

With each successive Intel Xeon SP server processor launch, we can’t help but think the same thing: it would have been better for Intel and customers alike if this chip was out the door a year ago, or two years ago, as must have been planned.
The new “Emerald Rapids” processor launched today – the fifth in the Xeon SP generations – is indeed the finest server CPU that Intel has ever put into the field, but it will face some pretty stiff competition from AMD’s Epyc lineup as well as from several homegrown Arm server CPUs made by the hyperscalers and cloud builders. Not to mention Arm server CPU upstart Ampere Computing.
As has been the case for the past several years, Intel will get its share of supply wins with the Emerald Rapids chips, but will do so in a server market that, excepting exuberant spending on AI systems, has been in recession for two or three quarters now, which is bad timing. But it is not just bad timing for Intel, it is “sauce for the goose” as Mr Spock says in The Wrath Of Khan, because the odds are even. AMD is having the same server CPU recession, and all of the downstream server makers are experiencing it, too – again, excepting the revenue boost from AI servers laden with big, fat GPU engines. Which don’t seem to be adding to profits for them all that much, if you look carefully, but it is making Nvidia one of the richest companies in the history of business on Earth.
The difference is that AMD has a credible GPU accelerator story in the “Antares” MI300 series launched last week and Intel doesn’t say much about its “Ponte Vecchio” Max Series GPUs and is left hawking its current Gaudi2 and future Gaudi3 AI accelerators, which are not general purpose compute engines that can go up against Nvidia GPUs and AMD GPUs in the same way. There’s no traditional HPC story, there’s no VDI story (not that people seem to care about that much), there’s no visualization story, there’s no database or analytics acceleration story, with the Gaudi devices.
And so, Intel waits back there on a super-refined variant of a 10 nanometer process called Intel 7, doing some very nice engineering in the new “Raptor Cove” core and across the common socket that Emerald Rapids shares on the “Eagle Stream” server platform with the “Sapphire Rapids” fourth generation Xeon SPs launched in January of this year. Eventually, as Intel’s foundry closes the process and packaging gap with Taiwan Semiconductor Manufacturing Co, there will be more sauce for that goose. And eventually – because there is always an eventually in the semiconductor business – Intel will be at parity in terms of cores, process, and packaging with AMD and Nvidia on the CPU and GPU fronts, and we will see the cost of compute once again take a much-needed nose dive.
We look forward to it on your behalf.
In the meantime, and without further ado, let’s talk about the Emerald Rapids lineup and keep in mind this idea as we do. When companies are stretching out the time they keep their servers in the field, it almost necessitates that they buy the highest performance machines they can get as they add some new machinery to their fleets. That way, it knocks out the highest number of vintage system footprints possible while at the same time giving the new machinery added longevity in the field because of the core, cache, and I/O a high-bin CPU can offer and a middle bin part cannot. Buying the middle bin parts, which is a common strategy in days gone by, is not necessarily a good practice under these circumstances.
With Sapphire Rapids, Intel comprised a socket of four chiplets for its high-end Extreme Core Count (XCC) variant, which had an HBM memory option for HPC customers. These four chiplets each had 16 cores, for a total of 64 across the socket, and only 60 of them were exposed for yield purposes. There was also a Medium Core Count (MCC) monolithic chip variant that scaled up to 32 cores, which was used to flesh out the bottom half of the 52-chip strong Sapphire Rapids SKU stack.

With the super-refined 10 nanometer process, Intel can make bigger chiplets and get higher yield on ones that are the same size and get even better yield on smaller chiplets, and so it has chosen to create Emerald Rapids with three different die packages, as you see above.
On the top-end, there are two chiplets each with what appears to be 34 or 35 cores each in a grid of 7×5 cores (one may be popped out for memory controller space), for a total of 60 or 70 cores, with up to 64 of them exposed for yield. This is the XCC variant, and this time around there is no HBM option for the HPC crowd. Sorry. The XCC has 61 billion transistors.
The MCC die for Emerald Rapids has up to 32 cores exposed to the outside world, and probably has 36 cores in the design, again to improve yield. There is an energy efficient Low Core Count (EE LCC) variant with up to 20 cores exposed to the socket pins and with probably 24 cores actually on the die.
We have asked for but do not yet know the transistor counts of the MCC and EE LCC variants.
The Eagle Stream platform’s LGA-4677 server socket was not heavily populated with silicon during the Sapphire Rapids generation, but with the top bin part, Emerald Rapids is filling it up rather nicely:

The core count is a modest increase, from 60 with the top bin Sapphire Rapids chip to 64 with the top bin Emerald Rapids, but the XCC variants have as much as 320 MB of L3 cache on chip compared to the XCC for Sapphire Rapids, which maxxed out at 112.5 MB.
The UltraPath Interconnect (UPI) NUMA links coming off the Emerald Rapids socket have been boosted to 20 GT/sec speeds, up 25 percent from the 16 GT/sec speed of the UPI links on the Sapphire Rapids chip. Like Cascade Lake, Emerald Rapids is only designed for machines with one or two sockets. So if you want a four-socket or eight-socket box, you have to use Sapphire Rapids until the sixth gen “Granite Rapids” Xeon SPs, which we talked about in detail back in September, come out next year. If you can wait for Granite Rapids for a big NUMA box, you should.
The Emerald Rapids chip also supports the CXL 1.1 coherent memory protocol, which allows for the PCI-Express ports on the chip to support Type 3 CXL memory as an extender to the on-chip DDR5 main memory.
As for instruction per core improvements in the Raptor Cove core, Intel says that the average performance gain moving from Sapphire Rapids to Emerald Rapids across High Performance Linpack, STREAM Triad, SPECrate2017_fp_base, and SPECrate2017_int_base is 1.21X. That is not precisely a clock normalized per core measure. The tests with the 1.21X performance jump were run on a pair of Emerald Rapids Xeon SP-8592+ chips with 64 cores, presumably running at the all-core Turbo speed of 2.9 GHz and a pair of Sapphire Rapids Xeon SP-8480+ chips with 56 cores. If you multiply out the cores and the clocks for those two processor complexes, just these two factors alone give you a 10 percent boost, and maybe the faster UPI 2.0 links help a bit, too. But assume they don’t. Then the real IPC gain, normalized for the same clock and the same core count, is more like 11 percent. That is admittedly a guess.
And so, without further ado, here are the 32 new Emerald Rapids Xeon SP processors:
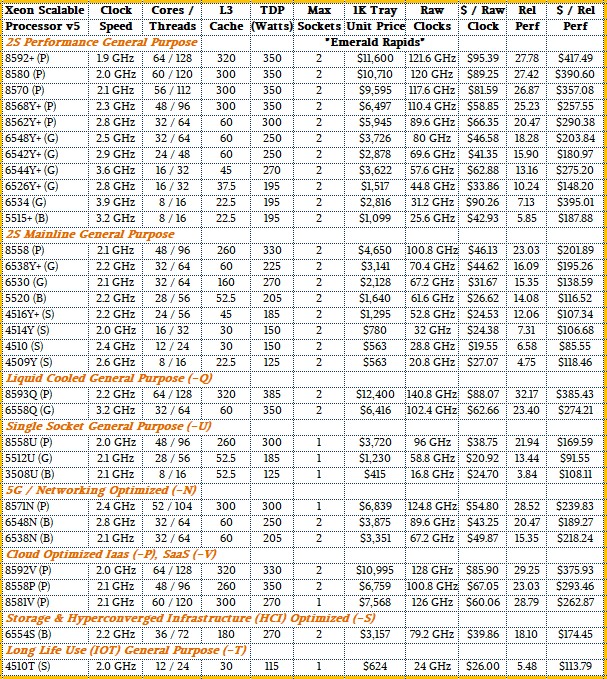
In terms of SKU stack diversity, the Emerald Rapids line, at 32 official variants, is a lot less wide and deep than the Sapphire Rapids lineup at 52 variations. The first gen “Skylake” Xeon SPs had 51 variants, the second gen “Cascade Lake” Xeon SPs had 45 variants plus 18 kickers with the “Cascade Lake R” deep bin sort plus the “Cooper Lake” tweaks for four-socket and eight-socket servers that sort of added another 11 variants to the 63 variants of Cascade Lake proper for a total of 74 variants. Even the ill-fated and long-delayed third gen “Ice Lake” Xeon SPs had 38 variants.
Speaking very generally, the Emerald Rapids chips offer from 1.13X to 1.69X more oomph on a wide variety of datacenter workloads, and deliver an average of 1.34X better performance per watt. The thermals are particularly good for idle power, with on the order of 100 watts in power draw at idle times. (To which we say: Why is a server chip ever idle? Find things for it to do.)
Some of that performance bump is not just coming from cores, but from higher memory bandwidth, as the Emerald Rapids CPUs support 5.6 GHz DDR5 memory compared to the 4.8 GHz DDR5 memory used in Sapphire Rapids, yielding a 16.7 percent increase in memory bandwidth. Both chips had eight memory channels, so there is no increased bandwidth from adding more memory channels to the compute complex, but there is support for CXL memory expansion, often called Type 3 CXL memory, that gives another four channels of CXL memory and additional bandwidth. You can use that CXL memory in two ways:

It is not clear how CXL memory has been used to boost benchmarks for the Emerald Rapids systems that Intel tested, if at all. We will try to sort that out. We will also do our usual architectural deep dive, price/performance comparisons with prior Xeon and Xeon SP generations, and competitive analysis against AMD Epyc and Arm server CPUs.


AMD Feels The Server Recession, Too, But Growth Is Looming Large
With a server recession underway and its latest Epyc CPUs and Instinct GPU accelerators still ramping, this was a predictably soft, but still not terrible in the scheme of things, quarter for AMD. But the company is projecting that its datacenter business will still have somewhere around 50 percent growth …

The Cheapest Compute In The Intel Xeon Lineup
While the minimalist server processor — and the microserver concept that was based upon it — did not take over the datacenters of the world, there are still some workloads that can fit in modestly powered single-socket CPUs just fine. That is why Intel has always created server variants of …

With Vista, TACC Now Has Three Paths To Its Future Horizon Supercomputer
The national supercomputing centers in the United States, Europe, and China are not only rich enough to build very powerful machines, but they are rich enough, thanks to their national governments, to underwrite and support multiple and somewhat incompatible architectures to hedge their bets and mitigate their risk. In the …
Nice introduction and analysis! I like these emeralds as they are gemologically less expensive than sapphire (and ruby), yet very resilient, and perfect for everyday wear (good naming on Intel’s side). I imagine that Type 3 CXL memory might find uses for very large databases or AI model weights (maybe that’s how 3D XPoint is advantageously replaced?). Also, if the Mixture of Chefs approach to AI pans out (salad chef, entrée chef, pastry chef, fromager, sommelier, …) then the AMX and large caches on these chips could prove quite useful. The goose could be sauced while the soufflé bakes and the salad is tossed (for example), each on their own node, socket, or subset of cores. I think it sounds delicious (to paraphrase other computational gastronomers)!
“as Mr Spock says in The Rath Of Khan” – I’ve never seen this film, but it’s probably similar to the film “The Wrath of Khan”.
But of course… funny how the AI-infused spell checker didn’t note that.
The core clusters in Sapphire Rapids XCC were arranged as 4×4 with one removed for the memory controller. Thus the 60 core pairs are full enabled and not binned down parts. Intel originally targeted 56 cores max SKUs but due to delays and ever increasing yields, was able to produce enough volume of 60 core out there. Emerald Rapids XCC is indeed a 5×7 arrangement but two cores removed and replaced with memory controllers this time. Thus each chiplet has a maximum of 33 cores. Thus the 64 core parts are binned down a bit from the 66 theoretical maximum.