
We are strong believers in disaggregation and composability here at The Next Platform, and we think that eventually the tyranny of the physical confines and configurations of motherboard will be over. At some point in the future – probably not five years but maybe within ten – systems will be stacks of components – trays of CPUs, GPUs, FPGAs, and other compute engines, trays of DRAM, persistent memory like Intel 3D XPoint Optane DIMMs, NVM-Express flash and possibly MRAM and other memory technologies, plus DPUs that deal with security, storage, and networking interfaces for the trays – all lashed together in a fabric and composable in a wide variety (but certainly not infinite) of configurations.
Given the expanding memory hierarchy in machines, which will get broader and deeper over time, we have argued that a memory hypervisor, which abstracts away the complexities of the various memories and presents final configurations to operating systems that are none the wiser, is necessary. Such a memory hypervisor would be analogous to – but in some ways different from – a server virtualization hypervisor that abstracts CPU, DRAM, storage, and network I/O today for the virtual machines that run on them.
From the looks of Project Capitola, which VMware previewed last week at its VMworld 2021 conference, VMware does not really believe that a separate thing called a memory hypervisor is necessary. Which stands to reason because this could cause its ESXi hypervisor and vSphere management tool franchise for server virtualization, which generated $11.8 billion in revenues and $2.1 billion in net income in fiscal 2021 ended in January of this year. So of course VMware thinks it already has a perfect memory hypervisor already, and we think that while it may not be perfect, it is certainly further along than anything else we have seen with the possible exception of MemVerge and its Memory Machine platform, which has a memory hypervisor called Distributed Memory Objects at the heart of it.
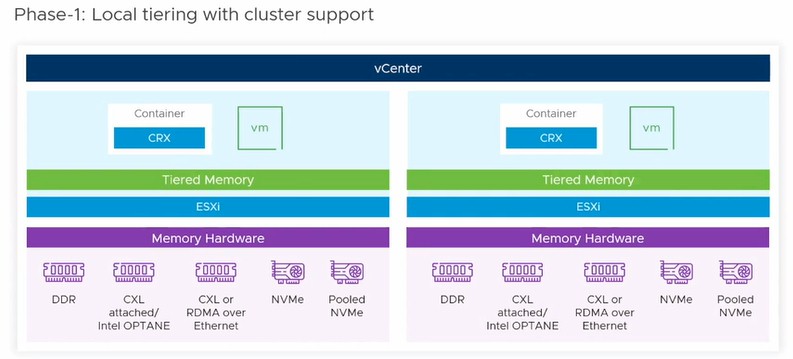
With Project Capitola, which has been under development for approximately three years according to Sudhanshu Jain, product management director in the Cloud Product Business Unit at VMware, the ESXi hypervisor is turned into a memory pooling and aggregation stack. In essence, the transparent storage tiering that has been part of the ESXi hypervisor to manage access to disk and flash block storage has been pulled up into the memory hierarchy and now will be able to allocate chunks of DRAM or PMEM to specific VMs in an ESXi node as needed. But that is just a start. The idea is to take on the whole memory tier eventually, which looks like this but which will probably get a few more layers in the coming years:

As you can see, there is a direct relationship between latency and price, and an inverse relationship between latency and capacity and latency and price. And we cannot get around this except by having pools of different kinds of memory and then having something akin to a memory hypervisor that can make them all addressable to applications and their operating systems. (Maybe someday we don’t need operating systems as we know them, or better still, will not be able to afford the luxury of anything but a container runtime.)
In this case of the early work at VMware, Project Capitola is aggregating DRAM and Optane PMEM for virtual machines within a local node, and as Jain correctly observes, memory is the last part of the hardware stack that has not been software defined (even if it has been virtualized), which means it can be shared as a pool of raw resource and programmatically configured and reconfigured on the fly as well as manage the placement of data and the resulting application performance, and therefore provide quality of service on a cluster of machines.
“Project Capitola’s mission is building a flexible and resilient memory management at the infrastructure layer itself at significantly better TCO,” Jain explains in his presentation at VMworld 2021. “We are talking about 30 percent to 50 percent better TCO, depending on the hardware and what price/point – and at higher scale, of course, which we can do with this model more than has been previously possible.”
Here is the problem as VMware sees it, and as many organizations in the HPC and enterprise realms know this to be true. While some applications are compute bound or I/O bound, there are a lot of applications that are memory bound – and that can be either a bottleneck on memory capacity or memory bandwidth, or both. But, memory is crazy expensive, and can account for 40 percent to 50 percent of a typical server these days, and even higher on fat memory configurations. (That assumes a CPU-only server. Once GPUs enter the picture, GPUs start to dominate the bill of materials, but memory hangs in there.)
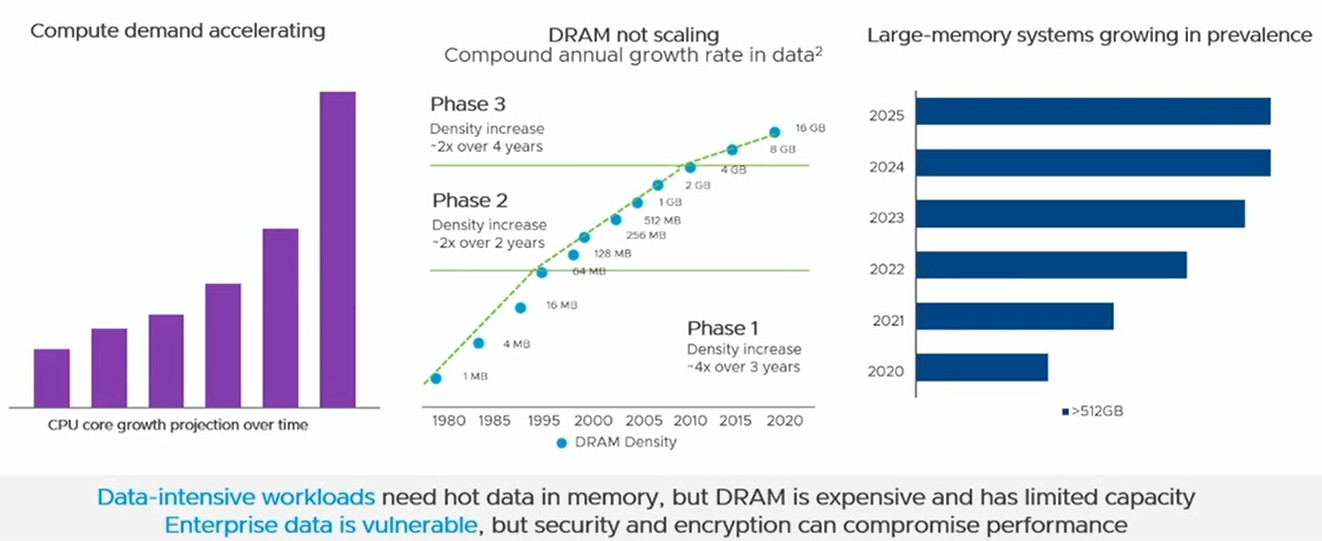
You can do some clever things by mixing DRAM and PMEM in a system to lower the overall cost of main memory, and for some workloads, using PMEM does not reduce the performance by all that much so long as there is the right balance of DRAM with it.
But this is not a memory hypervisor as yet, not by our definition. What will make Project Capitola a true memory hypervisor as we envision it will be when it can look across not a cluster of machines but racks of trays of components and provision byte-addressable and page-addressable memories all at a single layer and make the operating system think it is just one giant, flat memory space.
For you system architecture history buffs, this is something that IBM’s System/38 minicomputer implemented across main memory and disk drives back in 1978, coming out of its failed “Future Systems” effort to converge its mainframe and minicomputer platforms. This single level storage, as IBM still calls it, was further perfected in 1988 with the AS/400 system, and still lives on to this day in the Power Systems machines running the IBM i operating system and integrated relational database management system. So this is not a new idea.
What is new is that we believe that a true memory hypervisor will have to be part of the hardware composability stack, and it also has to work with bare metal and container environments just as well as any server virtualization platform. And that probably means needing to shim it underneath server virtualization hypervisors and having it run atop bare metal servers but underneath Kubernetes. What VMware is doing presupposes you are paying for ESXi and vSphere and you want to add memory composability to your virtual server clusters. We want a memory hypervisor to allocate blocks of all kinds of memory, fast and slow, near and far, DRAM, PMEM, or flash – whatever – and do it all so the operating system doesn’t have to mess with it.
What VMware is doing with Project Capitola is a good start, and Jain was clear that VMware is thinking big about this even if it is taking baby steps with local tiering within a node:
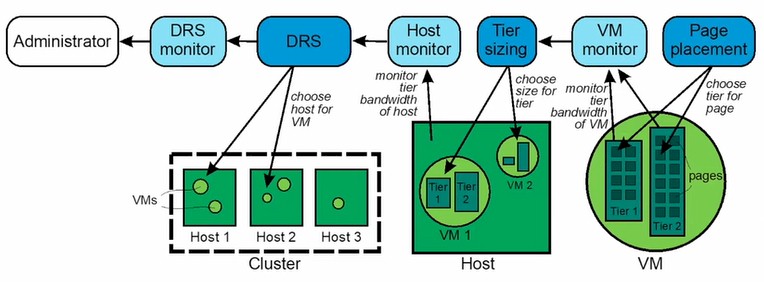
Here is the block diagram that shows the VMware software layers and how they control memory access, including the Distributed Resource Scheduler (DRS) that manages the composition of VMs across a cluster of hundreds of ESXi nodes in the modern datacenter:
It is when high speed PCI-Express fabrics – or maybe even silicon photonics – with protocols like CXL come into the picture that things get interesting, and VMware hints at this in the chart below:
![]()
The pooled resources in the table, including DRAM and HBM and other high density memories, are the hard part, and figuring out the protocols and the fabrics needs to be done. But we think the industry is converging on PCI-Express transports and the CXL protocol for asymmetric linking of memories, and so does VMware based on its charts and its strong partnership with Intel.
Don’t be surprised when Intel buys Microchip, a maker of PCI-Express switch ASICs, leaving Broadcom as the only other supplier. Marvell might see an opportunity here and design and sell its own PCI-Express switch chips. If Intel doesn’t buy MicroChip, maybe AMD should. Maybe MicroChip or Micron Technology or Intel should buy MemVerge, as we have pointed out before, and create a more open memory hypervisor (not necessarily open source, but not tied to any particular server virtualization hypervisor or a need for one). What we do know is that eventually, the DPU will need a memory hypervisor, so maybe Nvidia should be thinking along these lines. . . .
That’s enough IT Vendor Chess for the moment.
To show the potential of “transparent” and “intelligent” memory tiering, as Jain called it, VMware trotted out some benchmarks showing how the Project Capitola extensions to the ESXi hypervisor could balance the interplay of DRAM and PMEM in a system and the performance of the HammerDB database and SPECjbb Java serving benchmarks by reducing the dependence on DRAM and increasing the use of PMEM.
The HammerDB test was done using the Microsoft SQL Server database running atop Windows Server 2016 on a two-socket Dell PowerEdge R740xd server with two Xeon SP=8280L Platinum processors with a total of 56 cores, 768 GB or DRAM and 3 TB of PMEM. (They had a dozen sticks each, half and half on each processor socket.) The machines also had a 1.6 TB NVM-Express flash drive from Samsung for local storage. The SQL Server virtual machine tested was pretty skinny at only eight vCPUs and 32 GB of vRAM, and 100 GB of flash for storage of the database and 50 GB for database log files. The TPC-C online transaction processing test profile of the HammerDB benchmark was used for this test, and it had 500 users and 1,000 warehouses, with a two minute warmup time and a 20 minute run.
The chart below shows the performance normalized for an all-DRAM virtual machine and shows the different mixes of DRAM and PMEM along the X axis:
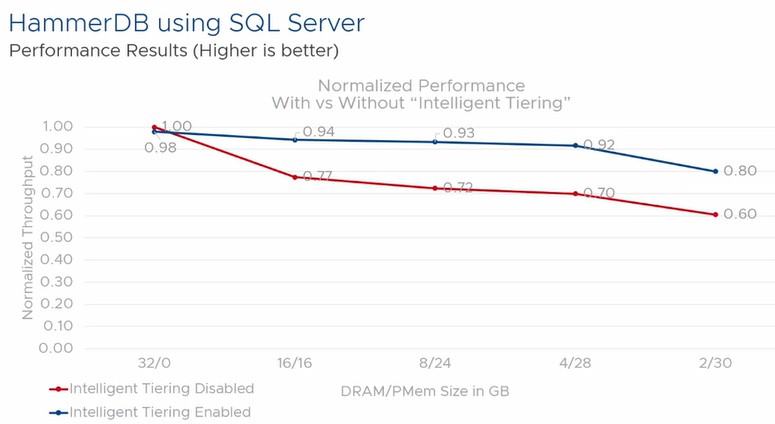
What this shows is that Windows Server 2016 running atop ESXi, even with PMEM drivers, does not do a very good job of managing the splitting of DRAM and PMEM, and by the time you are down to a mix of 2 GB DRAM and 30 GB of PMEM, the performance of the database drops by 40 percent. But with the intelligent tiering of Project Capitola turned on, ESXi makes Windows Server looks like it has a much better memory, and only loses 7 or 8 percent with a pretty skinny DRAM mix and loses only 20 percent performance with a 20 percent mix. (VMware cautioned that these were very preliminary benchmarks on very early code, and that much tuning would be done between now and when the Project Capitola software was rolled into ESXi.)
Now here is a very interesting chart that looks at the memory bandwidth for the HammerDB test, with and without intelligent tiering:
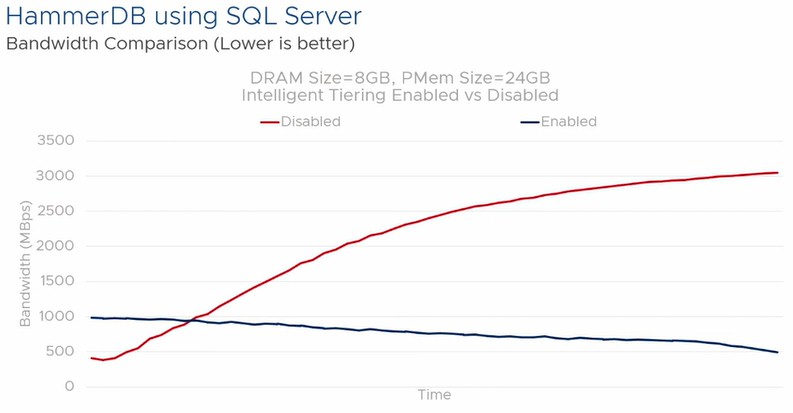
This particular configuration had 8 GB of DRAM and 24 GB of PMEM, and with the transparent tiering for memory turned on (shown in blue in the chart above), the bandwidth consumed over time actually trended down over time, rather than ballooning. More of the memory bandwidth in the box is available with the tiering than with plain vanilla virtualization of DRAM and PMEM. (It is not clear how this is done, but it is a neat effect.)
On the SPECjbb test, which is based on the TPC-E OLTP benchmark, which itself is written in Java and which implements a three-tiered, client/server stack that simulates running a warehouse distribution and back office operations of a retailer, the performance deltas were not as great, but Java is a resource hog (you always pay for application portability, one way or the other) and it is hard to squeeze performance out of it. But VMware is convinced that there is plenty of tuning that can be done.
The SPECjbb test was done on the same Dell PowerEdge machine, with a single VM that had eight vCPUs and 250 GB of vRAM instead of the 32 GB used with the HammerDB test.
Here is the normalized throughput with different memory mixes:

And here is the differences in memory bandwidth consumed:
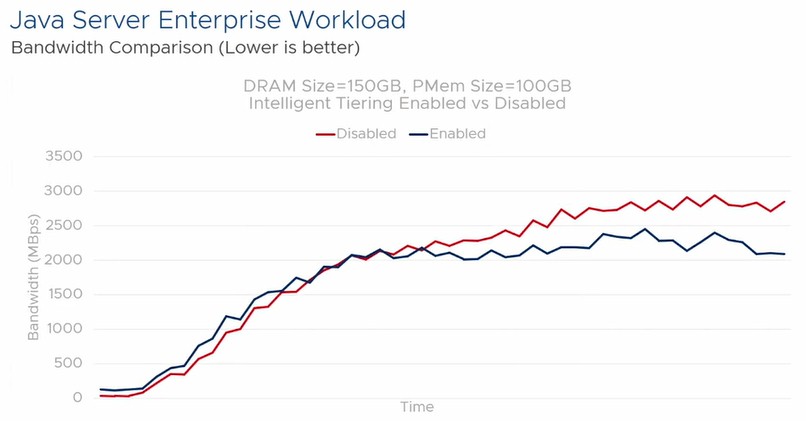
This set of results was not as impressive, but it is early days for Project Capitola. We are eager to see how this all works across a fabric of server nodes, and if VMware can take memory disaggregation and composability to its logical end – and create an open, portable hypervisor that can run on a server or DPU to provide memory composability across a fabric of PCI-Express/CXL fabrics or even over regular Ethernet protocols someday. Capitola is on Monterrey Bay – Project Monterrey being VMware’s effort to put ESXi down on DPUs – so perhaps this is all part of the long-term thinking.

The Network Binds The Increasingly Distributed Datacenter
Before founding software-defined networking startup PlumGrid and then moving to VMware when it bought his company in 2016, Pere Monclus spent almost 12 years with Cisco Systems at a time when while much of enterprise networking was still in the corporate datacenter, the shift to network virtualization and the migration …

Modern Networks For An Increasingly Distributed IT World
The shift by enterprise IT vendors from hardware box makers to software and services vendors has been ongoing for several years as OEMs have looked to adapt to the rapid changes in a tech world that is becoming application- and data-centric. Companies like Dell Technologies, Hewlett Packard Enterprise, IBM and …
VMware Bets On Enterprises Wanting Kubernetes And Virtualization Mashup
For more than two decades, VMware has made its money sensing the direction that enterprise IT is going and getting there before they do with products to addressing their needs. It would be hard to find something more fortunate than delivering enterprise-grade virtualization for X86 servers as the Great Recession …
Nice developments! Real disaggregation is getting closer and closer!
Intel could buy a PCIe switch vendor or develop the tech themselves because they already have the switching knowledge in-house as can be seen with the Xe-link implementation for Ponte Vecchio, the Barefoot Tofino and the PCIe FPGA chiplets. If they buy, it would probably be to pull the IP from the market and not in the hands of the other direct competitors….
That’s a lot of reinvention for what already exists. It’s called a mainframe.
Shouldn’t DDR latency show .01 us not .1 us? Perhaps tuning helps but latency offsets across memory tiers may be long-term punishment.
Timothy – Hopefully I am missing some key concept here. I can see and of course like where you are heading with this, but before its real it strikes me that the hardware first needs to play along. I’m thinking in terms of NUMA-like cross-node enablement in the likes of at least IBM’s Power10 or HPE’s “The Machine” on which a multi-node hypervisor could reside. Keep in mind that what a virtualizer like a hypervisor does is hide the details of hardware from higher levels of code, including the OSes. But the hardware that software expected is nonetheless still there. And that software is expecting to take some higher-level address and use it after translation to access memory anywhere. Sure, memory in a completely different system can be accessed over an I/O link, say enabled via PCI-E, but that access required some hypervisor to actually copy the contents of remote memory into local memory before access (and later put it back). We’re talking about some significant latency that the application software might not have been expecting. To get the kind of access I think you are suggesting, a core on one node needs to provide, after secure hypervisor configuring, a real address known to its node to hardware linking to another node, followed by having the linkage hardware translate that real address for access of the remote node’s memory. The multi-node hypervisor is not involved except in enabling the entirely hardware-based processing. Again, it needs the hardware architecture first and that today is proprietary. Can your secure multi-node hypervisor be created for – say – Power10? Sure, but only within the bounds of a cluster of Power10 nodes. There are other examples – IBM’s CAPI comes to mind – but it’s the systems with these specialized links that first enable the distributed shared memory that I think you are suggesting. Again, I might very well be missing something.