

As one of the fastest growing markets in HPC, the manufacturing sector is looking to supercomputing to drive its next generation of product modeling and simulation. Finite element analysis packages are essential, but for mid-sized manufacturing companies, running these on workstations with four or eight cores is the norm due to expensive per-core licensing for the software.
This description of an HPC workstation-only approach applies to Poland’s largest steel processing company, Stalprodukt S.A., which finally took a very large step toward running much more sophisticated and faster simulations to meet customer demands for durable and inexpensive steel products in Poland and abroad. The company made a massive leap from the workstation to a Cray XC30, in part because of its proven track record on the LS-DYNA CAR2CAR benchmark—the standard by which finite element analysis using that software is measured.
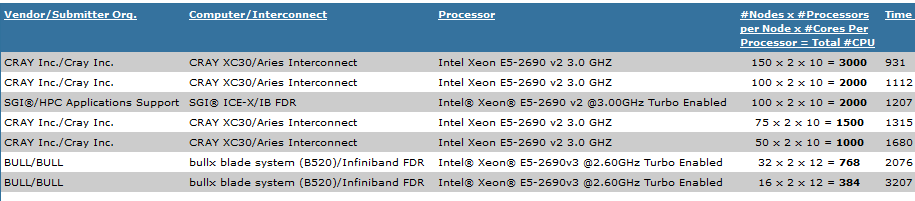
One the key people behind the decision to buy the Cray system at Stalprodukt, Marcin Piechnik, told The Next Platform that when it came to the other systems the company evaluated using CAR2CAR benchmark results, including those from SGI, Bull, and Hewlett-Packard, it was the Aries interconnect in the XC30 that made the crucial difference for running their LS-DYNA workloads. The XC30, which uses Intel’s “Sandy Bridge” Xeon E5-2600 processors, offered his team a 20X performance boost.
The interesting bit is that there are only two engineers handling the LS-DYNA models at Stalprodukt—the two who were using only workstations until the Cray system was put into production two months ago. The company’s Jozef Ryszka said that the team is now able to run with a much “higher level of accuracy, while still meeting the tight design schedules” on a workload that “needs not only fast CPUs but also ultra-fast communication between nodes.” While it is no surprise that the performance and productivity will skyrocket anytime you jump from worksations with four or eight cores to a cluster with 384 cores in cabinet and sporting one of the fastest interconnects on the market, when it’s just managed between two people who have no experience operating a high performance computing cluster, this is a little bit surprising. Piechnik said that while the level of complexity for managing such a beast will indeed go up, a good part of Stalprodukt’s decision-making process against other vendors was access to support, not feeds and speeds.
Piechnik says that hardware costs for the system were right around $200,000, which based on the prices we’ve been able to collect on how much cabinets tend to go for, seems rather low. Piechnik said that when Stalprodkt made its buying decision, the performance of its calculations and the application and system support were more important than the cost of the system. , Stalprodukt did shave the costs off in some areas by selecting 10 Gb/sec Ethernet and not investing in additional storage. He does expect that there will be a bit of a learning curve as his engineers get used the Lustre file system, but Stalprodukt’s main concern over the past two months on that front is that engineers cannot read the results directly from the XC30, so they are downloading the results to their workstations. Piechnik does, however, expect that they’ll find a solution for this in the near term.
Piechnik said it was difficult making a comparison among the vendors based on distinct hardware components, so Stalprodukt went with the CAR2CAR benchmark, which had be under 4,500 seconds for their time to result. In its effort to get in front of the smaller and mid-size manufacturing market, Cray pushed out benchmarks on CAR2CAR and LS-DYNA late last year, which showed the XC30 with everything optimized for LS-DYNA at 1,000 seconds. In fact, the company has touted its performance running CAR2CAR against other vendors on an independent DARPA sponsored audit, which shows performance using similar cores on machines from SGI and Bull. The net result of the below benchmark comparison shows the relative strength of the Aries interconnect, which is particularly important for finite element jobs.
Cray is continuing to invest in the future of HPC in manufacturing with LS-DYNA in particular by working with the developers of the code (Livermore Software Technology Group) to ensure it will scale across ever-larger systems. As of now, the code tends to flatten out performance-wise at around 1,000 or 2,000 cores, depending on the scope of the problem.
As a report from Cray that looks at these scalability problems for the next generation of manufacturing modeling and simulation jobs using LS-DYNA points out, Stalprodukt was in the sweet spot in terms of cluster size. The XC-30 cabinet with its 384 cores appears to be the perfect fit for the application—a “problem” that is significant for both manufacturers that want to tackle more complex simulations, and of course, for Cray, which wants to sell more and larger systems to manufacturing end users.
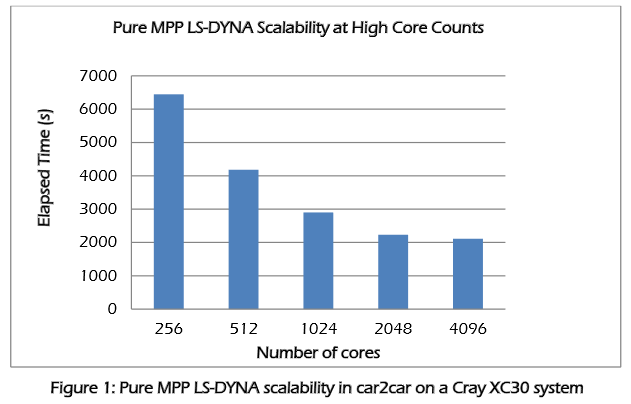
The above results are using a standard XC30 cabinet with 2.5 GHz Xeon E5 processors, the Aries interconnect and Dragonfly topology—again, the Aries interconnect is the key to the performance gains according to both Cray and Stalprodukt. While running LS-DYNA on an XC30 is a “Cadillac” experience compared to workstations, it is not uncommon for manufacturers, in part due to the high per-core licensing for the software and overhead of maintaining a cluster, to take the workstation route, especially when one considers the scalability of these workloads is rather limited.
For now, scaling to that number of cores is a far cry from reality for a company like Stalprodukt, but it’s a big leap from running complex calculation on workstations. However, the net result for the company, according to Piechnik, is the ability to deliver products to market much faster, including the delivery of the required physical prototypes for pre-testing—something required for all products leaving European manufacturers.
As mid-size manufacturers look beyond the workstation, however, there are the concerns that Stalprodukt’s team mentioned during our conversation. Even with support, adding a cluster of this size with a potentially unfamiliar file system and operating environment does mean a learning curve. Hardware costs aside, for many without HPC expertise aside from workstation use, support costs can mount and so too can the per-core costs for LS-DYNA (or ANSYS, Hyperworks, and others). That means some tough ROI decisions over the long haul—and potential opportunities for the HPC vendors that can show how boosting time to result on key modeling and simulation codes pays off in the end.


Lawrence Livermore To Surpass 2 Exaflops With AMD Compute
As the steward of the nuclear weapon arsenal for the United States government, it is probably not an overstatement to say that Lawrence Livermore National Laboratory, one of the main supercomputer and scientific research facilities operated by the Department of Energy, is keenly interested in bang for the buck. And …

Academia Gets The First Production Cray “Shasta” Supercomputer
Indiana University is the proud owner of the first operational Cray “Shasta” supercomputer on the planet. The $9.6 million system, known as Big Red 200 to commemorate the university’s 200th anniversary and its school colors, was designed to support both conventional HPC as well as AI workloads. The machine will …
The Balancing Act Of HPE’s Systems Business
There is perhaps no better logo for Hewlett Packard Enterprise than the box. HPE receives a bazillion boxes of components, assembles them into boxes we call servers, storage arrays, and switches, and then ships them out wrapped in other boxes to its millions of customers worldwide – mostly, by volume, …
Be the first to comment