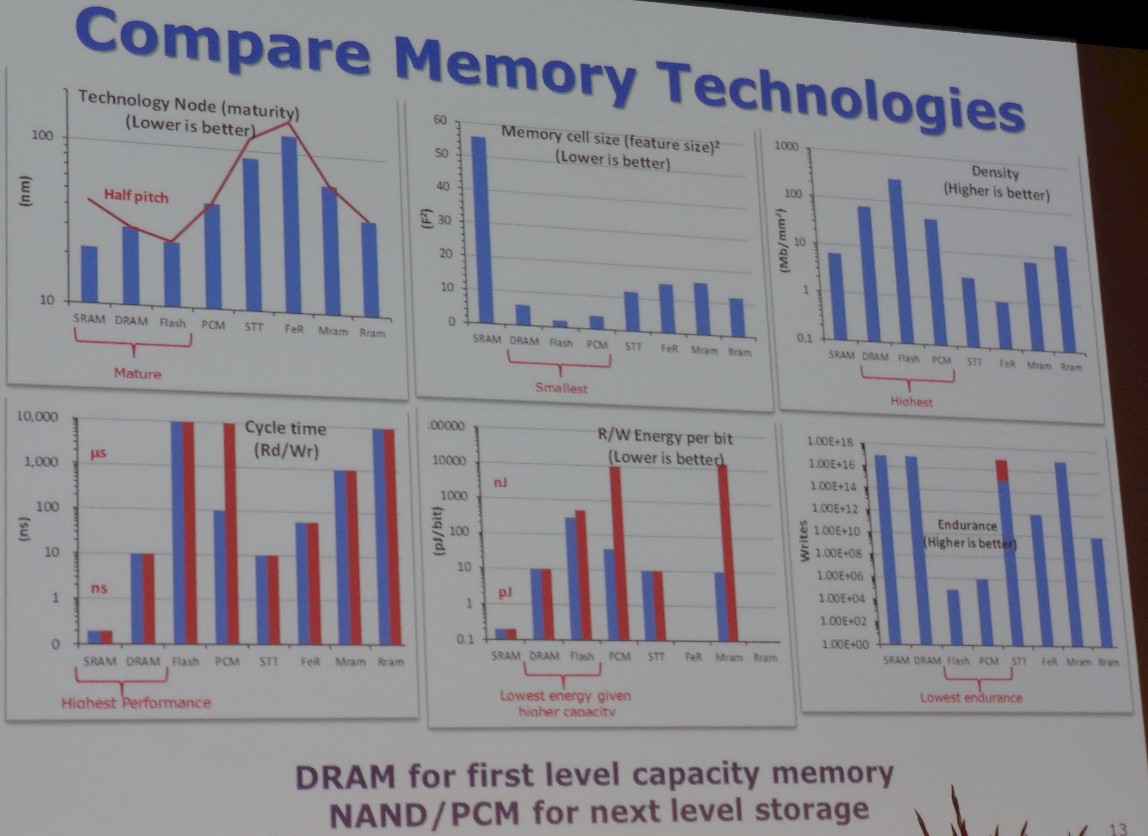
“If you put this all together, the bottom line is that for the next ten years, if I am a node designer, I will rely on DRAM as a first-level, high capacity memory, followed by NAND or PCM as the next level for storage. Everything else – keep working on it, and when it is ready, I will use it. Today, you are not ready.”
Future Node Design
We are all familiar with the current compute architecture in use in HPC, hyperscale, cloud, and enterprise datacenters. A processor has tens of cores, each with various levels of unique and shared caches. Multiple of these are linked together coherently to present a single image to an operating system, and often multiple processors are linked to each other coherently to share memory within a node. Multiple nodes are linked using high-speed networks and workloads are shared across the nodes using message passing interface (MPI) or similar software.
The future exascale server node that Borkar imagines will have hundreds to thousands of cores on a die and large caches and main memories, but there will be no coherency across the caches. Similarly, there will be multiple processors on a node, but there will be no coherency across the caches. Message passing will be the way that these systems manage memory, and it will be done natively across a heterogeneous and hierarchical network that spans from one core out to the entire exascale system, using optical interconnects for the biggest jumps.

“The extreme scale programming model, as I see it into the future, needs to comprehend this kind of shift,” said Borkar. “So the straw man I suggest for the node has a very simple core. Why? I showed you the data. If you try to give it to the architects, they will make it unnecessarily complicated and energy inefficient.”
This design, Borkar says, will bring the power consumption of an exascale machines down below the 20 megawatt limit that everyone is shooting for. You will note that this theoretical chip at the heart of this imagined exascale machine has 4,096 cores on a die and delivers 16 teraflops of floating point performance at double precision, all in under 100 watts and, importantly, at more than 200 gigaflops per watt. An exascale machine using such a theoretical processor would have 62,500 of these processors, 256 million cores, and perhaps four threads per core to reach that 1 billion thread mark, if you do the math. The nodes would have something like 3D stacked HBM-like memories, but with limited capacity, right next to the processor and then it will link to high-capacity, low-cost memory based on “DDR4, DDR5, DDR6, or whatever, but it is some kind of commodity DRAM that is there for high capacity,” as Borkar put it. “Maybe it is PCM, maybe NAND, that is to be seen.” The interconnect comes off the die and there are options for shared bus, multi-port, crossbar switched, and packet-switched interconnects, all done with a hierarchy. “This is a hierarchy with heterogeneity all the way through.”
This seems like a lovely exascale machine. If only someone would build it.

Don’t believe in Amdahl’s law eh? Those of us who run large HPC systems know that only a fraction of codes are capable of running efficiently on large systems and the average node count used goes down when new technology introduces more parallelism on a node.
Difficult as the hardware is, designing software for exascale is harder.
So very true especially since the main bottleneck are becoming memory access and memory transfer. It is already hard to think about parallelism it is even harder to think how to efficiently let your data travel through the compute fabric if everything is a blackbox as there are barely any tools out there to assist you. Sometimes it might be even better not too store anything and just compute it again.
Its a little odd to hear that he expects to see RAM DIMMs in an exascale system. I dont expect them to be there at all.
I expect that the actual compute nodes will have fewer than 4096 cores too.
It sounds like other people at Intel are thinking the same thing if the article about breaking up the CPU for Knights Hill and removing DDR4 is accurate.
I would think that a few hundred GB of HBM or HMC derived memory on package or even near the CPU would be a lot more efficient than electrical traces to DDR RAM and it eliminates the need for two separate controllers wasting die space which will be at a premium.
I dont envision super low core count nodes though because then youll have way too many interconnects wasting power talking to each other. It will have to be a balance of per core compute power and core count.
I dont know how many exascale problems will usefully scale to a billion threads. That sounds like a big data machine or a giant graph appliance. Some proems that need exascale power dont necessarily benefit from that much SMT or thread count.
I also think pretty much all the jumps to be optical as well. Intel has been talking about optical interconnects and silicon photonics for YEARS, yet there are currently deployed supercomputers on the Top500(in Japan) that rely on optical interconnects. The chip to chip communications are currently electrical from on chip fabric but i expect that to change on the next generation.
I dont know if oscillating back and forth from KNL with high core count and DDR4 to no DDR4 and lower core count for Knights Hill and then presumably swinging back in the direction of KNL again makes any sense. It sounds like Intel needs a clearer exascale plan like certain other companies that are likely to beat them to it have.