
It is always interesting to us when technologies developed in one sector of the IT market get adapted and cross-pollinate in interesting ways to solve problems in another sector of the IT market. It is one of the founding principles of this publication, in fact.
This has just happened as DriveNets, a maker of distributed core routing software that runs on Broadcom ASICs and that works at Layer 3 in the network protocol stack, has created a Layer 2 switching variant of DriveNets Network Operating System (DNOS) aimed explicitly at providing a performance boost for AI training and inference workloads atop Ethernet.
By the way, this is precisely what Hillel Kobrinsky, DriveNets co-founder and chief strategy officer, told The Next Platform back in February 2021, when the company had bagged $208 million in Series B funding, said DriveNets would not do. At the time, and after five years of development of a disaggregated and distributed routing platform, Kobrinsky was adamant that DriveNets was not going to follow Arrcus, Cumulus Linux, and others into switching and moreover said that the company was going to focus exclusively on the service provider and hyperscaler part of the market. We were skeptical at the time, which is why we wrote about them at all, given the unique cell-based architecture that DriveNets had come up with to create a distributed routing platform – meaning, one that ran on leaf and spine switches, not on big, expensive, modular boxes that hard-wire the interconnects between fabrics and line cards to create a big routing platform called the Distributed Disaggregated Chassis, or DDC for short. It was good enough for AT&T to deploy DNOS at the heart of its Network Cloud.
Well, it looks like the AI training and inference opportunity for generative AI workloads – which is extremely network heavy – was too big and juicy to pass up for DriveNets. And is for just about every other IT vendor on the planet. That AI opportunity and the inability of Ethernet to compete with Nvidia’s implementation of InfiniBand for modestly sized clusters in terms of low latency and traffic shaping and Ethernet’s much higher scalability are what compelled Microsoft, Meta Platforms, Broadcom, Hewlett Packard Enterprise, Cisco Systems, and Arista Networks to form the Ultra Ethernet Consortium back in July of this year.
But you don’t have to wait years for these companies to come up with ways to make Ethernet more like InfiniBand while also preserving its vast scale. Yuval Moshe, senior vice president of products and head of AI/ML solutions at DriveNets, said that Broadcom asked DriveNets to take a look at putting Layer 2 switching in DNOS and running it on a mix of Jericho 3-AI switch ASICs and Ramon 3 fabric elements to create a distributed, modular switch with cell-based data transport that is the heart of DNOS – and that was developed specifically for telcos and service providers who have stringent latency and high bandwidth requirements – between the elements of the network rather than the Ethernet protocol.
That cell-based communication is akin to the coherent memory protocol that was first used on NUMA servers back in the late 1990s and early 2000s; in a sense, this is NUMA networking instead of NUMA compute. It implements a kind of packet spraying that is key to deterministic performance and adaptive routing, which Broadcom was talking up in its Jericho 3-AI launch in April and Cisco Systems was talking up in its G200 launch in June. Because of this cell-based architecture, says Moshe, DriveNets can drive performance and it can do hardware-assisted error detection and failure mitigation to route around failing GPUs in a network – something that the telcos and service providers require in their routing.
“The biggest thing that the hyperscalers and cloud builders have on the table is if there is a failure,” Moshe says. “The DDC can handle that – there is oversubscription speed up between the line cards and the fabric and it has an end-to-end view of the system. So you’re not impacting the entire system, you wouldn’t have impact in all the specific flows.”
As far as the GPUs know, they are talking to Ethernet on the front end of the network and they never see the cell-based protocol that is inherent in the DNOS software stack from DriveNets and that links the Ramon 3 fabric elements to each other and to the uplinks on the Jericho 3-AI switch/router ASICs.
This is ability to handle failures is important because DriveNets wants to work with whitebox network gear makers who will peddle Jericho 3-AI/Ramon 3 devices in a virtual switch that can scale to 32,000 GPUs and deliver lower job completion time on AI training runs than other Ethernet setups can do. That 32,000 GPU scale is inherent in the Jericho 3-AI and Ramon 3 design, by the way, and assumes a three-level Clos topology with 144 ports running at 800 Gb/sec coming off the Jericho 3-AI downlinks and 160 ports reaching up to a two-layer Ramon 3 spine and aggregation network. Here is how Broadcom showed it back in April:
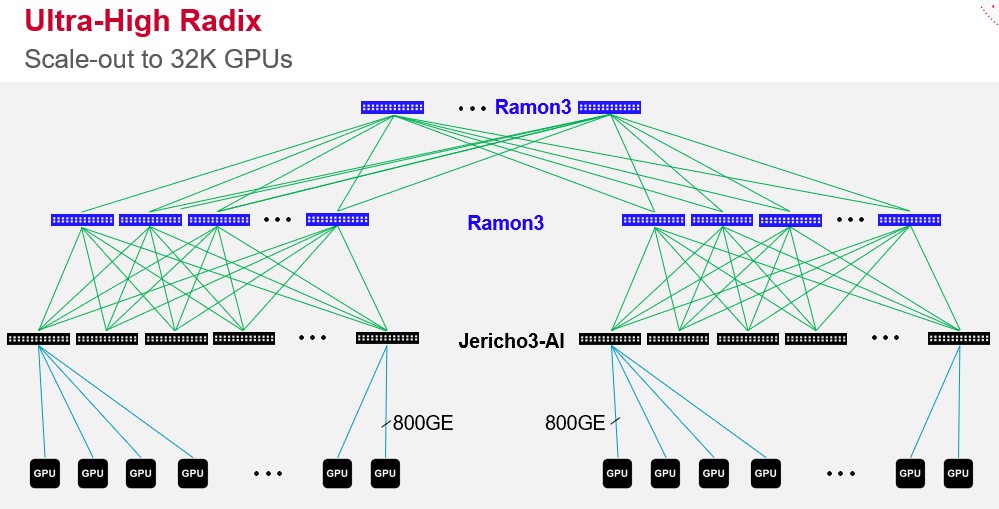
Those who need higher radix switches to create similarly flat networks that scale to more GPUs will have to either cut down on the downlink bandwidth to each GPU or add another layer of networking, which will increase latency between the GPUs. Or wait for Jericho 4-AI, Jericho 5-AI, and such as more bandwidth is delivered in these devices and can be allocated either as increased port speed or increased radix or a mix of the two.
That cell-based network embedded in the DNOS software stack from DriveNets also allows for a fully scheduled fabric across the Jericho 3-AI and Ramon 3 devices, which is something that cannot be done with normal Ethernet leaf/spine switches today. Regular Ethernet switches in a Clos topology that is typical with the hyperscalers and cloud builders have flow-based load balancing and relatively shallow buffers in the typical ASICs they deploy from Broadcom and others; they also support Equal Cost Multi-Path, or ECMP, for load balancing, which is known to help but which is also very tough to implement and tune and a bit brittle, according to the people in the know that we have spoken to over the years.
To try to figure out how its DNOS software and the Broadcom hardware would perform, DriveNets and Broadcom tapped Scala Computing, which has simulators that can model the behavior of networks and compute infrastructure, and pit a network of 2,000 GPUs based on the Jericho 3-AI and Ramon 3 stack against a similar Clos network based on the “Tomahawk 5” StrataXGS ASICs also from Broadcom and using a homegrown networking stack like those in use at Amazon Web Services, Meta Platforms, Google, and Microsoft. No one has 2,000 GPUs laying around to test, or even the right number of switches based on the latest Broadcom ASICs, so simulation is necessary at the moment.

With the simulators – as well as with pencil and paper if you wanted to do it – you could scratch out what would be the idealized performance of the compute and networking assuming a full, non-blocking mesh interconnect of the network. And then, in the case of DriveNets, you have to run the AI simulations and compare how different networks and different workloads measure up against this idealized performance. Using the Scala Computing emulators, here is how the Jericho stack running the DNOS from DriveNets stacked up to a generic Clos network based on Tomahawk 5:
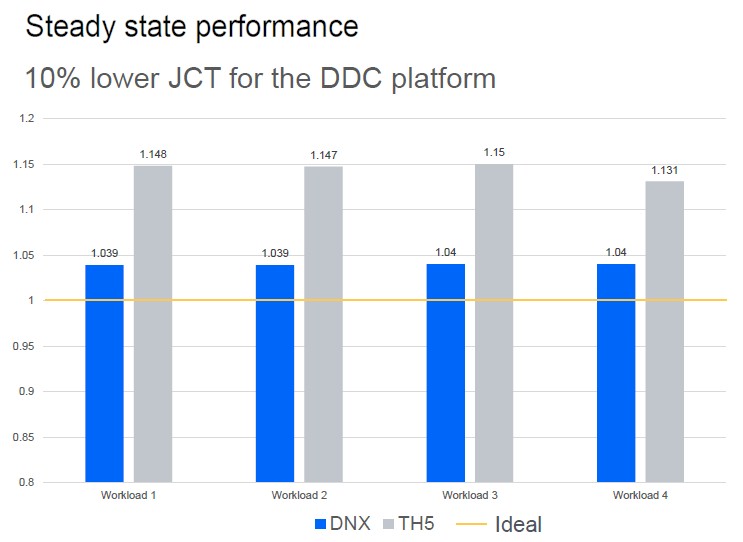
Thre are four AI/ML training workloads (which were not divulged to us) that are doing collective reductions based on Nvidia’s NCCL MPI acceleration library in a dual B-tree using RoCE to bypass the network driver on the host systems and reduce the latency. The simulation runs at 400 Gb/sec on the ports.
Speaking generally, the fully schedule fabric based on DNOS and Jericho 3-AI/Ramon 3 delivered about 10 percent lower job completion time on the four AI workloads tested. Those AI workloads are running in series, not in parallel, by the way.
Now, things do not always work out in networking, as you well know, and clusters often have to share iron across workloads and run in parallel. They are not steady state and isolated, and there are noisy neighbors that affect the performance of the network and therefore of the compute. In the Clos network, if you have to cut back a single network interface because the application is chatty, then there is network impairment on all of the network interfaces across the 2,000 machines. (Yes, this seems silly.) And as a result, a noisy neighbor affects the performance of all of the four AI workloads running at the same time on the cluster. Like this:
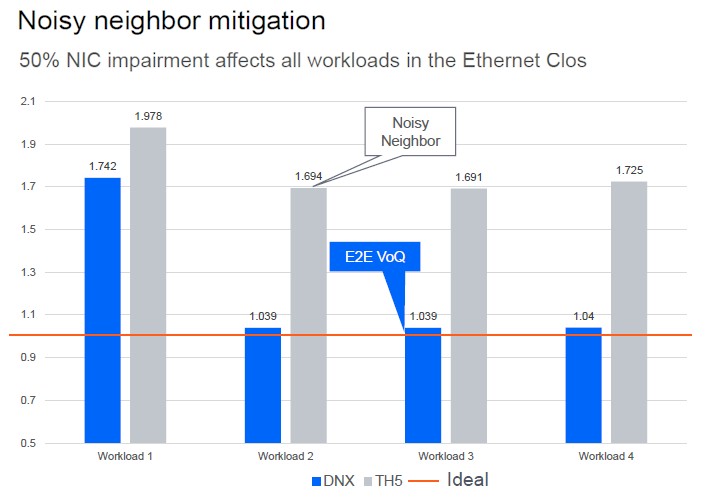
The workload that is the noisy neighbor certainly affects the performance of itself on the simulated cluster, but the other three workloads do not have NIC impairment and go about their business on the DNOS stack running on the StrataDNX ASICs. Not so on the StrataXGS ASICs that are running a more generic NOS, as you can see.
The Edgecore Networks whitebox switching and routing division of Accton Group is sampling iron now and is working with DriveNets on customer trials, and others will no doubt be shipping their switches and routers based on Jericho 3-AI and Ramon 3 within a couple of quarters, Moshe tells The Next Platform.
It will be interesting to see how this all stacks up against Nvidia’s NVSwitch inside of the HGX GPU modules and its 800 Gb/sec InfiniBand across HGX modules.

Why There’s Hard, Cold Cash For Soft, Disaggregated Routing
No matter if you are talking about compute or networking, there are two opposing forces that are constantly at interplay on a field of green money. The first force is the desire to implement as many specialized functions in transistors to accelerate the performance of those functions. The other force …
“InfiniBand Too Quick For Ethernet To Kill”
https://www.nextplatform.com/2015/04/01/infiniband-too-quick-for-ethernet-to-kill-it
It was true in 2015
It is true in 2023
If you argue history, as I did then and have since 1999 when InfiniBand was created, and way before then when Token Ring ran out of scale, you’re right. But Token Ring was arguably better and lost because of latency and scale issues. And if you can’t scale InfiniBand to 100,000 endpoints, like hyperscalers do already in their datacenters with their Clos networks, then a latency benefit is not the be-all, end-all. This time, Ethernet has a chance unless InfiniBand can be extended.
Noisy neighbor mitigation is definitely key to running AI workloads (or any multi-nodal workload really) efficiently in cloudy environments. It’s good to see that DriveNets can produce effective disaggregation and workload-focused recomposition of the underlying hardware (network+compute) with its software orchestration of network management microservices (Docker containers) with successful “sound proofing” of individual multi-node tenant workloads … Good Job!
Hmmm “ULTRA ETHERNET” one must wonder how well such terms age in Tech Space…In the peak of my Sun/Solaris days (late last millennium thru early this century) I installed many a “QFE” (Quad Fast Ethernet (4-port card)) card…”Fast” as in 100 Mbits (1/10 my current cable-based broadband to home download speed).