

If you don’t measure something, you can’t manage it. And if you don’t set ambitious goals, then you can’t attain them.
This is why AMD in 2014 took on the task of raising the efficiency of its mobile processors with its 25X20 program, which sought to increase the power efficiency of these machines by a factor of 25X by 2020. There are 6.2 billion client devices in the world this year, according to Gartner, and PCs represent about 1.5 billion of them and laptops just shy of 1 billion of those. By AMD’s own math, which it did in June 2020, it was able to increase energy efficiency of its mobile processors by a factor of 31.7X, which was done by pulling a number of different levers at the same time. This meant developing a much better CPU core, a system-on-chip wrapped around it, real-time power management, and silicon-level power optimizations. When you do the math, AMD reduced the average compute times for common tasks on mobile PCs by a factor of 80 percent from 2014 through 2020, which is a 5X increase in throughput performance, while at the same time decreasing power consumption for its processors by 84 percent. (This compared the mobile CPU and GPU of 2014 vintage to the Ryzen 7 4800H with an integrated “Vega” Radeon GPU.)
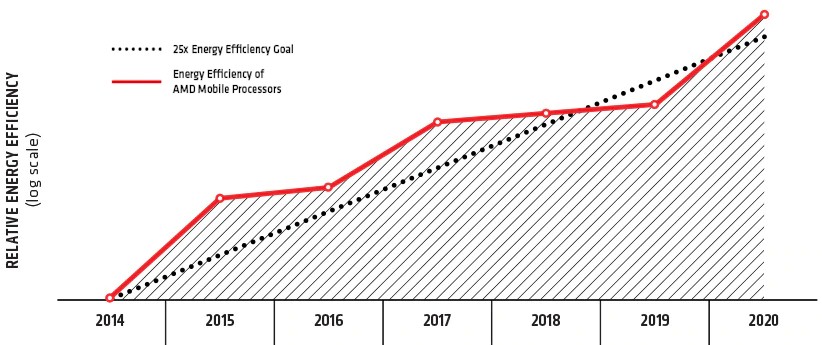
Progress comes in fits and starts in any effort to boost performance and increase energy efficiency at the same time, of course. And as you can see from the chart above, AMD almost didn’t make it to the goal in time, then overshot it a bit. The rate of change of energy efficiency improvement at AMD was twice as fast as the mobile CPU/GPU industry at large.
And with its 30X25 effort launched today for server platforms. AMD is betting that it can deliver a 30X increase in energy efficiency with hybrid CPU-GPU systems aimed at AI training and HPC simulation and modeling workloads by a factor of 30X between 2021 and 2025. That’s only four years, and if AMD can do this with the combination of its Epyc CPUs and Instinct GPU accelerators, then it will be running at a factor of 2.5X faster improvement than the compute nodes being built by the industry at large.
Those rates of change, by the way, are calculated by none other than Jonathan Koomey, who is an expert on energy efficiency and who we talked to in January 2020 about bending the efficiency curves for supercomputing. Koomey was a research associate at Lawrence Berkeley National Laboratories for nearly three decades as well as a visiting professor at Stanford University, Yale University, and the University of California at Berkeley and an advisor to the Rocky Mountain Institute for nearly two decades.
This prediction — that AMD can outdo the industry by a factor of 2.5X in terms of energy efficiency increases — assumes, of course, that other suppliers of CPUs and GPUs hew to the current efficiency improvement line, which probably will not be the case. Just getting to new manufacturing processes helps Intel CPUs immensely on this front, and it is also important is that no one is committing to changing energy efficiency by 2.5X, but increasing the rate of energy efficiency change by a factor of 2.5X. Just by having memory coherence and faster interconnects as well as die shrinks for CPUs and GPUs will help, and so will integrated, high bandwidth memory on both the CPU and GPU. 3D packaging will help, too, so the throughput will definitely keep increasing even if the speed of any particular job may not. So we have to be careful with words and meanings here. If you want to get a clock cycle to do more work on a single thread — which is what most of us want — then it takes working and reworking and reworking of the instruction stream pipeline to wring more and more work out of each clock. And to be fair, CPU architects and now GPU architects have done a pretty damned good job on this front over the past two decades and there is no reason to believe they will run out of ideas.
If AMD didn’t think it could hit its efficiency goals and performance goals in four years, it would not have brought it up. And frankly, if AMD wants to hold the line and get all of the big ten-exaflops supercomputer deals in 2025 or 2026 so, it is going to have to get a 30X increase in performance per watt on AI training and HPC work. If it doesn’t, then a ten-exaflops machine will burn hundreds of megawatts and cost hundreds of millions of dollars a year in electricity to power and cool it.
We could not find out what the baseline machine was for the 25X20 mobile PC effort, but for the server, but we know for sure that with the 30X25 effort, AMD is setting a baseline for energy efficiency with its “Milan” Epyc 7002 CPUs paired with its “Vega 20” Instinct MI50 GPUs. So AMD is stepping back one generation to give that 30X a bit of a head start. …
The rate of improvement in energy efficiency for the industry as a whole for hybrid CPU-GPU systems also sets the real baseline that AMD is measuring itself against. Here’s the thinking on that:
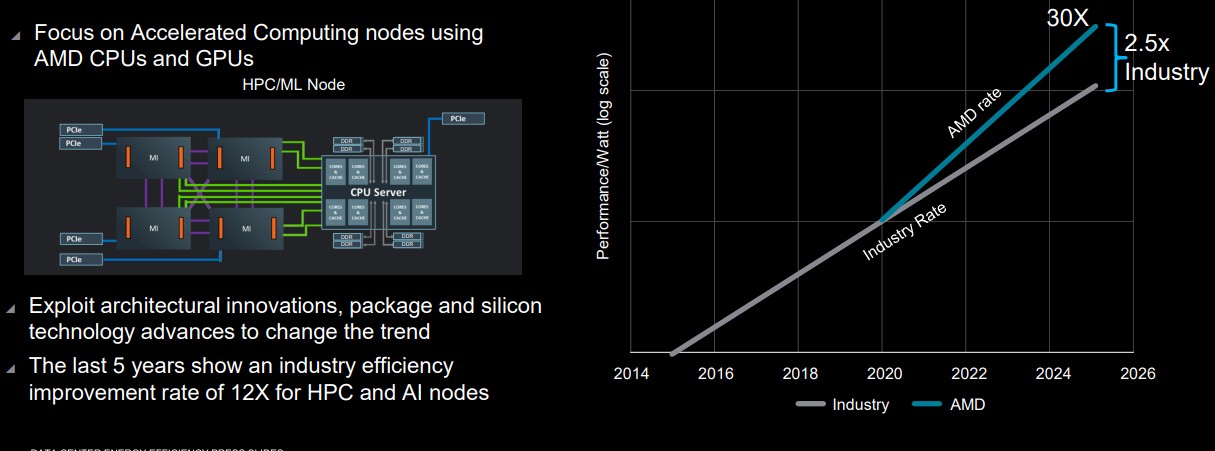
The plot line for the industry average is 12X over the six years from 2015 through 2020 (we know the chart says five years, but the data is inclusive of the 2015 and 2020 dates). And here is the fine print that was on this chart that you could not read if we didn’t zoom in: “Based on 2015–2020 industry trends in energy efficiency gains and datacenter energy consumption in 2025. Includes AMD high performance CPU and GPU accelerators used for AI training and High Performance Computing in a four-accelerator, CPU hosted configuration. Goal calculations are based on performance scores as measured by standard performance metrics (HPC: Linpack DGEMM kernel FLOPS with 4k matrix size. AI training: lower precision training-focused floating point math GEMM kernels such as FP16 or BF16 FLOPS operating on 4k matrices) divided by the rated power consumption of a representative accelerated compute node including the CPU host + memory, and four GPU accelerators.”
Now we know the base line, and the chart above has a log scale, so those straight lines are both exponential. They just have different rates of improvement.
Here is a very interesting chart, which plots datacenter CPU power consumption against the expected datacenter HPC and AI hybrid CPU-GPU system power consumption. Somewhere around 2030 or so, AI and HPC workloads will dominate power consumption. If current trends persist. Which they can’t. And they won’t. But leave that aside for the moment.
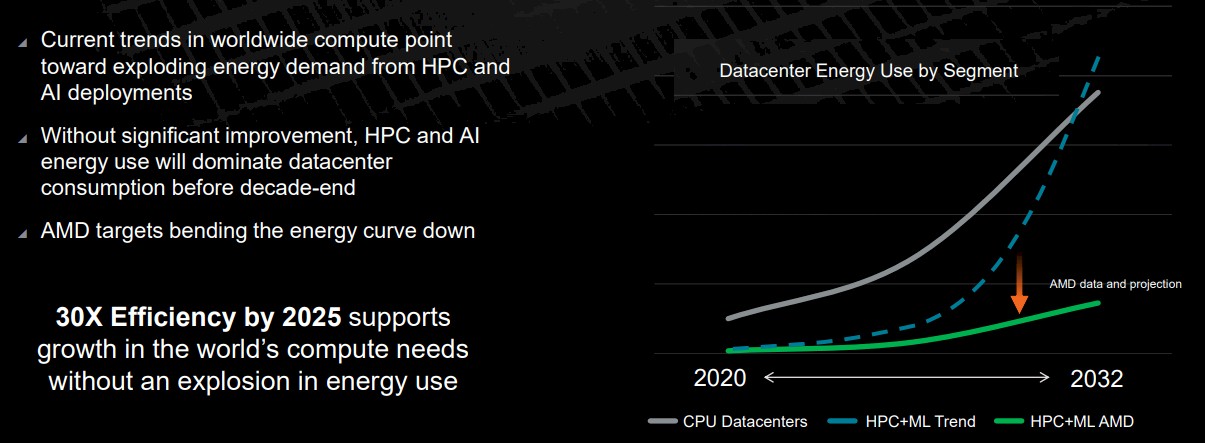
The important thing is that AMD is showing how it plans to bend the curve down, and others are on the same path. Which is great in case AMD fails. (We are reasonably sure that AMD has a handle on this, and if it says it can do 30X, we figure it figures it can actually do 35X to 40X.)
And here is the fine print that accompanied this chart above: “Server growth is from independent research data further extrapolated to 2030. This sets a compute demand. This is then combined with performance per watt trends to calculate the power consumed for that compute demand, both for the industry trend line and the AMD projection line. Performance per watt is calculated by the CPU socket and GPU node power consumptions are based on segment-specific utilization (active vs. idle) percentages then multiplied by PUE to determine actual energy use for calculation of the performance per watt.”
So how is AMD going to do this? GPU accelerators will help, says Sam Naffziger, an AMD Fellow who had the same role at Hewlett Packard and Intel in recent years and who worked on processor design and power optimization over that time. So will a shift to domain-specific accelerators (some of them molded from FPGAs from Xilinx, once that acquisition deal by AMD is done). The move from 2D chiplet packages to 3D chiplet stacks is also going to help, as well advances in the Radeon Open Compute (ROCm) GPU compute environment and the Vitis FPGA compute environment, which in the end have to merge to create something akin to what Intel is talking about with its oneAPI effort.
“This is really hardware plus software to make things easier,” says Naffziger. “The first exascale systems that we are involved with will greatly accelerate the ROCm stack to maturity and efficiency. And we are going to learn to use heterogeneous compute better and not just shuffle bits around all over the place, wasting power. As for how much is hardware improvement and how much is software improvement, it is hard to untangle those because they are inextricably linked. Engaging in hardware-software co-design, these accelerators are in a lot of ways software in silicon. We see where the bottlenecks are in our existing loops and figure out how to accelerate them with special purpose hardware. So it is a blurry boundary.”
What has happened, and what will make that 30X25 curve sawtooth a bit like the 25X20 curve for mobile PC compute did, is that hardware will lead and then software will catch up. We have certainly seen that effect with machine learning training and inference on CPUs and GPUs, where the hardware is created with certain raw capabilities and then the software is cooked and provides dramatic step functions in performance increases beyond that until there is no more to be done. Then, a new hardware architecture comes out, and software is gradually tuned for it.
The hyperscalers and HPC centers of the world, along with vendors such as Nvidia, Intel, and AMD, are pulling all of those levers to the point where they are bending a little. Which is just the right amount of force to move compute energy efficiency forward in the datacenter. Every picojoule consumed is sacred, and the sooner we get used to that idea, the happier we will all be.

Samsung Shows Off CXL Server Memory Expander
People have been talking about CXL memory expansion for so long that it seems that it should be here already, but with the dearth of CPUs that can support PCI-Express 5.0 peripherals we have to be patient a little bit longer. To whet the appetite of system architects who will …

Google Joins The Homegrown Arm Server CPU Club
If you are wondering why Intel chief executive officer Pat Gelsinger has been working so hard to get the company’s foundry business not only back on track but utterly transformed into a merchant foundry that, by 2030 or so can take away some business from archrival Taiwan Semiconductor Manufacturing Co, …

The Dance Between Compute And Network In The Datacenter
In an ideal world, there is a balance between compute, network, and storage that allows for the CPUs to be fed with data such that they do not waste too much of their processing capacity spinning empty clocks. System architects try to get as close as they can to the …
Be the first to comment