

Each time that the United States has figured out that it needed to do export controls on massively parallel compute engines to try to discourage China from buying such gear and building supercomputers with them, it has already been too late to have much of a long term effect on China’s ability to run the advanced HPC simulations and AI training workloads that we were worried would be enabled by such computing oomph.
If the goal is just to slow the competition down a little, then we suppose you can say that export controls imposed by the US Department of Commerce can be said to be successful. But in the long run, vendors based in the United States – in these cases, Intel and Nvidia – were compelled by regulation to sacrifice revenue and we lost visibility into the supercomputing being done inside China in exchange for maybe a couple of years of delay and annoyance of Chinese HPC centers and now hyperscalers and cloud builders.
Is this all worth the trouble it causes?
It is debatable, and that debate was started anew this morning when the Wall Street Journal ran a story talking about how the HiSilicon chip design subsidiary of Huawei Technologies was readying its third generation Ascend 910 series GPUs for market in October and would be able to sell perhaps as many as 1.4 million of these devices to the hyperscalers and cloud builders in 2025. These are companies such as Baidu, Tencent, Alibaba, and ByteDance, the Big Four in China, who cannot get full-blown AI accelerators from Nvidia, AMD, Intel, and others thanks to US export controls put into effect in the fall of 2022 and subsequently tightened last year.
That is a lot of GPU accelerators, obviously. And even if these third generation Ascend 910C devices from HiSilicon offer only a portion of the capacity of the current “Hopper” H100 and announced but not yet shipping “Blackwell” B100 GPUs from Nvidia, they will be sufficient enough to do interesting work in AI, and quite possibly in HPC as well. How do we know that? Because OpenAI trained its GPT 4.0 model nearly two years ago on a cluster of 8,000 Nvidia “Ampere” A100 GPUs. That means if HiSilicon can beat an A100, it will be fine for the Chinese AI researchers to use so long as they have access to more power and perhaps more money to get a certain amount of compute to do their training runs.
We Have Seen This Export Control Movie Before
Back in October 2010, when the Tianhe-1A supercomputer at the National Supercomputer Center in Tianjin, China was revealed as the fastest floating point flopper in the world, it was created by the National University of Defense Technology (NUDT) and was comprised of 14,336 Intel Xeon processors and 7,168 of Nvidia’s Tesla M2050 GPU co-processors, with a whopping 4.7 petaflops of peak performance across all of those compute engines.
The Tianhe-2 kicker at the National Supercomputer Center in Guangzhou was also a hybrid machine, but it was comprised of 16,000 Intel Xeon E5 processors and 16,000 “Knights Corner” Xeon Phi many-core accelerators. (Basically, a GPU-like accelerator with beefy vector engines attached to stripped-down X86 cores.)
When the Chinese HPC centers decided they would build an even more powerful Tianhe-2A machine based on the forthcoming and much more powerful “Knights Landing” Xeon Phi chips from Intel, this caused the US government some heartburn because many of the big HPC centers in America were also going to be using these compute engines. And so the Department of Commerce prevented Intel from selling the Knights Landing chips to certain Chinese HPC centers. And so the Tianhe-2A machine had 17,792 nodes, each with an Intel Xeon CPU and a homegrown Matrix-2000 accelerator that used arrays of DSPs as its math engines. (We think it was really an Arm core with 256-bit vectors and had nothing to do with DSPs, and said as much in September 2017 when Tianhe-2A was unveiled.) This machine weighed in at just under 95 petaflops peak at FP64 precision, and the export controls didn’t do anything but force China to come up with its own accelerators. And fast.
The new set of export controls on Nvidia, AMD, and Intel accelerators for HPC and AI workloads will be equally ineffective at curbing progress in China and effective in spurring indigenous innovation. Which is China’s ultimate goal, anyway, as we have pointed out in the past.
We have not really paid much attention to this export control nonsense, and to sort it out, we put together a table comparing the normal A100 and H100 accelerators from Nvidia against the crimped ones it has tried to sell for the past two years. And just for fun, we put the Ascend 910A and Ascend 910B GPUs from HiSilicon up against them and made some guesses about what the Ascend 910C might look like. Have a gander:
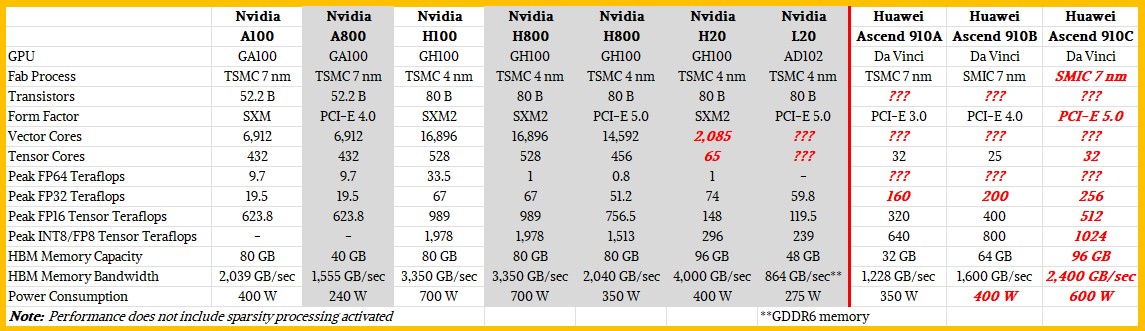
With the A800 from two years ago, all that Nvidia really did was cut the GPU memory capacity in half and the memory bandwidth by 25 percent and switch out to a PCI-Express 4.0 form factor limiting the shared memory footprint of these devices to two GPUs over NVLink rather than the eight GPUs through NVLink with a bank of NVSwitch ASICs in the middle. All of the other feeds and speeds of the A800 were the same as the regular A100. We suspect that the performance was curtailed, but not by a whole lot.
With the H100, the performance of the GPU was 1.6X to 3.4X on most metrics, but Nvidia initially kept the memory capacity the same at 80 GB and increased the memory bandwidth by 64 percent. Power consumption went up by 75 percent.
There were two versions of the H800 aimed at China last year. The SXM version, which could be linked by NVSwitch, was capped at 1 teraflops at FP64 precision and nothing much else changed. The PCI-Express version of the H800 had some of its cores de-activated, so its performance went down, and its memory bandwidth was also crimped by 39 percent. The US government decided late last year that this was not good enough, and tightened up the restrictions and put more caps on compute, but let the HBM memory capacity and bandwidth go up (quite paradoxically). The H20 in the SXM2 form factor is not particularly powerful at all, and the L20 based on the “Lovelace” GPU architecture is even worse. It is a wonder that Nvidia even bothers.
Perhaps it is because HiSilicon has been compelled by US export regulations to switch from Taiwan Semiconductor Manufacturing Co to the indigenous and still learning Semiconductor Manufacturing International Corp as its foundry.
We have not seen a lot of detail on the “Da Vinci” GPU architecture of HiSilicon, but we poked around and found this chart:

So there are 32 of these Da Vinci cores, each of which has a cube of 4,096 FP16 multiply-accumulate (MAC) units and 8,192 INT8 and a 2,048-bit vector unit that can do INT8, FP16, and FP32 operations. Take a look:
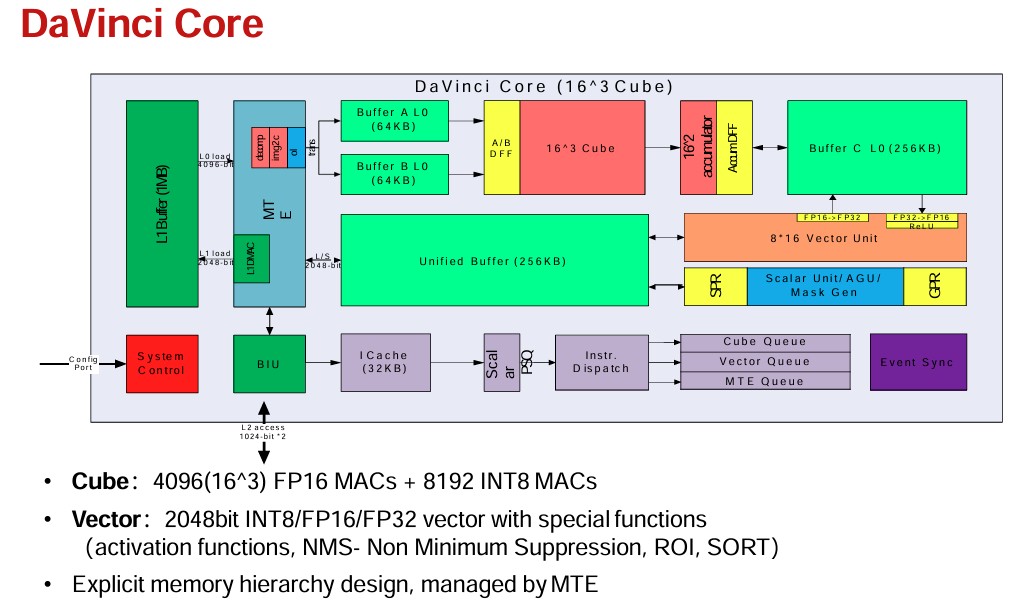
With a reasonable yield on TSMC’s N7 7 nanometer process, the Ascend 910A line was delivering somewhere between 30 and 32 of these Da Vinci cores. Which is not too bad.
But then China had to switch to SMIC as its foundry. The yield went way down on the SMIC 7 nanometer process, according to various reports – this is a particularly good report from this June on the situation – and even with an increase in core counts and clock speeds, it was very hard to get the performance up. But on the top bin parts, HiSilicon did it.
We think that the Ascend 910B might be a six by six grid of Da Vinci cores, for a total of 36 cores, and that the products that have 20 cores to 25 cores shows very low yield indeed. But we think that with the Ascend 910C coming out later this year, there might be two more HBM memory banks added to the design as well as better yield to get back to the 32 cores touted in the original HiSilicon GPU from five years ago.
That is all guesswork, of course.
But what is not guesswork is that the crimped Hopper GPUs and the potential crimped Blackwell GPUs that Nvidia might be working on are not going to compete well in terms of specs. Then it all comes down to yield, pricing, availability, and demand. Which we will find out about soon enough.
There is no question that China can easily consume millions of Ascend 910C accelerators. But can SMIC make them, and at what price? If not, for many customers, an Nvidia H20 or a B20, or even an L20, might have to do.
Here’s the funny bit: If there were no export controls imposed by the US government, Nvidia would have just about all of the GPU business in the Middle Kingdom today, just as it does in the rest of the world. That revenue would come back to the US, and be taxed, and Chinese companies would buy Nvidia GPUs despite China’s desire for indigenous IT suppliers because given all of the hardware and software, they are the easiest and often the best choice in most cases right now.
In a way, the US is playing right into China’s hand. And, either way, China will eventually get what it wants, and it will get it because it has the money to create technological capabilities mimicked (if not sometimes licensed or borrowed or stolen) from its eco-political rivals.
The world is messed up, isn’t it? We hate a no win scenario as much as Captain Kirk.

Nvidia NeMo Microservices For AI Agents Hits The Market
Last year, amid all the talk of the “Blackwell” datacenter GPUs that were launched at last year’s GPU Technicval Conference, Nvidia also introduced the idea of Nvidia Inference Microservices, or NIMs, which are prepackaged enterprise-grade generative AI software stacks that companies can use as virtual copilots to add custom AI …

AWS Hedges Its Bets With Nvidia GPUs And Homegrown AI Chips
There was a time – and it doesn’t seem like that long ago – that the datacenter chip market was a big-money but relatively simple landscape, with CPUs from Intel and AMD and Arm looking to muscle its way in and GPUs mostly from Nvidia with some from AMD and …
The “Hopper” GPU Compute Ramp Finally Starts
You can’t be certain about a lot of things in the world these days, but one thing you can count on is the voracious appetite for parallel compute, high bandwidth memory, and high bandwidth networking for AI training workloads. And that is why Nvidia can afford to milk its prior …
Tim,
Your are right on the mark on ultimate impact of the export ban. I just want to point out one minor mistake—there was a SXM version of A800, with 80GB of VRAM. We have one HGX A800 unit at where I work, acquired back when it was still exportable.
Interesting analysis! The PRC seems to me to be mainly executing on its 2015 high-tech-oriented “Made in China 2025” plan (MIC2025), and export restrictions probably help slow them down a bit on that path. They did develop competitive bullet trains, solar panels, 5G hardware, inexpensive EVs (sponsored?), a space program, and advanced weapons systems, that can challenge our industry as well as our relative ability to negotiate and promote win-win solutions for geopolitical conflicts worldwide (from 2018: https://www.uscc.gov/sites/default/files/Research/Jane%27s%20by%20IHS%20Markit_China%27s%20Advanced%20Weapons%20Systems.pdf ). I think that with unrestricted access to TSMC, and ASML’s High-NA EUV, they would have hopped along on that plan and developed an Ascend 910C that would have been a more compelling competitor to H100 and MI300, to our detriment (less expensive than our offerings, available to our opponents, …). The question of software might however remain, as it currently seems to influence a lot of hardware purchase decisions.
But yes, export restrictions likely strengthen the PRC’s resolve to hasten its execution of MIC2025, and the question becomes whether restrictions are sufficiently successful in offseting that drive from the technological side, until that time horizon where (best-case scenario) China becomes an ally!
The above analysis of the impact of the GPU export bans seems plausible to me. From what I can tell the ban reflects political virtue signalling rather than practical foreign policy or economic decision making.
Said another way, this is not about killing the golden goose so much as an entire flock of them.
bool sanctionsHurtChina = true;
bool americaIsHurt = false
do
{
PutMoreSanctionsOnChina();
}
while(americaIsHurt == true)
void PutMoreSanctionsOnChina()
{
sanctionsHurtChina = false;
americaIsHurt = !sanctionsHurtChina;
}
So, yeah, if your estimates for FP32 on the Huawei B and C models are correct then all I really want to know is where can I buy them and at what price.
Halfway sane power dissipation and freaking PCIe cards that fit in normal-person ISV computers. What’s not to like? AMD stopped serving ppl like me after the 210, and nVidia top end cards are priced for hyperscalers and national labs not small companies.
@Calamity Jim. Good points all. Only quibble: for AI – the claimed reason for the sanctions – if Huawei ports Tensorflow and Pytorch over then it is pretty much finished on the software front. Those two toolkits should be pretty portable.