
High performance computing hardware is really a software game, and the software we are referring to is at a very low level where deep expertise in libraries and solvers can make the difference between a capable device performing up to its specifications and, well, not so much.
If you scan the horizon of the HPC Realm, which is larger than just simulation and modeling or technical computing as it is sometimes called, there are a few compute engine suppliers who really seem to understand this well. One of them is Nvidia, which has created a very strong software stack for all kinds of accelerated computing atop its GPU engines, and we talked recently with Nvidia co-founder and chief executive officer, Jensen Huang, about how software is the heart of the Nvidia datacenter business. Venerable Cray, now part of Hewlett Packard Enterprise, also has a long history in deep understanding of libraries and solvers to make HPC applications hum.
So they don’t feel left out, Intel has done a lot of software work and is starting to emulate Nvidia and Cray with its oneAPI effort, and AMD has done a lot of work with its Radeon Open Compute (ROCm) environment, but neither has the breadth and depth that Nvidia or Cray has brought to bear on workloads that push the performance boundaries. (They are getting there, though, which is a good thing.)
The other company that comes to mind when you think of hardware-software co-design these days is Xilinx, which has created myriad highly tuned software stacks, all grouped together under its Vitis brand, to accelerate very specific workloads through highly tuned libraries and solvers for its Virtex UltraScale+ FPGAs within the Alveo PCI-Express adapter cards and through its free-standing Virtex and “Everest” Versal hybrid compute engines, which are not yet sold in Alveo cards, oddly enough. (Side note: the company insists on calling its Everest chips ACAPs – short for Adaptive Compute Acceleration Platforms – but which we still call programmable logic or FPGAs because that is still what is at the heart of these devices and what makes them interesting and different.)
After years of hearing people complain about the difficulty of programming FPGAs, which have obvious acceleration benefits, Xilinx cooked up the Vitis stacks to make it easier for people to deploy FPGAs to speed up specific workloads. The Vitis stacks and the experts in the libraries and the solvers, if anything, is what makes AMD willing to pay $30 billion to buy Xilinx and bolster its software portfolio and add to the depth of its software development bench.
As part of the SC21 supercomputing conference this week in St Louis, Xilinx rolled out its new Alveo U55C PCI-Express adapter card and tweaked Vitis software stacks to take on some HPC workloads, including acceleration for HPC clusters running the Message Passing Interface (MPI) protocol and using RDMA over Ethernet networks as well as for finite element analysis, machine learning, and graph analytics. We had already caught wind of the graph analytics work that Xilinx announced this week at SC21 a few weeks ago, thanks to its development partnership with graph database maker TigerGraph. (See The Accelerated Path To Petabyte-Scale Graph Databases for more on that, which employed the Alveo U50 cards, based on a different configuration of the Virtex FPGAs, in its benchmark tests.
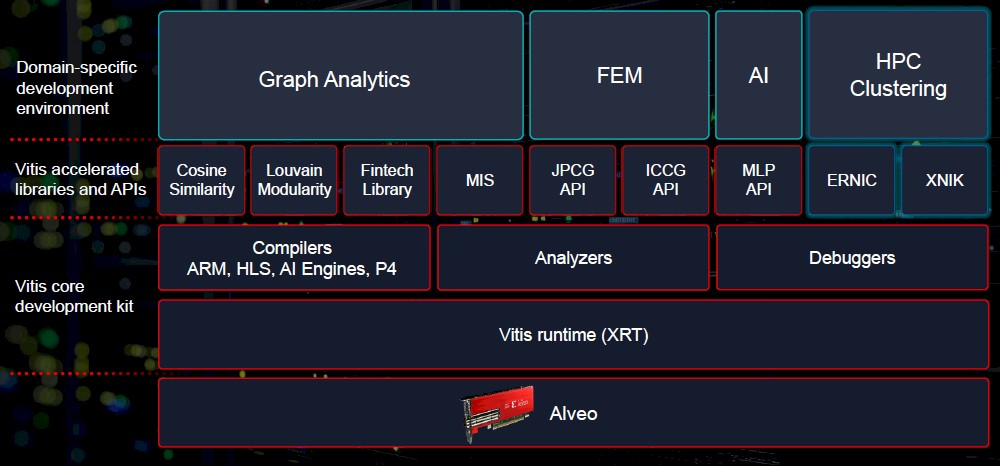
The Vitis stack has APIs into libraries that accelerate conjugate gradient calculations, the kind of which are at the heart of finite element analysis applications such as the ANSYS Mechanical and LS-DYNA tools. Specifically, Vitis accelerates Jacobi preconditioned conjugate gradient (JPCG) and inexact preconditioned conjugate gradient (IPCG) algorithms, as shown in the block diagram above.
“We did an analysis and found that 90 percent of the compute in these finite element analysis programs, and we have been able to accelerate these solvers by 5X on a cluster equipped with Alveo U55C accelerators,” Nathan Chang, HPC product manager for the Data Center Group at Xilinx, tells The Next Platform. “Running these applications, it’s complicated because there are multiple types of math that are interacting together –sparse matrix multiplication mixing with a ton of vector engines. And so the CPUs are experiencing tons of cache misses and hierarchy issues with their caches. And the caches are too small, so you have some Goldilocks issues happening there, too. But we are able to be very, very efficient with how we move data and how we manage memory and we are able to have queries happening in the sparse matrix for the vector engines, and we are preparing that data with microcircuitry every time you hit a vector engine. With a CPU, you would be writing back and forth in the memory, where with an ACAP you are never going to do that until you have to write back into the matrix.”
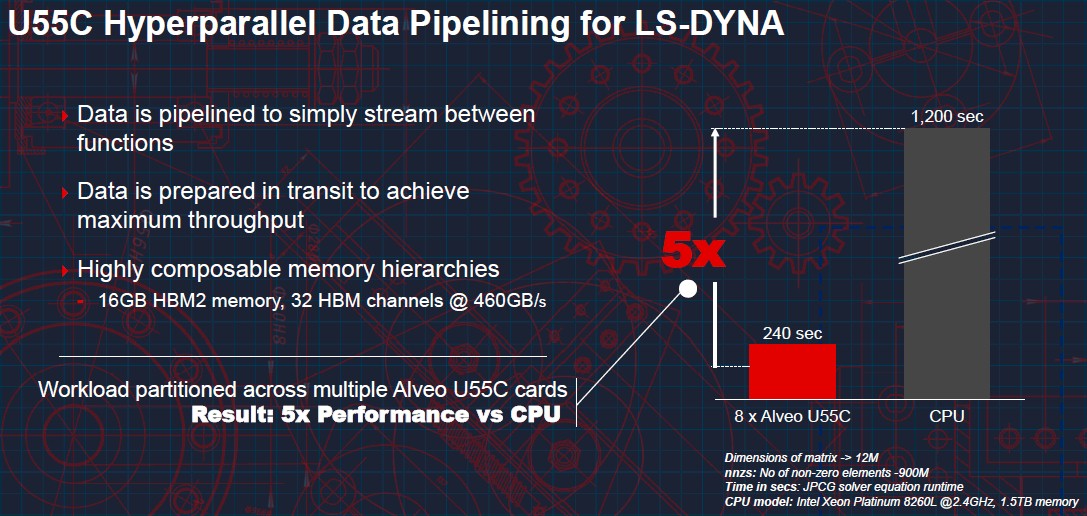
The trick to accelerating LS-DYNA is to not only make use of the 16 GB of HBM2 memory on the card, which has 460 GB/sec of bandwidth, but to pipeline data between functions and to prepare the data, as Chang says above, when it is in flight to avoid cache misses and other stalls and thereby maximize throughput of the application in a way that you cannot do on a CPU-only cluster running finite element analysis programs.
The Alveo U55C card is more dense than the Alveo U280 card it replaces in the Xilinx lineup, as you can see:
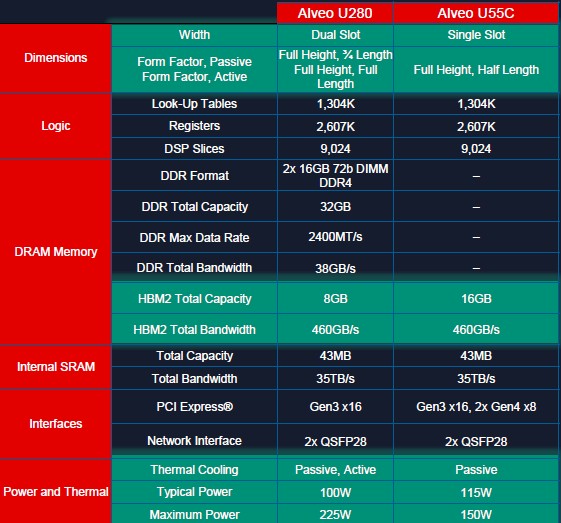
The Alveo U55C is based on the VU47P variant of the Virtex UltraScale+ FPGA, which has HBM2 memory integrated with the compute engine. The big change in this device, aside from density, is that it has 16 GB of HBM2 memory instead of a mix of 32 GB of DDR4 memory and 8 GB of HBM2 memory. By sacrificing that DDR4 memory (which simplifies programming a bit because there is only one main memory now with the U55C instead two with the U280), Xilinx is able to bring the maximum power down to 150 watts and the typical power down to 115 watts, compared to the maximum watts of 225 with the U280; however, the typical power on the U280 is still around 100 watts and is therefore lower than on the U55C. The U55C device is a single slot, half length card, rather than a dual-slot full length card like the U280, which means it can fit in compact HPC-style servers. It comes in PCI-Express 3.0 x16 and PCI-Express 4.0 x8 variants.
The Alveo U55C is being readied for market now and is expected to be in proofs of concept in Q1 2022 and will roll out after that. The card has a list price of $4,795.

Why Did Silver Lake Buy A Majority Stake In Intel’s Altera FPGA Business?
Beleaguered chip maker Intel has been looking for ways to capitalize on non-core, not large, but profitable parts of its business to raise funds for its ambitious plans to revitalize Intel Foundry and to also invest heavily in the Intel Products group. And only two weeks after taking the helm …

AMD Finally Reaps The Fortunes It Has Sown
Sometimes, competing for business means coming up with better products than your rivals. And other times, competing means just not screwing up while your competitor stumbles. For the heated battle between AMD and its archrival, Intel, when it comes to compute engines in the datacenter, AMD is in the fortunate …
Tuning The FPGA For Clouds And Comms
It has been a long time since plain vanilla programmable logic circuits known as field programmable gate arrays have been available in a raw form. For many years, Xilinx, Altera, and others making what we call FPGAs have been adding hard-coded circuits for certain functions that might otherwise be synthesized …
Be the first to comment