
The “Everest” family of hybrid compute engines made by Xilinx, which have lots of programmable logic surrounded by hardened transistor blocks and which are sold under the Versal brand, have been known for so long that we sometimes forget – or can’t believe – that Versal chips are not yet available as standalone products in the datacenter or within the Alveo line of PCI-Express cards from the chip maker.
As we said during our preview of new compute engines coming in 2022, we felt that we were pretty familiar with the Versal roadmap in terms of feeds and speeds, but were not up to date with the rollout of these products in the datacenter and at the edge. Every time we turned around, and looked closely at an Alveo accelerator card, it had an Virtex UltraScale+ device in it – as was the case when we did a teardown of the TigerGraph graph database accelerated by FPGAs back in November 2021.
We are well aware that just saying field programmable gate array, or FPGA for short, is not really descriptive of these programmable devices, which have had hardened blocks even before Xilinx announced the Everest architecture back in October 2018. Xilinx calls these Versal devices the Adaptive Compute Acceleration Platform, or ACAP, and wants us to use this term to describe its hybrid compute devices, which have a mix of big and little Arm processors, AI matrix engines, DSP signal processing engines, and hardened memory, network, and I/O controllers all wrapping around the core programmable logic, what Xilinx calls adaptable engines. We live in an IT world where shorthand is necessary, and ACAP is never going to take off in the way people talk or the way search engines work, so that, as they say, is that. So we will talk about Versal devices as distinct from Virtex devices, and we will use the Everest codename because human brains love synonyms and variety. (Versal, by the way, is a clever amalgam of versatile and universal.)
The top brass at Xilinx saw our 2022 compute engine preview, as we knew they would, and immediately did a core dump to give us an update on the Versal roadmap as well as technical and market segmentation for the devices to help us – and you – understand what the company is doing and why it takes so long to get Versal devices into the datacenter.
The short answer on that is that the communications, industrial, automotive, defense, and broadcast industries are at the front of the line, which is why the lower-end Versal devices came to market first. This was the strategy before the coronavirus pandemic struck in early 2020, and it is a fortuitous bit of planning in that the smaller Versal devices are easier to make in a world where there is limited – and heavily sought after – foundry and packaging capacity. (It is a bit of a wonder to us that some of these chips that are in short supply, particularly in the automotive sector, are not implemented on relatively modest FPGAs. It could be that there are limited FPGA stockpiles, too, across Xilinx, Intel, and Lattice Semiconductor. We didn’t think to ask about ASIC replacement with FPGAs when we talked to Xilinx, but we are thinking about it now as we write.)
Here is the original Versal roadmap for the six series in the product line, which was put out in the fall of 2018:
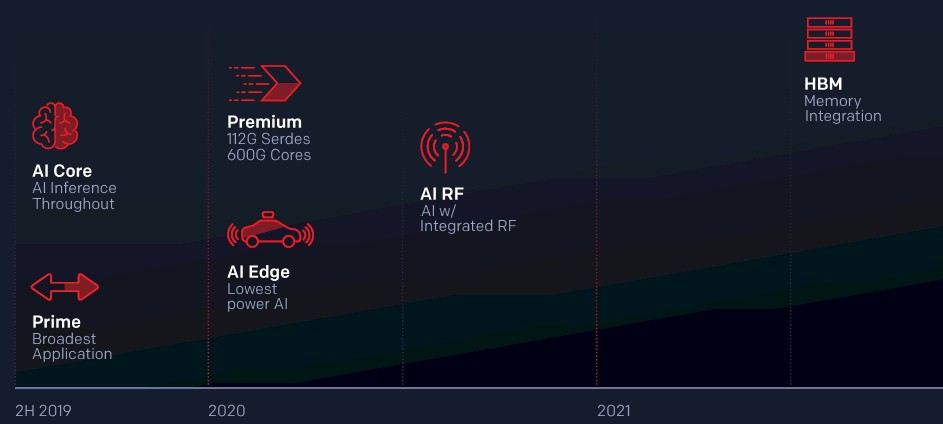
And here is the roadmap as of early this year:
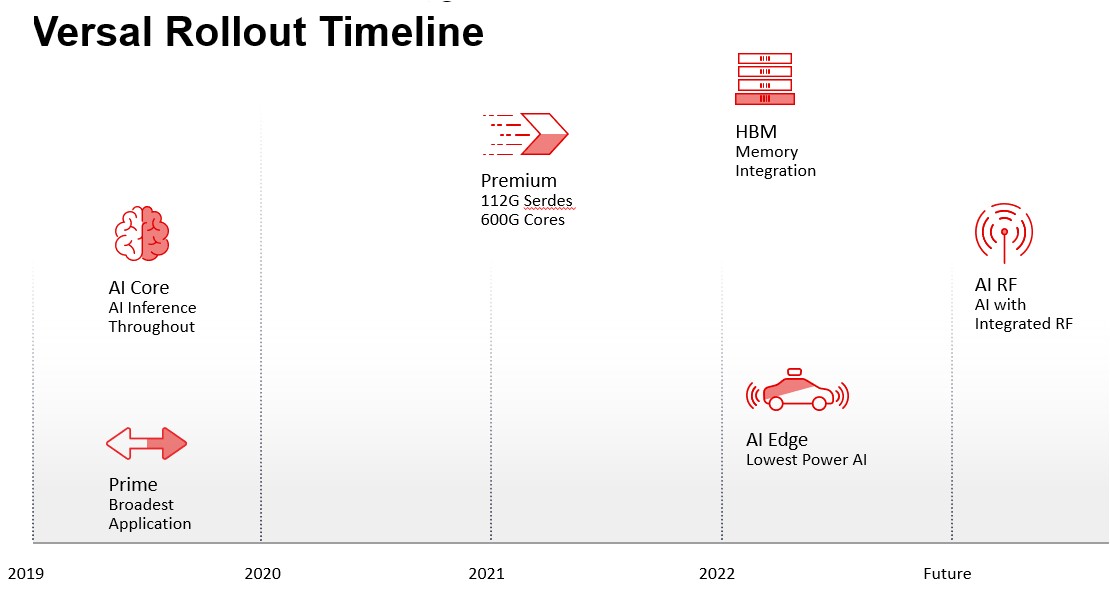
Given all that has changed in the world between the Everest preview and today, you would expect some changes, not just because of foundry and packaging shortages but because of changing market dynamics. Just as an example, if Ethernet switch makers or 5G base station makers use a mix of ASICs and FPGAs to create their appliances, you don’t want the FPGA to be a bottleneck, so you might focus on these lower-end devices where you know you have market demand and push other devices further out on the roadmap. Similarly, if customers can get by with a Virtex UltraScale+ device for now, which is made on a more mature and cheaper process and which might be in stock, you might focus on selling this instead of forcing the Versal upgrade. This is precisely the kind of thing that happened to the Xilinx roadmap, and is happening to the roadmaps of all kinds of compute engines in the datacenter and at the edge.
Before we get into the specifics of sampling and shipments in the Versal family, some architectural review is in order. This chart sums up the Everest device pretty well, just as a reminder of all of the stuff that is crammed into this hybrid compute and interconnect engine:

Depending on the Versal series, different parts of the Everest package are turned on, and the SKUs are created by varying the capacities of these components on the SoC. The Prime series is in the middle of the product line and is designed for various kinds of inline acceleration and does not have the AI engines in the devices but just the DSP engines; it also has DDR4 main memory controllers, PCI-Express and CCIX peripheral I/O, 32 Gb/sec and 58 Gb/sec signaling, and multirate Ethernet ports all hard coded. The AI Core series, which has a more diverse set of compute elements for machine learning inference, adds in the homegrown AI vector engines and takes out the 58 Gb/sec signaling.
This chart shows how the different series stack up, and not the addition of DDR5 memory with the Premium and HBM series and in some of the Prime series in the Versal lineup:
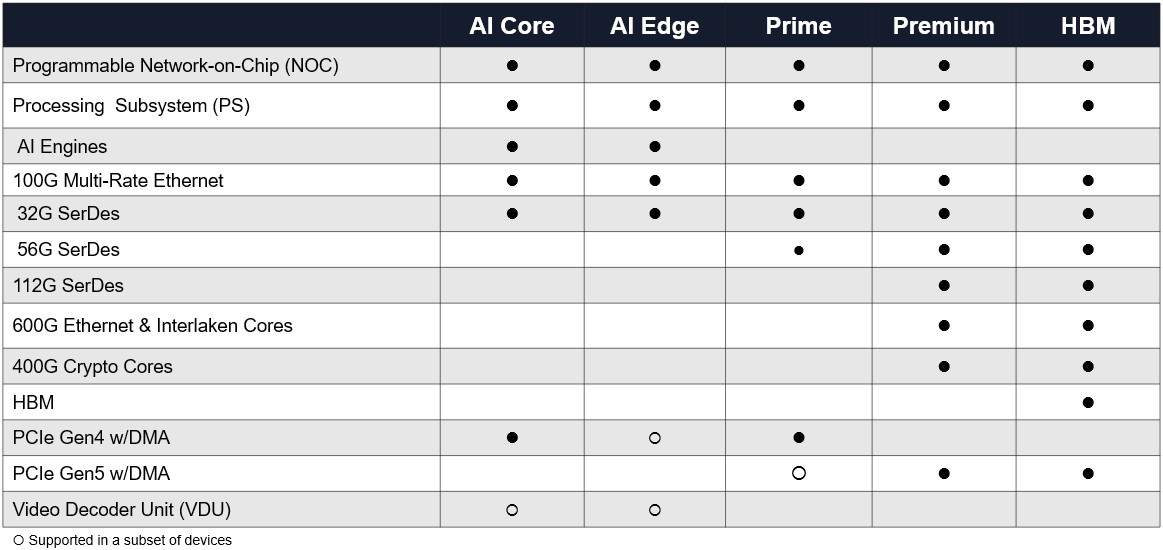
The Prime and AI Core versions of the Versal devices came out on time in the middle of 2019, but the Premium Versals were pushed out a year to early 2021, the AI Edge Versals were pushed out two years to early 2022, the HBM memory version, which is presumably based on the Premium Versal system-on-chip, was pushed out a few months from late 2021 to early 2022, and the AI RF variant, with an integrated radio, has been pushed out to “the future.”
“The existing RF SoCs are doing tremendously well in wireless markets, and also in some wired markets as well, such as in cable and access and so on,” Manuel Uhm, director of silicon marketing, tells The Next Platform. “We’re in production with the AI Core and Prime series, and the gNodeB 5G base stations are leading the charge with the AI Core devices. We have tons of gNodeBs around the world with AI Core deployed. We have just announced that the Premium series is sampling, and we are shipping them to customers that are developing next-generation networks based on 400 Gb/sec and 800 Gb/sec speeds as well as with the next generation of test and measurement equipment. With AI Edge series, which we announced in April 2021, we are going to be sampling very soon. The HBM Series will be sampling in this half, taking the Premium and adding HBM2 memory to it, adding an incredible amount of memory bandwidth.”
The Versal AI Core devices are used for beamforming for the radios in cell towers, which is a bit trickier with 5G signals compared to 3G and 4G signals.
The Versal AI RF Series could be a long time coming, we think, because it is hard to shrink the radio to 7 nanometers and get good signal and power – this is why the memory and I/O hubs in some CPU chiplet architectures are made with the larger transistor processes and the core compute, matrix math, or packet processing engines are shrank to 7 nanometers and then 5 nanometers. We have a hunch – and Xilinx didn’t say anything about this – that the future Versal AI RF series will be a chiplet design that breaks the radio free from the programmable logic and hard-coded logic.
This table sums up where Xilinx is in terms of sampling and shipping across the Versal series:
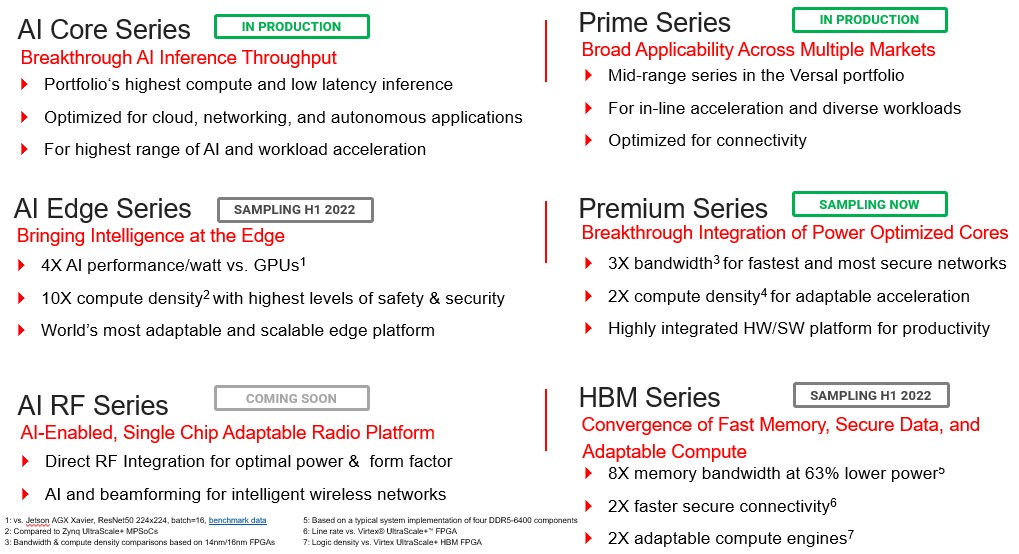
Uhm says that Xilinx has a broader product line for FPGA hybrid devices than its biggest rival (and the only rival in the datacenter), which is of course Intel, and that within each category of FPGA device, it has a broader scope of features and function.
There is probably a reason why Xilinx is growing faster than Intel when it comes to FPGAs, but that is a story we will tell another day. So is some recently benchmarking that Xilinx did against the Intel Agilex line of FPGA hybrids.
One last thing: We pressed Xilinx, once again, on when we will see Versal devices appearing in Alveo PCI-Express accelerator form factors. At the moment there is only one card, the VCK5000 development card, which is based on the XCVC1902 variant of the AI Core device in the Versal lineup and which is aimed at AI inference workloads against the Nvidia T4 and A4 GPU accelerators tuned for inference. This was announced last May for $2,495, but it is not intended for production workloads. We strongly suspect many companies are doing it anyway.
No word, still, on when true Alveo cards, with full support of the software stack and tech support from Xilinx, will be available with Versal hybrid FPGAs. You can bet that hyperscalers and cloud builders will have access to such devices before enterprises do, and before official announcements from Xilinx or AMD, which will very likely own Xilinx soon.

Xilinx Tunes Up FPGAs For HPC, Graph Analytics
High performance computing hardware is really a software game, and the software we are referring to is at a very low level where deep expertise in libraries and solvers can make the difference between a capable device performing up to its specifications and, well, not so much. If you scan …

Intel To Amp Up Security With “Ice Lake” Xeon SP Servers
Security is one of those necessary things that should not be an afterthought, but often is, and ideally is so invisible that it doesn’t get in the way of applications and the infrastructure it runs on. Speaking very generally, the cost of security has been so high on servers that …

AMD Finally Reaps The Fortunes It Has Sown
Sometimes, competing for business means coming up with better products than your rivals. And other times, competing means just not screwing up while your competitor stumbles. For the heated battle between AMD and its archrival, Intel, when it comes to compute engines in the datacenter, AMD is in the fortunate …
AMD needs to take one Zen module and some Xilinx fabric and put them in a package. Then you’d get rid of the need to go over PCIe to run a program. 10% of the code does 90% of the work but 90% of the code needs to be run at speed. You can’t have a big communication gap and expect to have the performance you’re looking for. If it runs in parallel put it in FPGA and the serial part that runs in software has to run at speed and the little Arms in FPGA SoCs don’t cut it.
It will be interesting to see what they do, won’t it? There are all kinds of packaging options.
I can’t wait until we can mix and match components on lots of chiplets and make all kinds of SKUs. Imagine if we could design compute engines inside a node the same way we add and subtract features of a car, hit a button and say give me 200 or give me 10,000 or give me a million.