

There’s an AI unicorn startup you might not have even heard of. That is, if you live in the Western hemisphere.
For those who follow AI processor companies, it is far too easy to overlook the innovations of APAC companies beyond the hyperscalers (Alibaba, Tencent, etc.). We pay attention here in the West to the largest chipmakers and key AI silicon startups but we too often overlook Asia, in part because so many of the technologies developed there make big inroads here. There are good reasons for that, of course, but that’s an economic, political, security, and legal conversation you can find elsewhere.
We’re talking now about Preferred Networks, the billion-dollar AI startup no one seems to talk about. That is, until they cannot be ignored. For instance, when they shoot to the top of the Green 500 list of the world’s most efficient high performance supercomputers. The company reached #1 in June last year by hitting 15% above the previous winner, achieving 21 GF/Watt with its MN-Core based systems, the outcome of work between Preferred Networks and Japanese research centers, Kobe University and RIKEN.
Another reason we don’t hear much about Preferred Networks, despite a big supercomputing achievement? Because they don’t talk much publicly—and there is very little about their role in industrial and research use, even though we have every indication they have some serious investors and users eager for a homegrown AI chip and server.
Preferred Networks had its first seed round in 2014 from Quantum Biosystems, a Japanese company focused on using quantum mechanics as the backbone of a new type of DNA sequencing approach. This was an interesting investment from a company that itself was founded in 2013. Since then, they’ve collected more venture capital from a number of industrial giants in Japan, including Hitachi, Toyota and Chugai Pharmaceutical with investment from semiconductor maker Tokyo Electron in addition to private equity and venture firms. Their most recent sizable investment came from JXTG Holdings, specifically to fund a joint project around automation and optimization in oil refineries.
Preferred Networks has the MN-Core at its roots and is focused on both low-power embedded processing in robotics and autonomous platforms as well as in the datacenter. This is no an accelerator, but a processor specifically focused on training AI models with the ability to handle lower power inference.
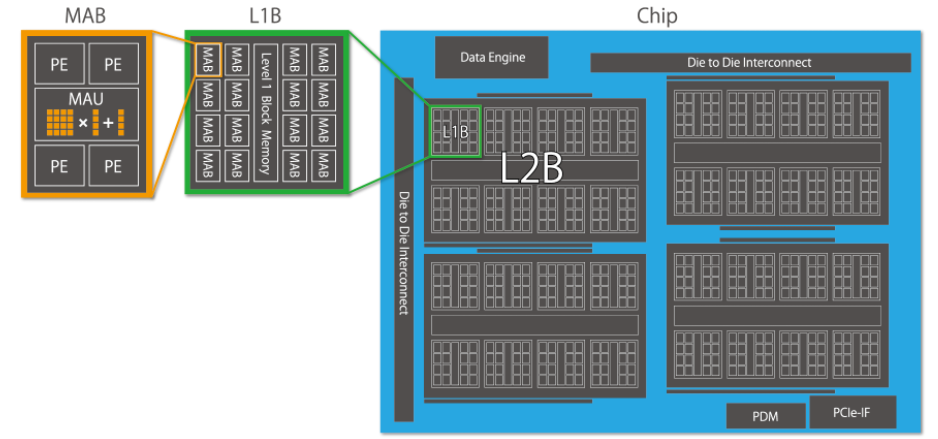
 The architecture itself is incredibly simple, even as increasingly pared-down AI devices go. The devices are based on matrix arithmetic units densely packed and is completely SIMD-based, which means the device can handle large model sizes. The architecture is based on one of the matrix units with four processor elements to form a block. Each of the processing elements is equipped with integer units.
The architecture itself is incredibly simple, even as increasingly pared-down AI devices go. The devices are based on matrix arithmetic units densely packed and is completely SIMD-based, which means the device can handle large model sizes. The architecture is based on one of the matrix units with four processor elements to form a block. Each of the processing elements is equipped with integer units.
The MN-Core has a total of 2,048 matrix blocks, 512 MABs per die, are integrated into one package, which comprises four dies. These are hierarchically arranged and have multiple modes for interlayer data movement, such as scatter, gather, broadcasting, and reduction. This enables flexible programming, the company says.
Preferred Networks also has a PCIe board where their MN-Core is mounted which they say consumes around 600 Watts. Their MN-Core server unit, seen at the top in its Green 500 supercomputer, is a 7U-size rack-mount server developed for mounting four MN-Core Boards.
 In addition to the high-performance CPU and large capacity memory, a specifically designed internal structure, combined with 12 powerful built-in fans, provides an air-cooling system against heat generated by four MN-Core Boards. With four MN-Core Boards, its computation speed per node is around 2PFLOPS in half precision, peak projection.
In addition to the high-performance CPU and large capacity memory, a specifically designed internal structure, combined with 12 powerful built-in fans, provides an air-cooling system against heat generated by four MN-Core Boards. With four MN-Core Boards, its computation speed per node is around 2PFLOPS in half precision, peak projection.
Today, the company announced its new MN-Core Compiler, which it will be presenting at the VLSI Symposia. This will allow compilation on PyTorch, PFN’s primary deep learning framework, for fast execution on MN-Core without any major changes, the company says. “PFN’s tests showed that the computations using MN-Core and the new compiler were more than six times faster for instance segmentation and nearly three times faster for graph processing than MN-2, PFN’s previous generation of supercomputer equipped with general-purpose GPUs. PFN sees the new capability as a competitive advantage in its research and development as deep learning datasets and models grow increasingly large and complex.”
Architecture aside, the weight of the investors and the amount show Japan is placing its bets on a homegrown processor for industrial and HPC deep learning. With research centers like RIKEN, among others, innovating in supercomputing as well, Japan is becoming a center of systems innovation that is worth paying close attention to.


Inside Look Inside Japan’s ABCI AI Supercomputer Upgrade
Japan is home to one of only a few designated AI supercomputers open to public and private research partnerships via its ABCI (AI Bridging Cloud Infrastructure) system, which is set to reach nearly an exaflop of single-precision performance for ML workloads following a recent upgrade. The Fujitsu-integrated machine has around …

AIST Taps HPE And Nvidia For Next-Gen AI Cloud Machine
The National Institute of Advanced Industrial Science and Technology (AIST) in Japan is going to be installing the third generation of its AI Bridging Cloud Infrastructure 3.0 supercomputer. The machine will consist of thousands of Nvidia’s current “Hopper” H200 generation of GPU accelerators, which is not surprising. But interestingly, it …

Japan Strikes First in Exascale Supercomputing Battle
RIKEN and Fujitsu announced that they have finished the design of the Post-K exascale platform, paving the way for production of the hardware, followed by shipping and installation. Still in the running to be the world’s first exascale system, Japan’s Ministry of Education, Culture, Sports, Science and Technology (MEXT) is …
Be the first to comment