
More databases and data stores and the applications that run atop them are moving to in-memory processing, and sometimes the memory capacity in a single big iron NUMA server isn’t enough and the latencies across a cluster of smaller nodes are too high for decent performance.
For example, server memory capacity tops out at 48 TB in the Superdome X server and at 64 TB in the UV 300 server from Hewlett Packard Enterprise using NUMA architectures. HPE’s latest iteration of the The Machine packs 160 TB of shared memory capacity across its nodes, and has an early version of the emerging Gen-Z protocol. Intel’s Rack Scale architecture will eventually pull the compute, memory,, storage, and I/O resources out of servers and pool them into discrete boxes, which will be linked via high-speed interconnects based on emerging protocols, just like The Machine.
But there may be a simpler way.
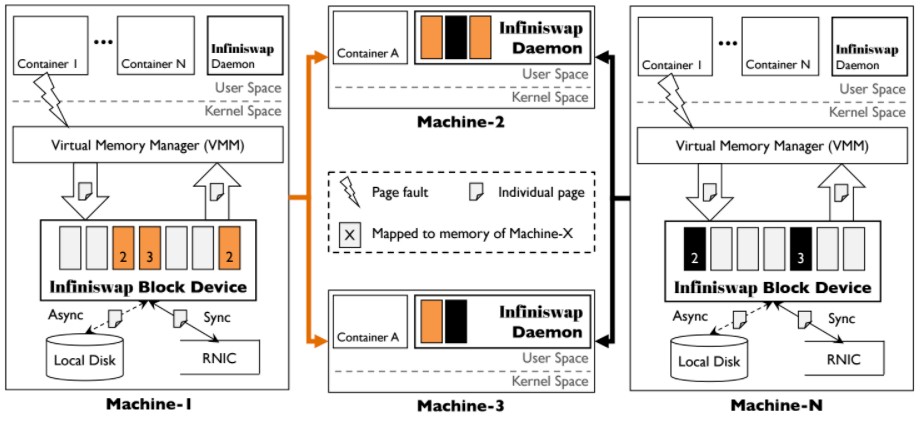
Researchers at the University of Michigan think they can resolve the issue of creating a large pool of memory for applications without making big changes to hardware or software. The researchers have come up with something they call Infiniswap, which is an open source program that sits in the Linux kernel and pools memory across different servers nodes using the Remote Direct Memory Access (RDMA) protocol that was initially created to accelerate HPC applications on InfiniBand networks but which has since been ported to Ethernet and is used in a number of database and storage clustering applications these days.
The goal behind Infiniswap is to make efficient use of memory resources across a cluster, with nodes using each other’s memory capacity as a swap file and raising their effective capacity as far as applications are concerned as they run on each node.
Infiniswap is a memory paging system that maps out remote memory on a RDMA network and harvests it to speed up the processing of in-memory datasets typically associated with applications like databases. In typical servers, when memory runs out, space is cleared by writing data to disk. Infiniswap instead accesses free memory from remote systems to process large in-memory datasets. It does so by bypassing the remote CPUs and by leveraging the RDMA functions in network interface cards, creating a decentralized memory network that can be harvested when needed.
An experiment conducted by the researchers at University of Michigan ran Infiniswap with the Linux 3.13 kernel on a cluster of 32 servers using 56 Gb/sec ConnectX-3 InfiniBand adapters from Mellanox and matching switches to link the nodes. Infiniswap was implemented as a daemon and a virtual memory block device on all 32 servers. The daemons allocated and managed memory, while the block device interfaced with the kernel to distribute data blocks to remote memory via RDMA, which is a high-speed, low latency communications protocol to communicate directly with remote memory.
Infiniswap can expose the distributed memory of a cluster without any changes to software or hardware. It will just work if you have the Linux operating system and an RDMA network. By comparison, mass hardware changes to disaggregate networking, memory, and storage and then pool them together – which is a key component of Intel’s Rack Scale design – could cost millions of dollars to implement.
Beyond InfiniBand, which is popular in high-performance computing, Infiniswap will also work on RDMA over Converged Ethernet (RoCE), which is being used by many cloud providers like Google and Facebook, Mosharaf Chowdhury, assistant professor at the University of Michigan, tells The Next Platform. In conventional servers, if a memory limit is reached, it will swap out data in-memory and write to disk, which adds latency. Infiniswap cuts the latency by reaching out to remote memory on other servers, which still takes less time than reaching out to local disk drives.
“As long as we have extremely low latency, it doesn’t matter. We will support multiple technologies,” Chowdhury says.
The key to efficient usage of Infiniswap is to ensure all the memory resources are utilized and balanced out properly. From a systems point of view, no special hardware is needed to implement Infiniswap. The researchers used a load balancing technique from the 1990s based on a novel principle called the “power of two,” which involves comparing the available memory in two machines. For remote memory allocation, two random servers are picked and the kernel tells the virtual memory block devices it wants to write the data to the memory on the least loaded server. If the remote memory on both servers is fully loaded, it will move to another set of servers. If the memory blocks on all the remote servers are loaded, Infiniswap won’t do anything.
In a typical scenario, there is a lot of open memory space spread across a cluster, and such a technique can load balance memory usage across many servers. Infiniswap does not use conventional load balancing techniques that could involve a central controller, which knows everything about systems in a cluster and helps load balance. The central controller takes on more load as the performance of an applications scales, and that could become the bottleneck on a network.
The researchers tested Infiniswap with VoltDB, PowerGraph, GraphX, Memcached, and Apache Spark, and tried to create a real-world cluster very similar to the ones used by Facebook and Google in their datacenters (albeit considerably smaller). Google and Facebook typically assign memory resources based on conventional allocation techniques, where the companies assess the workload and build server resources like memory and storage around that. The researchers wanted to see how Infiniswap would perform in such datacenters without conventional allocation techniques. The results were positive, with memory utilization improving by 42 percent, and a 16 times improvement in throughput.
In-memory processing is wonderful, Chowdhury explains, until the dataset doesn’t fit in memory and you have to swap out to disk. To illustrate this principle, the Michigan researchers ran these three benchmarks, cutting back the memory by 25 percent and then by 50 percent, with adverse effects on the performance. Take a look:

And this is what happened on the same tests with Infiniswap turned on for the cluster:

The Infiniswap experiment was small by comparison to the scale at which Microsoft, Facebook, and Google operate. But in an actual cluster, it is difficult to load balance as it is hard to project memory usage. Facebook and Google have high variances, and depending on workloads could underutilize remote memory. It is also easy to underestimate or overestimate memory requirements across servers, but no company wants to be shorthanded and underallocate resources. That’s typically where Infiniswap fits in – you won’t have to worry about load balancing.
The software has its own quirks. In addition to writing to remote memory, Infiniswap creates a copy of the data block on local storage, ideally a fast flash SSD linked to the system using NVM-Express. That is more of a failover mechanism to ensure that if the remote memory fails, it can pull the data from the storage and rewrite it other remote memory. Failure of remote memory could lead to a momentary degradation in performance as it could take time to pull the copy of the data from storage and find other remote memory in which to plug the data. That is one of the disadvantages of Infiniswap, though the researchers are trying to overcome that problem with a new implementation involving a highly distributed memory system in which data blocks are broken up over more servers with some assistance of remote CPUs. A paper on that will be forthcoming, but that has the disadvantage of relying on remote CPUs, which is not the case with this implementation of Infiniswap.
Exposing a larger memory bank over an RDMA network is only advantageous. Infiniswap cuts the requirement to change datacenter designs, and companies don’t have to budget to buy new hardware. But there are big changes in server designs coming. HPE is pushing in-memory computing with The Machine, which is still years away, but that also brings with it a new programming model, hardware, and interconnect. Given the flexibility of Infiniswap, nothing precludes Infiniswap from working also across multiple instances of The Machine. “The Machine is competitor, but also complementary. The Machine is exposing interfaces, and could use Infiniswap as a component,” Chowdhury says.
It is still the early days of experimentation with Infiniswap, and the next step for the researchers is to put the software to practical use. They are talking to high performance computing users at the university, who are having problems with computer memory. Another goal is to get the technology to cloud providers, but whether a Facebook or a Google would adopt this technology remains to be seen. Another goal is to get Infiniswap to work with unified CPU and GPU memory. Chowdhury is trying to apply Infiniswap to distributed deep learning models, which needs low latency communication to unified memory on GPUs. His team is working with Microsoft on CNTK and is also testing with Google’s TensorFlow.

They could try to add LZ4 compression algorithm to the mix. Also a new branch covering a dynamic RAM Disk spread all over the machines in an HPC environment makes sense.
It’s not “the power of two”, it’s “the power of two choices”.
and it’s all fun and games until someone bumps an ethernet cable and corrupts your database. There are reasons this hasn’t been done.