
If you reduce systems down to their bare essentials, everything exists in those systems to manipulate data in memory, and like human beings, all that really exists for any of us is what is in memory. We can augment that memory with external storage that preserves state over time, but to do anything useful with that old state, you have to chew on it and bring it back into main memory for manipulation or analysis.
A year and a half ago, we told you about a startup called MemVerge that had created a kind of memory hypervisor, which it called Distributed Memory Objects, to take away the pain of using Intel’s Optane 3D XPoint memory in systems and therefore make it more useful and help with its adoption in the datacenter. A lot has happened since MemVerge uncloaked from stealth mode back in the spring of 2019, and one of those things is that “big memory” is now seen as not only desirable, but necessary, for an increasingly large number of applications in the datacenter.
Which is why we believe that the era of big memory is now upon us, and that going forward there will be many different types of byte-addressable and often persistent memory that will bridge the gap between DRAM main memory and flash, which is becoming a replacement for disk drives for warm storage, pushing disks out to cold storage. There are all kinds of candidates for filling in the gap between DRAM and flash, with 3D XPoint from Intel and Micron Technology being the first out the door to be commercialized. We discussed these – conductive bridging RAM, ferroelectric RAM, phase change memory (PCM), polymer resistive RAM, polymer ferroelectric RAM, spin-transfer torque magnetic RAM, magnetoresistive RAM, metal oxide resistive RAM, carbon nanotube, and molecular memory – five years ago when 3D XPoint was first revealed by Intel and Micron, when many people (including us) were under the impression that 3D XPoint was a kind of resistive RAM but it turns out it might be a kind of PCM.
No matter what technology is used to fill that gap in cost and performance between DRAM, which is not persistent, and flash, which is, there is one thing that remains true: There needs to be a universal way to absorb this memory into the hierarchy without driving programmers nuts. And MemVerge very much wants to be that bridge that allows persistent and large main memories to work transparently on systems. And the MemVerge architecture is in no way dependent on any particular DRAM or other byte addressable memories.
We will get into the technology that MemVerge has created in a minute, but for now, what we want to do is set the stage a little more.
Big Memory, At Not Such A Big Cost
Main memory has been constrained on systems for so long that we are conditioned to think that this is not only normal, but acceptable.
To a certain extent, symmetric multiprocessing (SMP) clustering of CPUs and then its follow-on, non-uniform memory addressing (NUMA) clustering, helped to alleviate memory capacity and memory bandwidth issues in systems. But companies often ended up with a machine that had way more compute than perhaps was necessary and therefore the overall system was not optimal in terms of configuration, cost, or bang for the buck.
Server buyers paid – and continue to pay – a CPU Tax to get either memory bandwidth or memory capacity – and sometimes they have to pay both. Either they have to buy a big system with many CPU sockets and lots of memory slots and relatively skinny DIMMs to get a certain amount of bandwidth and capacity, or we have to load up smaller systems with one, two, or sometimes four sockets with fatter and much more expensive memory sticks. You pay either way.
If that wasn’t bad enough, DRAM memory, whether it is normal DDR4 in a server or HBM memory in a GPU or FPGA, is not persistent. Memory capacities have grown steadily over the decades, and that means more data can be stored within the server so it is at the ready when applications need it. But for high volume transactional systems in particular, that means much more data is at risk in the event of a power failure or software glitch. And that has meant creating battery-backed non-volatile DIMMs to allow for information in memory to be captured quickly and dumped off to persistent storage.
The dream, of course, was to have persistent memory, and many different technologies were being pursued to create a persistent, byte addressable storage device that could complement and maybe even replace DRAM in systems, as we point out above. Intel and Micron Technology worked together, and now Intel sells Optane DIMMs for its server chipsets. This is the first – but certainly not the last – persistent memory that will come to systems.
And not just because of persistence but because of the lower cost of capacity. This is important since the data that needs to be kept in memory is certainly growing at a much faster rate than the capacity of DRAM is going up and the price of DRAM bits is coming down.
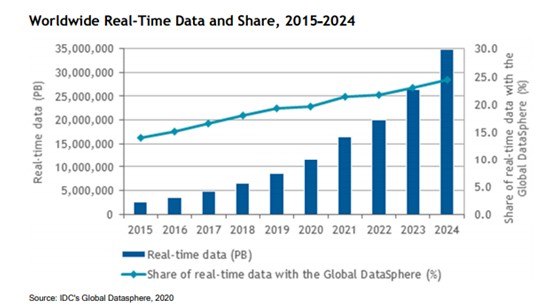
People talk a lot about the growth of data, but when it comes to systems architecture, the amount of real-time data that is required by applications is the important metric. Here is some data from IDC that not only shows the growth in real time data, but that the share of the data being created in the world and that has to be stored in memory is growing.
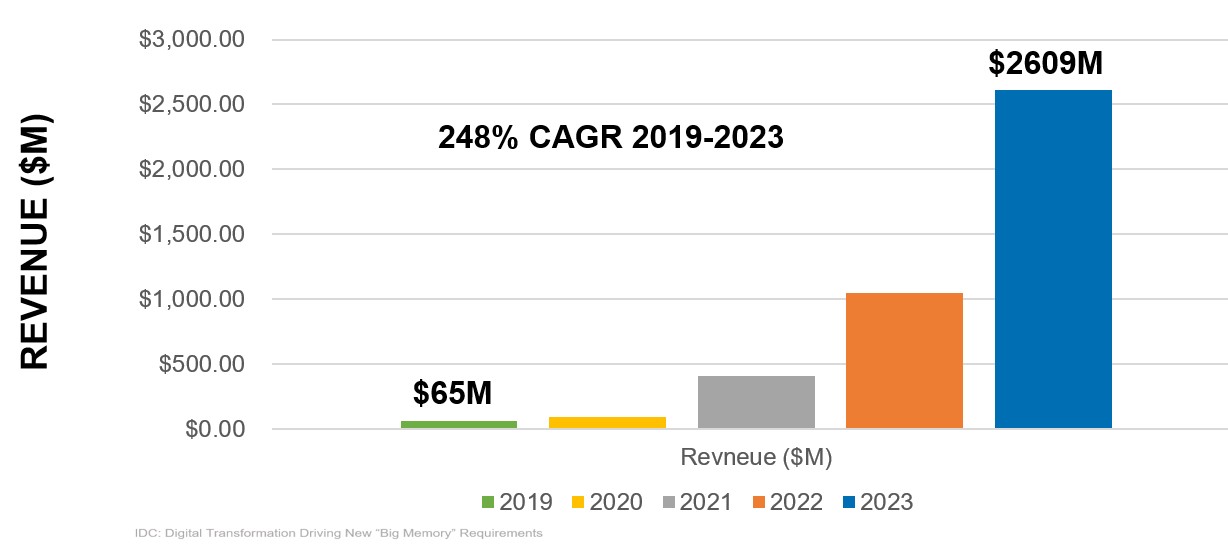
Thanks to this, the market for persistent memory, or PMEM for short when it fits in the main memory of a server, is growing, and IDC reckons that by 2023, this will be a $2.61 billion business, up explosively from a mere $65 million last year. The capacity expansion benefits from persistent memory modules is just too great for system architects to ignore, and other memory makers, particularly those selling PCM, are going to get into the act. Here are the prognostications from IDC:
And this is why data from the people at Objective Analysis and Coughlin Associates shows the rapid rise of persistent memory over the next few years, and a slope in a curve that shows PMEM shipments equaling those of DRAM shipments by 2030 or so.
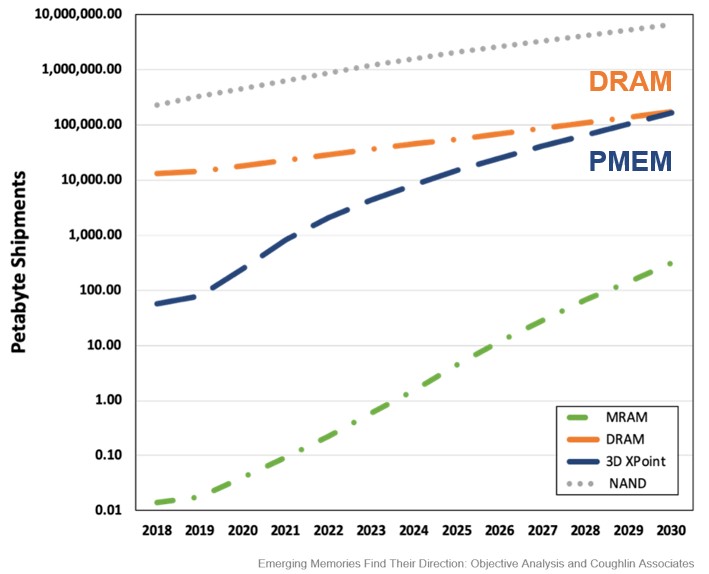
Depending on how well or poorly PMEM devices and their software stacks are implemented and the difficulty and cost of continuing to push the DRAM envelope, that PMEM curve could stay on a steep rise for longer, and the crossover could come earlier.
A lot depends on how technologies such as Intel’s Optane persistent memory develops over time and how easy or hard it is to weave it into the system and the operating system and application stack. It is fair to say that the initial Optane memory from Intel came out later than expected, was more expensive than expected, and offered lower performance than expected. And none of that really matters in the long term. Intel, to its credit, got PMEM to market and now can drive this technology. And there will be others who bring PMEM to market, and at some point Intel will have to consider opening up Optane DIMMs to makers of other systems, too.
The trick is to make this easy for system architects and programmers – and that is something that other tiered main memory systems have not offered in the past. Just as two examples, take the near and far memory in the “Knights Landing” Xeon Phi accelerators as an example. It took a lot of work to figure out one of the three different ways to use this memory hierarchy.
Similarly, even with virtual addressing between CPUs and GPUs – which IBM has with “Nimbus” Power9 CPUs matched with Nvidia “Volta” GPU accelerators and which AMD and Intel will both offer with their future CPU-GPU compute complexes – it is still tricky managing the memory across these two devices. We think that future systems will have a mix of plain vanilla DRAM for capacity and some bandwidth, HBM and maybe even GDDR for some capacity and a lot of bandwidth, and PMEM for modest bandwidth and a lot of capacity, and that will require new ways of thinking about how to bring this memory to bear.
That is where companies like MemVerge come in, and they will have to be thinking about HBM DRAM memory as well as plain vanilla DDR DRAM and PMEM and maybe even GDDR memory while we are at it, and they will have to consider CXL, CCIX, OpenCAPI, and Gen-Z interconnects for byte addressable memory, too. This big memory revolution doesn’t just end with an Optane DIMMs. That’s just the beginning.
The Memory Machine
When MemVerge uncloaked and was not yet ready with its production grade code, it talked about the software a little bit differently than it is doing starting today, when the 1.0 release of its software stack is generally available and ready for primetime.
As we explained back in April 2019, Intel has two modes for addressing Optane PMEM in its systems. There is Memory Mode, which runs the Optane PMEM as the main memory and uses whatever DRAM in the system as a kind of superfast cache for the PMEM. In App Direct Mode, DRAM stays as main memory and Optane PMEMs have to be addressed through application tweaks – never a good idea in the datacenter. Intel also allows – but doesn’t talk about – using Optane PMEM as a very fast block storage device, just one that hangs off the server memory bus instead of a PCI-Express bus supporting the NVM-Express protocol; you give up memory semantics for addressing in this mode. This is a pain in the neck, and the MemVerge stack, in essence, is a hypervisor that can use all three modes but do so in such a way that it all looks like PMEM and you don’t have to change any applications to do it. (You could say that this is the way that Intel should have done it in the first place. . . .but all’s well that ends better.)
The Distributed Memory Objects hypervisor that MemVerge originally talked about abstracted the memory modes away from Optane PMEM, making everything look like main memory, and it goes one step further and abstracts the DRAM and PMEM interfaces so they can be clustered across server nodes using Remote Direct Memory Access (RDMA) protocols across InfiniBand or Ethernet networks, all linked by a MemVerge Distributed File System that speaks both volatile byte addressable memory and bit addressable block storage protocols as needed across that memory pool. Now, the whole shebang has a zippier new name: Memory Machine. And it looks like this:
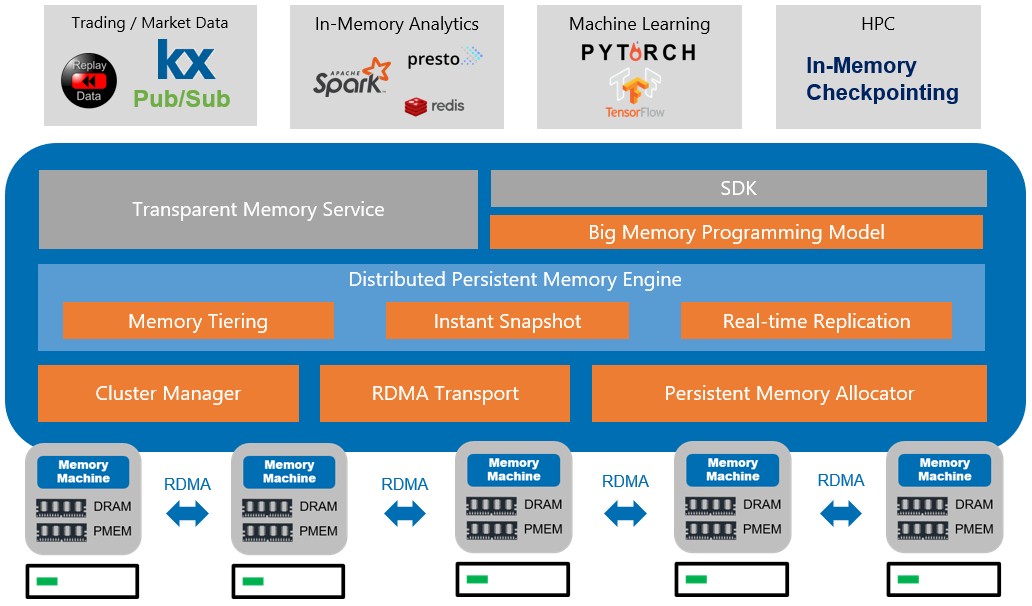
As far as we know, the scalability of the Memory Machine hypervisor and distributed file system has not changed, and it doesn’t need to at the moment seeing as though it scales across 128 nodes and up to 768 TB of main memory. That is 6 TB of Optane per node and anywhere from 128 GB to 768 GB of DDR4 DRAM per node. Data is tiered off to flash SSDs.
Before we get into performance, we want to talk about the economics of memory. According to Charles Fan, the co-founder and chief executive officer of MemVerge, DDR4 DRAM costs somewhere between $7 and $19 per GB. But Optane is somewhere around $4 and $14 per GB. As we all know, the cost per GB of DDR4 DIMMs memory goes up as the DIMMs get fatter, and this also happens with Optane PMEM, and indeed with any memory and, indeed with CPUs as the core counts go from the lower to the middle to the upper bins. It’s all about the expense of a high yield part and the value it gives to customers, and the interplay of supply and demand of those two things.
Here is how Fan reckons the pricing for DDR4 DRAM and Optane PMEM lined up when he roamed the Internet looking for public pricing from resellers back in August:

The world has needed that table for quite a while, so thanks for that. As you can see, at this point, 16 GB, 32 GB, and 64 GB DDR4 memory – we don’t know what speed Fan used here – is roughly the same in cost, averaging $8.50 per GB. Doubling the memory up to 128 GB from 64 GB increases the cost per GB by 61 percent to $13.67 per GB, and doubling the density of the DIMM up again to 256 GB increases the cost by 39 percent to $18.94 per GB. Now, the skinniest Optane memory is 128 GB, and it is 29 percent the cost, or $4 per GB, of the DDR4 memory of equal capacity. The 256 GB Optane PMEM is 37 percent of the cost of the 256 GB DDR4 memory, and there isn’t even a 512 GB DDR4 option for servers, but it is 4X the memory capacity for essentially the same price as a 128 GB memory stick. The point is, the bigger the memory footprint, the bigger the price gap between DDR4 memory and Optane PMEM memory in the DIMM form factor.
On a device by device comparison, we all know that Optane PMEM is slower than DDR4 DRAM, but it is a difference that may not make a lot of difference when it comes to applications. Yes, it would have been better if Optane PMEM was here earlier, was faster, and less expensive as Intel had hoped. But the performance that MemVerge is seeing with its Memory Machine hypervisor and distributed file system shows that it doesn’t make much of a difference. The combination of memories and their relative costs within a system is what is interesting.
Here is the performance of the Sysbench benchmark test running against the MySQL database in DRAM only, PMEM only, and mixed PMEM-DRAM setups:
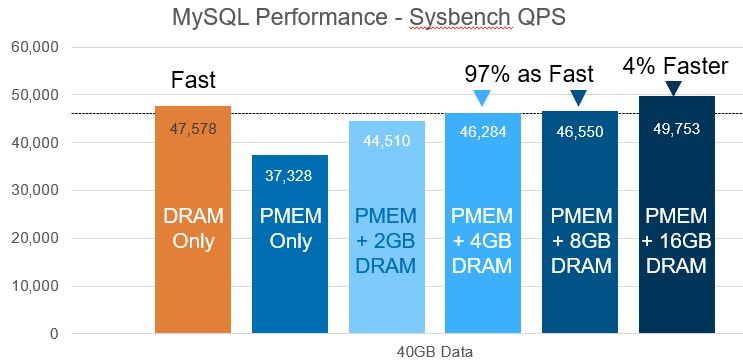
It is not clear how much memory is being used here, but given that Optane PMEM’s smallest increment is 128 GB, it is probably that. With all DRAM in the system, it can do 47,579 queries per second on the Sysbench test, and with PMEM only running the Memory Machine software stack, the machine does 21.5 percent less work at 37,328 QPS. The 128 GB of DRAM costs $1,750 and the 128 GB of Optane PMEM costs $512, so that works out to 2.7X times better bang for the buck in raw memory performance on Sysbench for the Optane PMEM versus the DDR4 DRAM. Now, if you inch up the DDR4 DRAM in the Optane PMEM setup, you can start using DRAM as a fast cache for the Optane PMEM, and you can start inching up the performance. With 16 GB of DDR4 plus the 128 GB of PMEM, you get 4 percent more performance than the DRAM alone, and it only costs $662 for the two types of memories. That works out to 2.8X better memory bang for the buck on the Sysbench test. (We did the relative price/performance based on the memory pricing that Fan gathered.)
One thing to note is that on the Sysbench running MySQL test at least, the benchmark is somewhat sensitive to the memory latency, as the delta between DDR4 and Optane shows, but this can be overcome with some modest caching using DDR4 memory in front of the Optane memory. It takes surprisingly little DRAM, in fact, to make a difference. And the resulting memory complex still only costs 38 percent of the all-DRAM setup.
MemVerge has seen some initial traction in the financial services market, according to Fan, and has done some testing using the kdb+ database from Kx Systems, which is a columnar time series database popular for high frequency trading systems. The benchmark below, which is a performance stress test, illustrates the idea that a mix of DRAM and PMEM can radically boost performance over and above DRAM alone – and at a much lower price point:
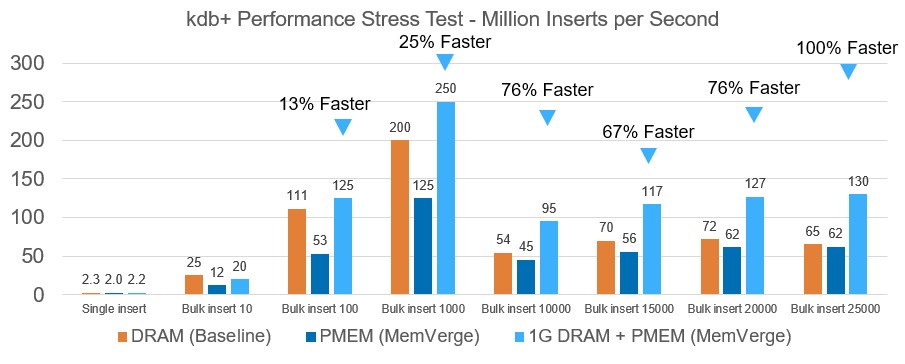
Zero I/O snapshotting of in-memory data is a big feature of the Memory Machine stack, and MemVerge wants to prove some points with this and used the kdb+ database to make those points. Take a look:
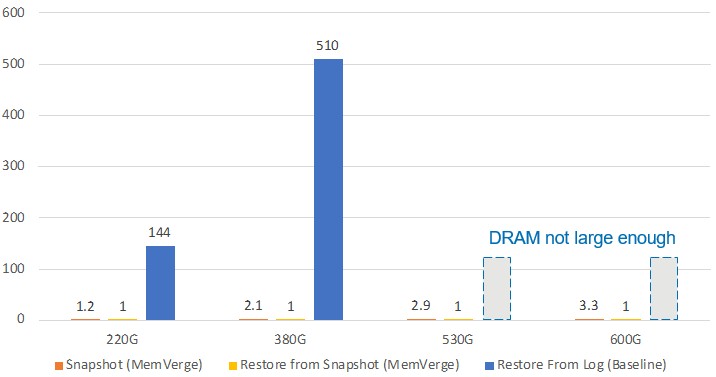
The Y axis is how many seconds it takes to do a snapshot or restore and the X axis is the size of the database. Snapshotting is not really practical with an all-DRAM system, but with the Memory Machine stack, it can take from 1 second to 3 seconds, depending on the size of the kdb+ database. The right column in each database size is the time it takes to restore a database from the log files in kdb+. It takes 144 seconds for the 220 GB database and 510 seconds for the 380 GB database, and the servers tested can’t even restore a 530 GB database or a 600 GB database because their memory footprint was not large enough. It took one second flat in all cases to restore a Memory Machine snapshot of the kdb+ database.
That is going to blow a lot of companies away. And not just in the financial services sector, either.
“Our expectation is that all applications will live in memory,” Fan tells The Next Platform. “Today, because of the limitations on the DRAM side and on the storage side, most applications need both to have mission critical reliability. But we believe because of new and future developments in hardware and software over the next ten years, we think most of the applications will be in-memory. I think that is a bold statement, but we think it is a true statement as well.”
The Memory Machine software comes in two editions. The Standard Edition creates a pool out of DDR4 memory and Optane PMEM provides service level agreements for memory slices – what are actually called memory machines – for applications. The Standard Edition also has “time machine” undo and restore capabilities as well as autosaving of checkpoints. It costs $2 per GB per year in each system it runs on. The Memory Machine Advanced Edition adds thin cloning and snapshotting as well as fast crash recovery, which makes memory highly available rather than just fast or capacious as the Standard Edition does. The Advanced Edition costs $5 per GB per year, and includes all of the functionality of the Standard Edition obviously. Let’s do some math. If you wanted a full 6 TB memory footprint today in a two-socket Xeon SP server, it would cost $85,156 for the Optane memory and $30,720 a year to license Memory Machine with all of the bells and whistles. That may sound like a lot, but it isn’t for a fintech machine that is playing with millions of dollars per second. It seems far more likely that companies will have more modest footprints using 128 GB Optane sticks, which would be only 1.5 TB of memory for $6,144 plus $7,680 to license the memory machine stack and get considerably more performance and resilience out of the server.
This is the kind of math that a lot of companies will be doing, and we don’t think it will be long before Intel tries to buy MemVerge. The company raised $24.5 million in its Series A funding back in April 2019 when it uncloaked, with Gaorong Capital, Jerusalem Venture Partners, LDV Partners, Lightspeed Venture Partners, and Northern Light Venture Capital kicking in the dough. In May this year, MemVerge announced another $19 million in funding, and – you guessed it – Intel Capital was the lead investor. Cisco Systems and NetApp also kicked in funds, as did the original VCs and a few others.
We hope that MemVerge can stay independent and that new memory technologies come to market that Memory Machine can make simpler and easier to use. The datacenter will be better for it.


Why Memory Enclaves Are The Foundation Of Confidential Computing
Sponsored Feature There are tens of millions of lines of code in thousands of software programs, on a typical server in the datacenter. All of which collectively present a huge attack surface for various kinds of malware. And no matter how hard vendors and open-source project developers try to secure …

The Eternal Battle Between InfiniBand And Ethernet In HPC
It is always good to have options when it comes to optimizing systems because not all software behaves the same way and not all institutions have the same budgets to try to run their simulations and models on HPC clusters. For this reason, we have seen a variety of interconnects …

CXL And Gen-Z Iron Out A Coherent Interconnect Strategy
To one way of looking at it, a reprise of the Bus Wars from days gone by in the late 1980s and early 1990s would have been a lot of fun. The fighting among vendors to create standards that they controlled ultimately resulted in the creation of the PCI-X and …
A lot of these performance gains may be predicated on coupling a DRAM module with an Optane module on each memory channel, thereby getting full DRAM performance from the memory subsystem. This assumption holds for DDR4 and for first generation DDR5, but what happens when systems move to DDR5-6400 in 2023 and drop to one DIMM per channel? Will servers give up an entire DRAM channel to a low performance Optane module? Not likely. I anticipate system infrastructure moves Optane to CXL where its performance doesn’t hinder the entire system. I think MemVerge is an interesting abstraction, and agree that rewriting software is a hill too steep to climb, but we really need to see how it scales in CXL systems.