
People have been talking about CXL memory expansion for so long that it seems that it should be here already, but with the dearth of CPUs that can support PCI-Express 5.0 peripherals we have to be patient a little bit longer.
To whet the appetite of system architects who will without a doubt want to extend the memory capacity and bandwidth of their systems by harvesting PCI-Express slots for main memory, Samsung Electronics, which would be thrilled to sell a lot more DRAM chips into the datacenter, was showing off its CXL Memory Expander card at the Hot Chips 34 conference this week. Sung Joo Park, principal engineer at Samsung, gave an overview of why we want to do bandwidth and capacity expansion in systems – something we have talked about at length here, there, and everywhere.
Last year, Samsung was showing off a prototype of its CXL Memory Expander that was based on 128 GB of DDR4 DRAM running at 3.2 GHz, that used a Xilinx Kintex FPGA as a CXL memory controller, and that plugged into a pretty slow PCI-Express 3.0 x16 slot in a server. The performance of this device was not great, as you might expect, in a lot of use cases, but it did fine in others and it set the stage for the eventual delivery of much faster PCI-Express 5.0 ports on servers – which have 4X the raw bandwidth of the PCI-Express 3.0 slots with the same number of lanes – as well as much higher performance from DDR5 memory.
With the commercial CXL Memory Expander card that is being revealed this year, Samsung engineers are putting 512 GB of 4.8 GHz DDR5 main memory on the card – a total of 40 chips, with 20 on each side of the printer circuit board – and are using a custom ASIC CXL memory controller that has been designed from the ground up to handle the higher speeds of PCI-Express 5.0 and DDR5 as well as to support the CXL 2.0 protocol.
This new CXL memory card only needs a PCI-Express 5.0 x8 slot to keep all of that memory fed with 32 GB/sec of bandwidth, which is still twice the 16 GB/sec of bandwidth that the prototype CXL memory card could push over 16 lanes running at PCI-Express 3.0 speeds. That’s 2X the bandwidth in half the lanes, which is good because servers only have so many spare PCI-Express lanes after plugging in networking and other peripherals. We also presume the ASIC is considerably faster than the FPGA as well as supporting a more refined implementation of CXL, and Park said in his presentation that Samsung was still refining its firmware so squeeze more performance out of that ASIC.
Here is what the commercial-grade product looks like:
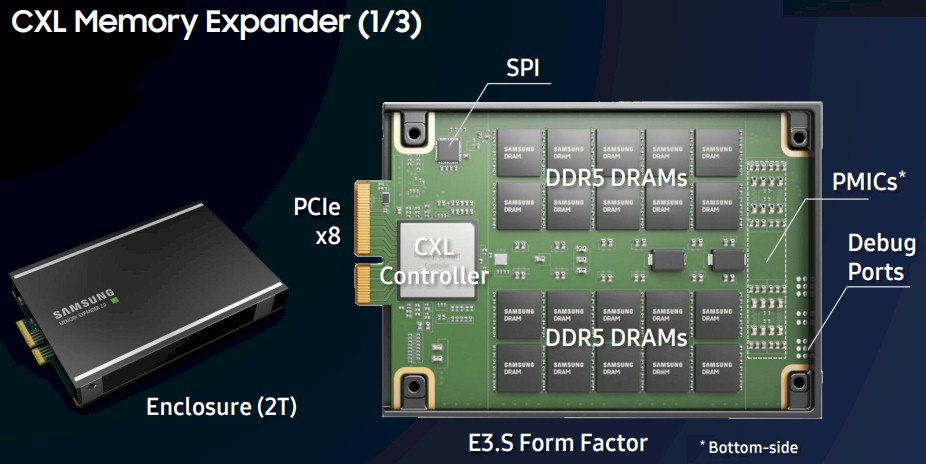
The card is using an EDSFF E3.S form factor, which is one of several enclosures being used for flash and DRAM modules that plug into PCI-Express slots.
Technically speaking, this is a CXL Type 3 device, which means it supports the CXL.memory sub-protocol and is used as a byte-addressable device that uses the PCI-Express bus as a transport for data but which does not use the PCI-Express I/O protocol to talk to memory. The CXL.memory driver basically makes the PCI-Express electrical transport look and feel like a NUMA shared memory link in a multi-processor server that just so happens to not have any cores on it. The ASIC for the device has a slew of error detection and correction features needed for main memory, including:
- Viral and data poisoning, which is marking bad chunks of memory so they can be dealt with;
- Memory error injection, which is used for testing and verifying memory;
- Multi-symbol error correction code, which detects and corrects multiple bit errors when memory is running;
- Media scrubbing, which is going systematically through data in memory, finding bit errors due to cosmic rays or alpha particles ripping through the bits, and correcting them proactively as the system is running; and
- Hard and soft post package repairs, which is when spare memory rows in the DRAM chips are invoked to fix a failing memory location on that DRAM.
If you want to use the Samsung CXL Memory Expander, you need a server that supports PCI-Express 5.0 x8 slots, which are required to support the CXL 2.0 protocol. If you want to be adventurous, and there is no reason not to be, you could buy a new IBM Power System server based on its “Cirrus” Power10 processors, which just started shipping in July. Sometime before the end of the year, you will be able to get a server based on AMD’s “Genoa” Epyc 7004 processor, which also supports PCI-Express 5.0 slots, and of course, Intel is expected to ship its “Sapphire Rapids” Xeon SP processors this year, but we keep hearing rumors that it is delayed. Both Genoa and Sapphire Rapids will be in the hands of hyperscalers, cloud builders, and select HPC centers and large enterprises long before official launch dates, of course.
In any event, Samsung will start shipping the CXL Memory Expander in the third quarter of this year to early evaluation customers – meaning those who can get their hands on servers with these chips.
To make use of the CXL Memory Expander, you need to load up the Samsung Scalable Memory Development Kit, which is a set of tools to create software-defined memory across the directly attached and CXL attached memories in the system. Here is the block diagram outlining this SMDK:

There is a compatible mode that works without any modification to the application software, and an optimized mode that does require some modifications. The extent of those modifications or the performance enhancements they enable was not revealed by Park. This SMDK runs in user mode for Linux operating systems, which is in contrast to the kernel model tweaks that Meta Platforms has done with its Transparent Page Placement (TPP) protocol, which we discussed here back in June. Park said that Samsung is considering how it might open source this SMDK stack.
Everyone wants to know what the latency is on such devices, and in the Q&A session after the presentation, Park said that right now the latency out to the CXL memory was around 130 nanoseconds and that the company hopes to get it below 100 nanoseconds with some tuning. That’s pretty impressive, and we don’t quite believe it because that sounds magical. But there is plenty of magic in systems, so there is that.
While raw latency and bandwidth numbers are interesting, what matters is how applications perform when they used CXL expanded memory. And Park brought some early results to show the benefits of the device.
To gauge memory bandwidth, Samsung used Intel’s Memory Latency Checker test as well as the copy portion of the STREAM memory bandwidth benchmark, and normalized the performance of its prototype and commercial CXL Memory Expander cards against DDR5 memory running in what we presume is a server using early versions of the Sapphire Rapids processor from Intel. Here are these results:

While it is interesting that the second generation CXL memory card from Samsung is nearly five times as powerful as the prototype in terms of memory bandwidth, what matters is how the CXM memory using the custom ASIC fares against using directly attached DRAM. And the answer is, on average, the CXL memory is delivering about 90 percent of the bandwidth as the same capacity of DDR5 memory.
That’s pretty good, and with lower latency and other tweaks, we bet Samsung can get it to 95 percent, and maybe even higher. Which is not only close enough for government work, but close enough for all work.
Now here is another interesting set of data, this one showing the relationship between memory capacity and bandwidth in a server running BERT and NASNet AI inference models and scaling up a server with an increasing number of CXL memory expansion cards. We don’t know what the maximum number of cards denoted by k in the charts stands for, but we would guess that it is somewhere around eight CXL memory cards in a server.

Considering how expensive DDR memory is – and CXL memory expanders are not going to be cheaper per unit of capacity – it is hard to say if adding so much memory to boost performance makes sense. But clearly adding the memory boosts performance, and particularly so for the BERT model for natural language processing that came out of Google likes memory. NASNet, which is used for image processing, seems to be less sensitive to memory capacity and bandwidth. You will note that the performance difference between the FPGA-based CXL memory card prototype and the ASIC-based CXL memory commercial product from Samsung is not as dramatic as it was on the memory bandwidth tests above.
This next test, using the Redis in-memory key-value store as a workload, not only shows the benefit of adding CXL memory to a server, but how you can consolidate servers and boost performance at the same time, all with the same 96 GB of capacity for Redis to play in on machines:
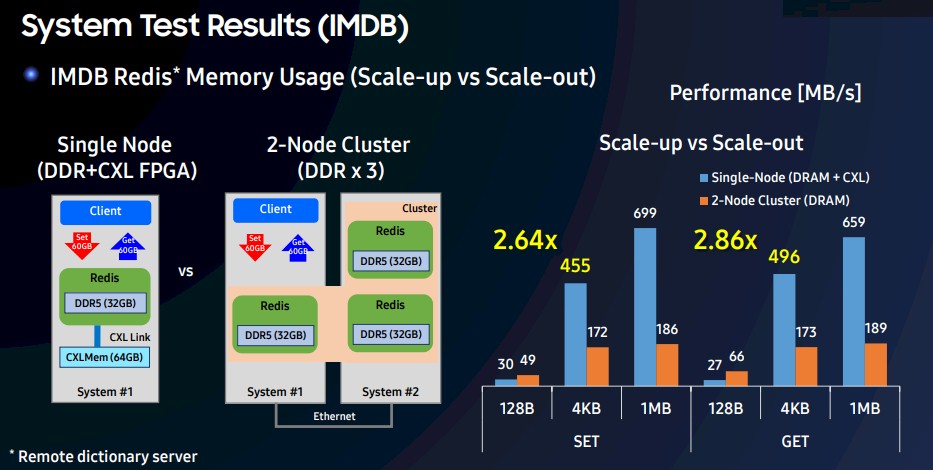
In this benchmark, a two-node server interlinked with Ethernet is running Redis in three 32 GB partitions and the Redis client in a fourth is pitted against a single node that has the Redis client in one partition and the Redis datastore in another partition with 32 GB in direct DRAM memory and 64 GB in CXL memory in a single partition.
The chart shows the rate of SET and GET commands in Redis in MB/sec, and as you can see, the single node with a mix of DRAM and CXL memory beats the socks off the two-node server with the same memory capacity. The average performance increase across data sizes is 2.64X for SET commands and 2.86X for GET commands.
It is not clear if the same server consolidation angle would work for AI inference workloads like BERT and NASNet, but it stands to reason that it might.
Perhaps, as CXL takes off, we can get some intense competition going among the DRAM makers to bring the cost of memory down and the system memory capacity way up. But we think it is far more likely that when the CXL 3.0 protocol and the PCI-Express 6.0 interconnect is out that such memory expanders will be used to create shared and pooled memory servers that will sit in the server and switch racks, allowing for overall memory utilization across a group of machines to be driven way up and the overall spending on memory in datacenters somewhat down.

Ventana Launches Veyron V2 RISC-V Into The Datacenter
It took the X86 architecture fifteen years get an appreciable share of datacenter compute, and it took the Arm architecture about ten years to get a foothold you could measure. Perhaps it might only take five years for the RISC-V architecture to do the same because the hyperscalers and cloud …
The Mass Customization Wave Is Starting For Servers
Remember when only a couple of variations of processors were available for servers in any given generation of server CPUs? There might have been dozens of vendors, but they didn’t give a lot of choice, Today, we have a handful of server CPU designers and only a few foundries to …
The Server Recession Ends, And Both Intel And AMD Won
Anyone who thinks that Intel is easy to kill need look no further than the historical trends of the Mercury Research market share statistics that we see each quarter. Data for the third quarter of 2024 was just announced, and we have paired this with historical trends in shipments and …
The memory expander product seems at least 12 months away from general availability
As far as I understand, Park meant the additional latency of the CXL memory controller is 130 ns (and will be lower than 100 ns in the future) instead of the total latency of CXL memory (source: https://www.youtube.com/watch?v=YujDbndqqVQ from 1:46:19)