
The Graviton family of Arm server chips designed by the Annapurna Labs division of Amazon Web Services is arguably the highest volume Arm server chips the datacenter market today, and they have precisely one – and only one – customer. Well, direct customer.
These two facts inform the design choices that Annapurna Labs has made to create ever-more-powerful Arm server processors and they differentiate from the two other reasonably high volume Arm server CPUs aimed at servers in the market today, namely the A64FX processor from Fujitsu and the Altra family from Ampere Computing. There are other Arm server chips in development for specific geographies and use cases, as there always seems to be, but none of them look like they will be volume products in the way that the Graviton and Altra family will be; the Fujitsu A64FX is a volume product inasmuch as the main machine using it, the “Fugaku” supercomputer at RIKEN Lab in Japan, has 158,976 single-socket nodes crammed into 432 racks.
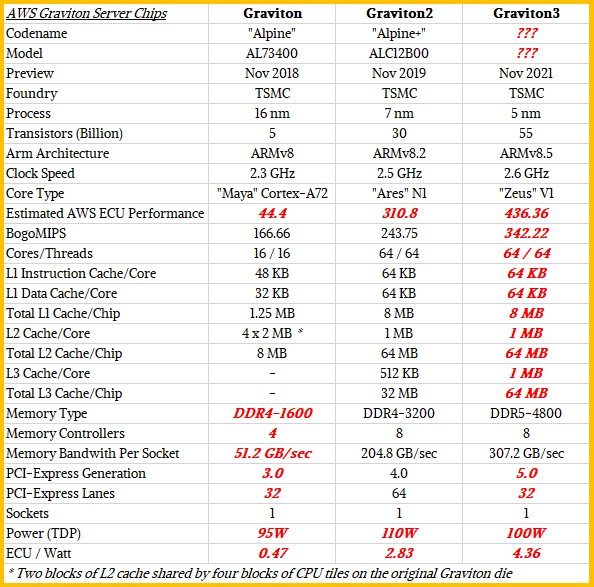
AWS unveiled its third generation Graviton3 server chip back at the re:Invent conference in Las Vegas, which we were not able to attend, and we did an overview of the processor back in December based on the summary information that was available at the time, promising to circle back and do a deeper dive when more information from technical sessions was made available. That information is available now, through a presentation made by Ali Saidi, the senior principal engineer in charge of Graviton instances at the cloud giant. Saidi goes into a little more detail about what makes the 64 core, 55 billion transistor Graviton3 that is in preview different from its predecessors, the 16 core, 5 billion transistor Graviton that was previewed in November 2018 and the 64 core, 30 billion transistor Graviton2 that was previewed in November 2019. It takes AWS a few months to get the Graviton chips into full production, and we will know more once the C7g instances on the EC2 service using the Graviton3 chips are in full production and out of preview.
To start off, Saidi talked about the reason why AWS is even bothering to make its own server CPUs when, perhaps, making its own “Nitro” DPUs for offloading the hypervisor as well as security processing and storage and network virtualization off of X86 server processors would seem to have been sufficient.
“Building our own chips really lets us innovate at a wide variety of layers, innovate faster, raise the bar on security, and deliver more value,” Saidi explained. “On the innovation side, being able to build the silicon and the server it goes into, and having the teams that write the software for that all under one roof means there is faster innovation and we can cut across traditional boundaries. We also can build chips for our needs. We can specialize them for what we are trying to do and we don’t have to add features that other people want. We can just build them for the things that we think are going to provide the most value to our customers and ignore the ones that really aren’t. The third thing we get is speed. We get to control the start of the project, the schedule, and the delivery. We can parallelize the hardware and software development and use the massive scale of our cloud to do all of the simulations required to build a chip. And lastly, operations. We have a lot of insight into operations through running EC2 and we can put features into the chips to do things like refresh the firmware to address an issue or enhance functionality without disturbing customers running on the machine.”
Clearly, the Graviton effort is about more than getting cheaper X86 server chip prices out of Intel and AMD – although it is that, too, even if Saidi didn’t mention it. But as long as AWS is hosting a lot of X86 customers in its cloud, it will be buying Xeon SP and Epyc processors for its cloud customers for those applications they have created that are not easy to port to Arm architecture and therefore benefit from the 20 percent to 40 percent price/performance advantages that the Graviton family has shown over X86 instances on EC2 across a wide array of workloads and scenarios.
No one knows for sure how many Graviton processors are in the AWS fleet, but what we do know is that Graviton processors are available in some fashion in 23 different AWS regions and across a dozen different EC2 instance types.

AWS has over 475 different EC2 instance types, which run the gamut in terms of CPU, memory, storage, networking, and accelerator configuration, and the Graviton instances are obviously a very small part of the variety of EC2 instances. With 23 out of 24 regions having at least some Graviton processors, this is perhaps a better indication of the prevalence of Graviton in the AWS fleet – but not necessarily. What we think can be honestly said is that with a 30 percent to 40 percent price/performance improvement over X86 processors running web-style workloads and with increasingly more powerful Graviton chips as the line evolves, we think an increasing portion of the AWS software workload that is not related to running other people’s applications on X86 processors running Windows Server or Linux – think about the myriad database and SageMaker AI services, for instance – will end up on Graviton and therefore lower the overall cost of these services while maintaining profits at AWS.

In fact, Saidi said that for the PaaS and SaaS services that AWS peddles, if customers don’t specify an instance type specifically when they sign up for the service, they will get a Graviton instance underneath that service. This suggests that there is a reasonably high volume of Graviton servers in the AWS fleet. So does the fact that on Prime Day this year, the Graviton2 instances installed underneath the EC2 service underpinned a dozen core retail services used by the Amazon online retail operation. Once key service, called Datapath, which supports lookups, queries, and joins across Amazon’s internal retail data services, was ported from X86 servers to a three-region cluster comprised of over 53,000 of the Graviton2-based C6g instances.
This is the game, and it is probably why Intel and AMD needed to build their own clouds a decade and a half ago and not let Dell, Hewlett Packard Enterprise, and VMware try and fail at it. The CPU tail is going to wag the datacenter dog in the not too distant future.
This is also why Nvidia is working with AWS to get its HPC SDK running on its ParallelCluster supercomputing service based on Graviton processors this year, which will allow C, C++, and Fortran programs using OpenMP to parallelize applications to run on Graviton instances, and it is also why SAP is working with AWS to port its HANA in-memory database to Graviton instances and to use those instances as the basis of SAP’s own HANA Cloud service, which is hosted on AWS.
Inside The Graviton3
The presentation by Saidi was considerably more detailed than the re:Invent keynotes, and actually showed a shot of the Graviton3 package, which is a chiplet design as we had heard it was. Here is the slide that shows the Graviton3 package:

The feature image at the top of this story zooms in on this a bit, but the original image is blurry – so don’t blame us. That is as good of an image of the Graviton3 package as there is right now.
This schematic below makes it a little more clear how the chiplets on the Graviton3 break up its functions:
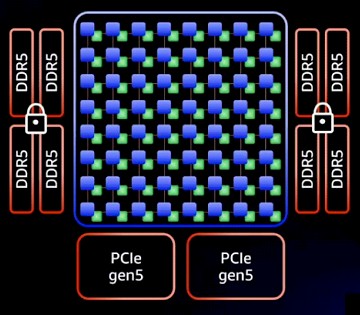
Rather than have a central I/O and memory die and then chiplet cores wrapping around it, as AMD has done with the “Rome” Epyc 7002 and “Milan” Epyc 7003 X86 server chips, the Annapurna Labs teams kept all of the 64 cores on the Graviton3 in the center and then broke off the DDR5 memory controllers (which have memory encryption) and PCI-Express 5.0 peripheral controllers separate from these cores. There are two PCI-Express 5.0 controllers at the bottom of the package and four DDR5 memory controllers, two on each side of the package. (This is the first server chip to support DDR5 memory, which has 50 percent more bandwidth than the DDR4 memory commonly used in servers today. Others will follow this year, of course.)
Of the 25 billion transistors incremental that were added with the Graviton3 compared to the Graviton2, most of these, according to Saidi, were to beef up the cores, and as Peter DeSantis, senior president of utility computing at AWS, already explained in his keynote, the idea was to get the cores doing more kinds of work as well as more work in general by beefing up the pipelines. Like this:

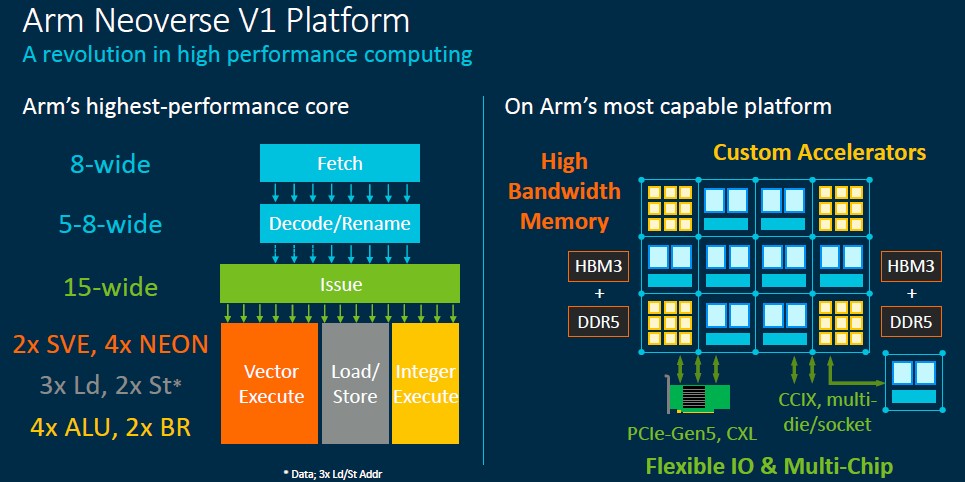
The Graviton2 is based on the “Ares” N1 core from Arm Holding’s Neoverse designs, which were updated last year with the “Zeus” V1 and “Perseus” N2 cores unveiled last April. We looked at the SIMD units and originally thought the Graviton3 was based on the N2 core, not the V1 core. AWS has not confirmed what core is being used, but after re-reading our own coverage of the N2 and V1 cores from last April, where we talked about the pipelines on the two cores, it is clear that it is a modified V1 not a beefed up N2. (Sorry for the confusion. Chalk it up to being tired.) Here are the original V1 core specs from Arm Holdings that show V1 is indeed the Graviton3 core:
We took a huge stab at guessing what the V1 core Annapurna Labs is using in Graviton3 looks like inside in terms of caches and such, and we openly admit this is a wild guess, as items shown in bold red are:
Anyway, back to the pipeline. Saidi explained that the Graviton3 core has 25 percent higher performance – which we take to mean higher instructions per clock, or IPC – compared to the Graviton2’s N1 core. The Graviton3 runs at a slightly high clock speed (2.6 GHz versus 2.5 GHz for the Graviton2). The front end on the core is twice as wide and it has a much bigger branch predictor as well, according to Saidi. The instruction dispatch is almost twice as wide and the instruction window is twice as wide, and the SIMD vector units have twice the performance and support both SVE (the variable length Scalable Vector Extensions invented by Fujitsu and Arm for the A64FX processor for the Fugaku supercomputer at RIKEN) and BFloat16 (the innovative format created by the Google Brain artificial intelligence team). There are two times as many memory operations per clock to balance this all out, as well as some enhanced prefetchers, which can pump twice as many of outstanding transactions to those beefed up Gravition3 cores. The core’s multipliers are wider, and there are twice as many of them.
As is the case with prior Graviton and Graviton2 cores as well as the cores used in the Ampere Computing Altra family, there is no hyperthreading in the Graviton3 cores to try to boost throughput. The tradeoff in being less secure and more complex is not worth the increased performance – at least not for the way AWS codes its applications.
The other thing that AWS is not doing is adding NUMA electronics to link multiple Graviton3 CPUs into a shared memory system, and it is not breaking the core tile down into NUMA regions, either, as Intel does with its Xeon SPs through circuitry and as AMD does out of necessity with eight core tiles on a Rome or Milan Epyc package. The cores are interconnected with a mesh that runs at over 2 GHz and that has a bi-sectional bandwidth of more than 2 TB/sec.
One neat thing about the Graviton3 is the server, which we talked about a bit back in December, is that AWS is creating a homegrown three-node, three socket server that has a shared Nitro DPU linking them to the outside world. Like this:
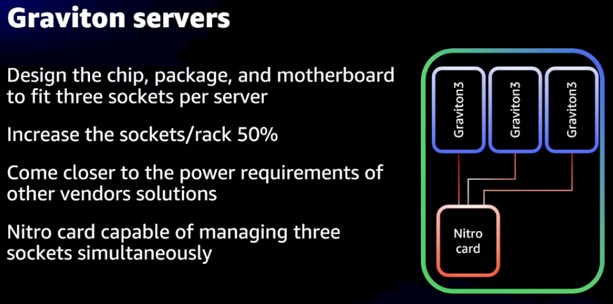
By offloading a slew of CPU functions off to the Nitro DPU and by cramming a bunch of single-socket Graviton3 nodes onto the card, AWS says that it can boost the sockets per rack by 50 percent – and presumably that means without sacrificing any performance relative to the X86 processors coming out of AMD that are in a reasonable thermal envelope. Whatever that is these days. . . .
We already went over a bunch of performance metrics in our prior Graviton3 coverage, but this one showing the SPEC 2017 integer and floating point tests is interesting:

The C7g instance is using a Graviton3 and the C6g is using a Graviton2, which shows the former has about 30 percent more integer performance and about 60 percent more floating point performance than the latter. The C5 instances are based on a custom “Cascade Lake” Xeon SP processor from Intel, while the C5a instanced are based on the Rome Epyc processor from AMD. The C6i instances are based on the “Ice Lake” Xeon SPs. We would prefer to have actual core counts and clock speeds for these instances to make a better comparison, but clearly AWS wants to leave the impression that Graviton2 already beat the competition and Graviton3 really does.
Any real comparison would look at core count, cost, thermals, and performance for integer and floating point work, and then weigh all of these factors to pick the chips to do real-world benchmarks on real applications. SPEC tests are just an ante to play the game. They are not the game.

Other Than Nvidia, Who Will Use Arm’s Neoverse V2 Core?
We are still plowing through the many, many presentions from the Hot Interconnects, Hot Chips, Google Cloud Next, and Meta Networking @ Scale conferences that all happened recently and at essentially the same time. And we intend to take our usual, methodical approach of finding the interesting bits and doing …
Google Says The SOC Is The New Motherboard
For two decades now, Google has demonstrated perhaps more than any other company that the datacenter is the new computer, what the search engine giant called a “warehouse-scale machine” way back in 2009 with a paper written by Urs Hölzle, who was and still is senior vice president for Technical …
Broadcom And Marvell Ride The Compute Engine Independence Wave
Nvidia sells the lion’s share of the parallel compute underpinning AI training, and it has a very large – and probably dominant – share of AI inference. But will these hold? This is a reasonable question as we watch the rise of homegrown XPUs for AI processing by the hyperscalers …
Nice article. Note that ‘hyperthreading’ is Intel specific, so you should probably exchange it for SMT.
Yup. I know the distinction, was just knocking the rust off the sword. Or, rather, the pen, which is mightier.
Looking at just the number of available EC2 configurations (instance type + size) for rent globally, Graviton (all generations) accounts for nearly 18% of the total, slightly more than AMD’s ~16%, and well below Intel’s ~66%.
That’s a 126% increase in available Graviton configurations year/year. How that translates into ‘total installed’ remains, of course, an exercise for the reader.
I mistook what they said then. I presumed the 475 was historical types over time, not 475 different type/size combos. What you said makes more sense. It moves it from 12/475 to X/475, and you figured out X to get that percentage.
Thesecond paragraph just ends with “has” and doesn’t make sense? Typo somewhere?
As for the rest of the info, it’s very cool! Intel/AMD have to be wondering where the ARM and RiscV stuff is going to take them down the line. I could see AMD coming out with a stonking good RiscV system at some point.
Not sure why that fragment did not copy over, but it is fixed now.
N2 is a 5-wide core with 2 SIMD pipes while V1 is 8-wide with 4 SIMD pipes. The graph in the article shows an 8-wide core with 4 SIMD pipes, so how could it be N2?
Because I forgot what I wrote back in April 2021. And clearly it is a V1, not a beefed up N2.
Regarding the 25% core performance improvement over Graviton2’s N1 core..how do we explain this against ARM’s claim of 50% IPC improvement for V1 core over N1 here: https://www.arm.com/products/silicon-ip-cpu/neoverse/neoverse-v1 ?
Well, it all depends on the benchmarks one uses to gauge IPC? Amazon is probably using a suite of real stuff and Arm was looking at a suite of microbenchmarks like SPEC and such. It’s a good question. In another observation, I am not exactly impressed with adding 1.83X more transistors and getting only 25 percent more IPC and only getting 1.3X more SPEC integer and 1.6X more SPEC floating point. Clearly this was about adding more floating point to address AI and HPC needs. Remember AWS uses Graviton to design Graviton chips, and so does Arm. It is a fair trade to catch up to the other vector and matrix engines in other CPUs, to be fair. I just wish the integer performance scale more like 1.8X, too. With 50 percent IPC on the integer side and a higher clock speed, say 3.5 GHz, maybe someone else can push it higher.
It’s interesting to think of price pressure against intel as the primary motivating factor for going ahead with a custom chip development. In recent years we’ve seen some players like Broadcom/Marvel dip their toes into the market for arm server chips, and give up, when the captured market proved to be too small. Though in those cases, the vendor wants to undercut intel, but only by enough to win some customers. They essentially want to push the arm server processor price up to as high a fraction of intel’s prices as the market will tolerate. Amazon, on the other hand, is creating as effective a low cost arm server processor as they can, in order to pull down the price of the intel offering.
I’ve seen speculation that ThunderX3 was cancelled because they couldn’t see a path to $300M/year in sales. Does that mean that Amazon’s chip pays for itself if they can shave $300M a year off the price they pay intel? If that number is wrong, what is the number?
Price pressure is not the only factor, as AWS has explained all the other reasons, such as having complete stack control. But it is clearly a side-effect, and I think this is why we also see custom ASICs for AI.
As for the number, I am not sure. If control is very important, it can cost AWS more to design and fab chips and they still might do it, and make up the difference pitting Intel and AMD against each other for X86 engines. Suffice it to say, I think X86 cloud is subsidizing Graviton, and it is intentional.
Looks like you have codenames reversed .. V1 is Zeus and Perseus is N2. Does that mean your guess is also reverse? 🙂
Nope. Just losing my mind…. All fixed now. The future core and architecture was called Zeus way back a few years ago, and that was the presumed N2 core. Then they created N2 as a cut-down Zeus core and called it N2 and code-named it Perseus. I have bits of history stuck in my cache and it won’t flush. Like a garage bathroom toilet…
Lol… thanks for fixing it, I thought I had it wrong in my mind
“What we think can be honestly said is that with a 30 percent to 40 percent price/performance improvement over X86 processors running web-style workloads and with increasingly more powerful Graviton chips as the line evolves, we think an increasing portion of the AWS software workload that is not related to running other people’s applications on X86 processors running Windows Server or Linux – think about the myriad database and SageMaker AI services, for instance – will end up on Graviton and therefore lower the overall cost of these services while maintaining profits at AWS.”
What?