

There may not be as much structured data in the world as there is unstructured data, but one could easily argue that the structured data – mostly purchasing transactions and other kinds of historical data data stored in systems of record – is at least of equal value. And therefore, machine learning training and therefore inference needs to be informed by this key information source.
Extracting this data and merging it with unstructured data for machine learning models is a big pain in the neck, and that is why cloud-based data services have created extensions to their database services that allows for native machine learning training to run natively on database tables without having to go through that hassle.
Oracle doesn’t want for the AI wave to leave it behind, and in late 2020 rolled out its MySQL HeatWave cloud database aimed at running analytical workloads, a key area for machine learning. Less than a year later, Oracle introduced Autopilot to HeatWave, using machine learning techniques to automate such functions as provisioning, data loading, error recovery, and scheduling.
This week, Oracle took the big step, bringing machine learning into the HeatWave database. The move automates all the steps in the machine learning lifecycle, keeps all the trained models inside the database, and eliminates the need to move any of the data or the machine learning model outside of HeatWave.
All this reduces the complexity, costs and time associated with machine learning, making it easier for enterprises to adopt the technology, according to Edward Screven, chief corporate architect at Oracle.
“The key factor for machine learning in MySQL HeatWave is that it is built in,” Screven said during a video event going over the HeatWave enhancements. “Why is it that more people don’t use machine learning? All of you out there have heard of machine learning, all of you out there have heard of AI. I’m guessing most of you have never actually implemented machine learning or implemented AI in your application. If you have, I bet you’re not using machine learning and AI as broadly as you could in your application. Machine learning seems like magic, but it’s very hard to actually use if you use conventional tools, if you use what comes out of the box from most vendors [and] from most clouds. Machine learning is hard and it’s expensive.”
There is data to collect algorithms to pick – logistic regression, boosted trees and support vector machine, to name a few – hyperparameters to set, all to help create a model that then can be used for inference, which requires expertise and moving the large amounts of data from the database to an outside machine learning system. That’s how it has been done with HeatWave and other databases, Screven said.
Much of that is eliminated with MySQL HeatWave ML, integrating machine learning into the database and automating its functions.
“All of that activity – model building, choosing hyperparameters, running the training, running everything – all of that happens inside MySQL HeatWave,” he said. “You do not need to take the data out. That entire process is automated by MySQL HeatWave, choosing algorithms, choosing the type of parameters. You do not need to be an expert in machine learning and AI to use machine learning with your data stored in MySQL. You don’t need to take the data out, which means your infrastructure and your architecture for data is radically simplified.”
Using Amazon Web Services’ Redshift SQL database as an example, Screven said HeatWave ML is 25 times faster running machine learning workloads at 1 percent the cost, which among other things means that enterprises can afford to re-run machine learning jobs to ensure the models don’t get stale. HeatWave also scales easily, with an 11X increase in autotune speed and 8X improvement in feature selection when moving from one node to sixteen.
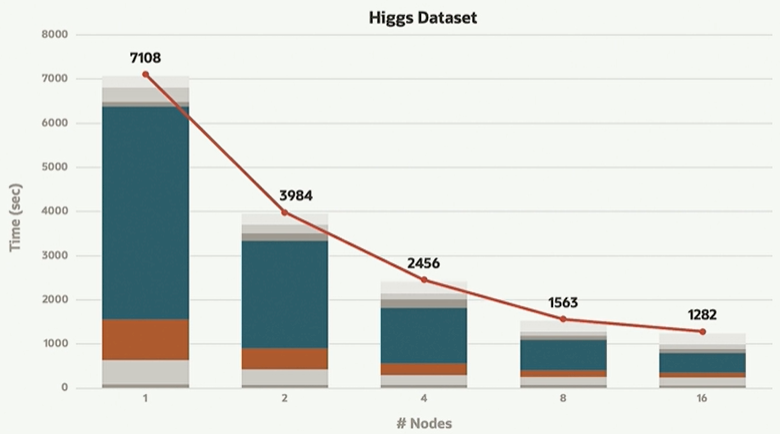
That scalability can easily shift up or down depending on demand, said Nipun Agarwal, senior vice president of MySQL HeatWave development at Oracle. In the past, such scaling had limitations, including that it had to be done manually and that the HeatWave cluster was not available while it was happening. Now provisioning new nodes is done by the system and the cluster remains running.
Oracle also is enabling HeatWave to take one more data per node, doubling it from 410 GB to 820 GB.The more data on the node, the slower the work runs, Screven said. The fewer the number of CPUs for volume of data, the slower it will run.
“But the price-performance is the same,” he said. “You get to pick where you want to be on that price-performance trade-off and you still get the same price-performance ratio. Your cost is half, it takes you longer to run, but maybe that works for you. We use something called Bloom filters to dramatically reduce the size of the intermediate results. If you look at the way that SQL operations are processed internally, there are intermediate results that are flowing through different sorts of data nodes internally inside those cluster. By using Bloom filters, we’ve dramatically reduced the volume of that data so we can put more processing on a node.”
With the tweaks to HeatWave announced this week, Oracle the ability to cram twice as much data per node and deliver it at half the cost, yields the same price/performance running ML workloads:

Another feature of HeatWave ML is what Oracle calls pause-and-resume, which enables enterprises to pause HeatWave when they don’t need analytical processing run on data and resume it when the need arises.
“You can push a button and all of your data stored in HeatWave nodes is pushed out into object storage,” Screven said. “It’s saved, and then those nodes are de-provisioned. You don’t need to pay for them anymore. When it’s time to run your analytic queries, you push a button and all of that data flows back in from object storage.”
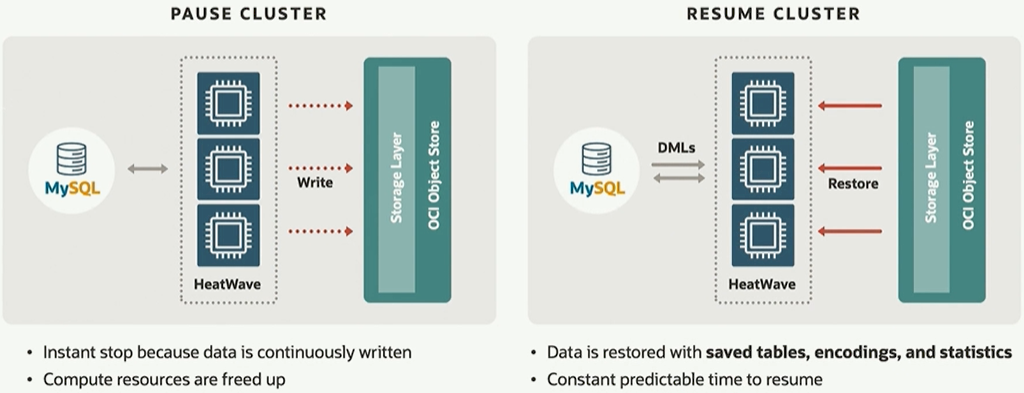
The data and statistics need for MySQL Autopilot also are automatically reloaded into HeatWave.
HeatWave ML also is designed to enable developers to better understand the machine learning model and explain what it does and why. Explainabilty is a key issue in machine learning, where the end result of running such analytical workloads can determine such decisions as who gets a house load or who gets hired. Enterprises need to be able to explain how those machine learning-based decisions are made to ensure no human biases are involved.
In HeatWave ML, Oracle integrate both model explanation and prediction explanations – a set of techniques to answer why a model made a specific prediction – as part of the process for training models. Screven noted that organizations “need to comply with regulations. A lot of times your regulators want to know why it is that you make the decisions that you make. How is it that you can’t do certain inclusions and make certain choices? We all care about fairness. … We want to make sure the ML is making decisions based on factors that do not encourage biases that human beings have. Repeatability is very important. Causality is very important. If your ML model, your ML system, your ML tools won’t let you explain the predictions it makes, you don’t get a chance to make yourself better based on what the models learned.”
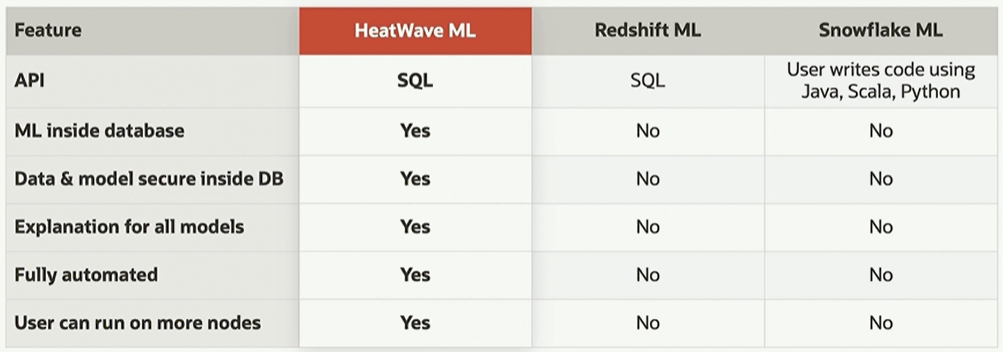
Here is how Oracle stacks up HeatWave against AWS Redshift and Snowflake:
And here are some performance comparisons that Oracle has done using the TPC-DS decision support data warehousing benchmark test at 10 TB dataset size:
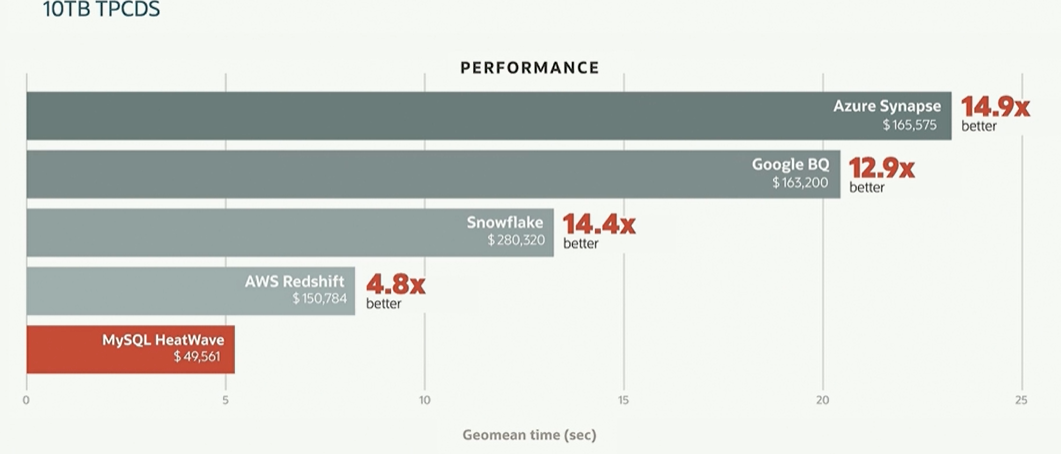
And here is another comparison Oracle has for comparing HeatWave against Redshift:
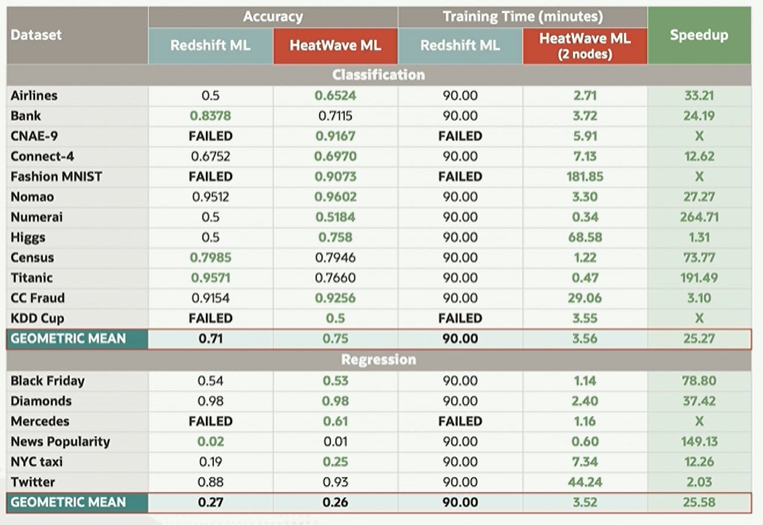
The goal of HeatWave ML is similar to that of other IT vendors: Make machine learning easy enough and cost-effective so that mainstream enterprises can run such analytical workloads without the need for expertise – data scientists are expensive and there aren’t nearly enough to meet the demand – and without crashing their budgets. Oracle just needs to find ways to keep ahead of a database pack that has the same desire to grow their machine learning customer bases by offering such expanded enterprise functionality.

Be the first to comment