
A lot of companies talk about open source, but it can be fairly argued that Meta Platforms, the company that built the largest social network in the world and that has open sourced a ton of infrastructure software as well as datacenter, server, storage, and switch designs, walks the talk the best.
Which is why we were not surprised when Meta Platforms created its Llama family of large language models and released the Llama 1 versions to the world in February 2023 and then quickly open sourced the Llama 2 upgrades in July 2023. This week, at LlamaCon 2025, the first developer conference for the Llama AI stack, Meta Platforms took it one step further and is taking on rival model maker OpenAI in releasing an API interface to its Llama 4 models, also launched this week, and making them available as a fully functioning service on a pay-per-use basis.
With this, Meta Platforms, the only hyperscaler that did not have an orthogonal but connected cloud business, becomes a cloud. And to be specific, it becomes a platform cloud. And now you can all start paying Meta Platforms money to use its API and its homegrown Open Compute hardware as well as that of key inference partners, Cerebras Systems and Groq, to generate your tokens rather than have to set up a datacenter of your own to run self-maintained Llama models.
With this move, the developers at established companies and startups the world over will give Meta Platforms a new revenue stream that it can use to invest in infrastructure and improve its models and other elements of the software stack, such as the Python programming language and the PyTorch AI framework that underpin what the social network, which also owns Instagram and WhatsApp. Right now, the vast majority of the revenue that Meta Platforms brings in comes from advertising – north of 97 percent.
The question now is how long before the Llama API service drives a material amount of sales and profits that Meta Platforms is compelled by SEC regulations to report it as a separate revenue stream. Revenue and operating income both have to cross a 20 percent threshold for reporting to be compelled for acquisitions, but there is no hard and fast rule for divisions created organically inside the company. The rules are vague and lower here, but 5 percent or 10 percent and growing fast seems like a baseline to us.
There is every reason to believe that Meta Platforms can build up its AI platform cloud business fairly quickly, and it all starts from the groundswell of support for an open source LLM that could compete with the best of the proprietary models like those from OpenAI, Google, and Anthropic. And Llama has very quickly become the model of choice for those who want to control their own destiny a little more than if they just license a model from these and other companies.
“It is crazy to think that two years ago, open source AI was a dream,” Chris Cox, chief product officer at Meta Platforms, said in the opening keynote at LlamaCon. “I remember the conversations we had internally when we started talking about this. People were like: You guys are nuts. There was this financial question: Does it make sense to spend all this money on training a model and then give it away? There was this priorities question: Is this going to be a distraction to focus on developers and open source instead of just training the best model and putting it in our products? When we started talking about it externally, it was just like: This is bad. This was peak AI Doomer. Two years ago, everybody said open source is going to fall into the hands of bad guys. There was not a lot of imagination about all the good that could come of it. There were the safety and security questions. There was the performance question: Could open source ever compete close to the frontier of the closed labs?”
But Meta Platforms, way back when it was Facebook, was a startup once, too, and its engineers built the company on open source software and contributed back to the projects that created and maintained that software. Here is the stuff it has given back:

In the long run, Llama might be the most consequential code that Meta Platforms ever opens up. Let’s zoom in on Llama and add Llama 4 and the API to the open source roadmap:

“There is general consensus in government, in the tech industry, among the major labs, that open source is here to stay,” Cox proclaimed. “It is an essential and important part of how AI will be built and deployed. It can be safer and more secure, just like Linux, because it can be audited and improved in broad daylight. It can be performant at the frontier, and most importantly, it can be deployed and customized for specific use cases, for specific types of applications, and specific types of developers.”
It is hard to argue against that, but the winding road of history is littered with the rotting carcasses of open source projects that died because they had no way to eat. Having one of the world’s largest advertising businesses is one of the reasons why Facebook and then Meta Platforms can afford its altruism. And to be even more specific about it, feeding out an API from its own infrastructure is a hell of a lot simpler than creating a virtualized infrastructure cloud that has to do so many different things for millions of companies.
Including running LLMs like Llama the way companies think they need to do it by themselves.
The numbers of downloads for Llama and its derivatives completely overshadows the proprietary models:

Cox says that there are thousands of developers creating tens of thousands of derivatives of Llama that are collectively being downloaded hundreds of thousands of times each month. As of today, there are 1.2 billion downloads of the ever-embiggening Llama model herd.
This is a technical force that is about to go economic.
Let’s talk about the Llama 4 models, which were previewed a month ago and which are sparely activated, multi-modal foundation models.

The Llama 4 Behemoth variant has 2 trillion parameters in total, and at any given time 16 experts with a total of 288 billion parameters active. Because it is so difficult and expensive to run at scale, Behemoth was used as a “teacher” model to train the other two “student” models in the set: Llama 4 Maverick and Scout.
Llama 4 Maverick has 400 billion parameters, about the same as the top-end Llama 3.1 and 3.2 dense models, but in this case, only 17 billion of its parameters are active across 128 experts that, we presume, are finely runed bits of Behemoth that are strung together. The Maverick model is interesting in that it has a 1 million token context length for input, and it is multimodal input (image, text, video, sound).
The Llama 4 Scout model is trimmed way say to 16 experts and 17 billion active parameters, but has a total of 109 billion parameters. Because the model is smaller, Scout can have a much larger context window: 10 million tokens. So you can, as Cox pointed out, drop the entire US tax code in the context to help you with your taxes. Scout is optimized for inference, and it is designed so it can fit inside the compute and memory budget of an Nvidia H100 GPU accelerator. Maverick is designed to fit inside of an eight-way Nvidia HGX H100 GPU system board commonly used in server nodes inside of Meta Platforms and other companies. It will also fit inside of the equivalent eight-way Instinct MI300X system board, which has more memory and roughly the same raw performance.
And finally, here is where the rubber hits the road on the API versions of the models in terms of performance, cost:
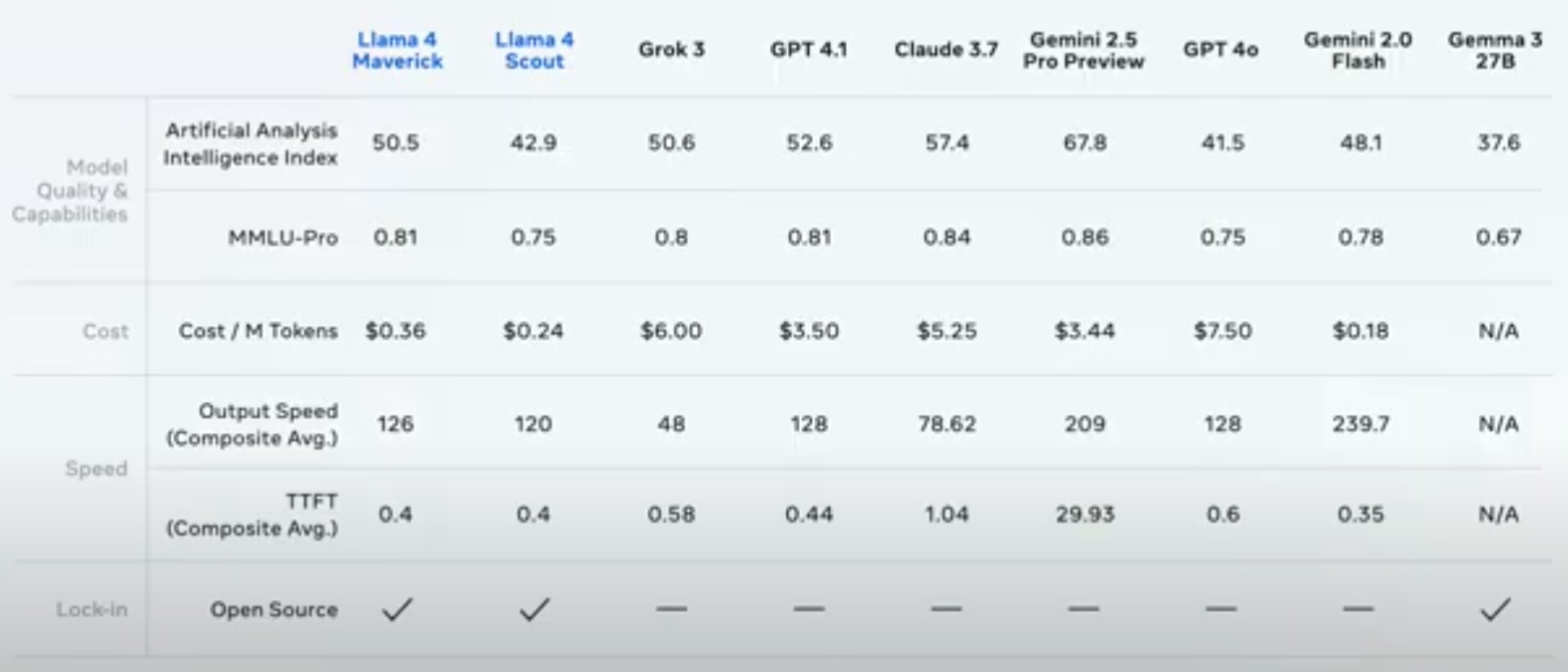
We are still amused at composite test scores. The Gemini 2.5 Pro model scored a 67.8 percent on the composite AI tests run by Artificial Analysis, which where we come from back in the dawn of time was an uncurved (none of our teachers grades on a curve) F+. And all of the other models fail so bad that they would be held back or moved down a grade or two. Expelled from school, maybe.
In any event, in the table above, output speed is expressed in tokens per second, and the time to first token (TTFT) is expressed in seconds. The two smaller Llama 4 models beat OpenAI’s GPT 4o in terms of smarts by a little bit and cost 21X to 31X less per million tokens processed. The pricing gap is a little less than half as big for Llama Maverick and Scout compared to Google Gemini 2.5 Pro, and the test scores are higher. Companies will have to judge for themselves how important right answers are. But on the Massive Multi-discipline Multimodal Understanding (MMMU) test suite, the performance haps are not that different in the models, so this is just a price war.
What is not in the table is the fact that Meta Platforms has partnered with both Cerebraas and Groq to run the Llama 4 API service on their respective cloudy infrastructure in the Cerebras and Groq datacenters. There are no pricing or performance metrics for the API when it runs on these machines, but presumably with much higher token rates and shorter times to first token, they will be priced at a premium compared to running the API on Meta Platform’s own fleet of H100 GPUs in its own datacenters.
In a briefing we joked with Cerebras that it would be nice if Meta Platforms just bought this alternative iron and got both Cerebras and Groq out of the cloud business entirely, except for maybe a few racks of gear for prototyping. SambaNova as well as these two companies were never supposed to be building hardware and trying to then build clouds. They are supposed to be making accelerators.

Amazon Gears Up To Profit Mightily From The Generative AI Boom
Because they are in the front of the line for acquiring Nvidia datacenter GPUs, the hyperscalers and cloud builders are going to be the ones who benefit mightily from shortages of matrix math engines that can train AI models and run inference against them. And it looks like Amazon Web …
Meta’s Velox Means Database Performance Is Not Subject To Interpretation
A decade and a half ago, when Dennard scaling ran out of gas and many of us were starting to first think about what the end of Moore’s Law might look like should that day ever come, a bunch of us were kicking around what it might mean. People brought …

Marvell Pivots To AI Silicon, Looks Poised To Profit
It is hard to bet against the GenAI boom, and thus far it is also hard for anyone other than Nvidia to profit from it. No one knows these facts better than Marvell Technology, who along with rival chip maker Broadcom, is seeking to benefit from the bevy of custom …
Be the first to comment