

That is not a typo in the title. We did not mean to say GPU in title above, or even make a joke that in hybrid CPU_GPU systems, the CPU is more of a serial processing accelerator with a giant slow DDR4 cache for GPUs in hybrid supercomputers these days – therefore making the CPU a kind of accelerator for the GPU. Rather, we meant DPU, as in data processing unit, which is rapidly becoming the common term used for something smarter and more sophisticated than a SmartNIC that is used to offload all kinds of processing from servers and sometimes the network in distributed computing systems.
By buying Mellanox Technologies this year for $6.9 billion, Nvidia did not just get a company that sells Ethernet and InfiniBand switch ASICs and whole switches, or ConnectX network interface cards and their ASICs, or cables to link them together, or software to lash it all together into a fabric. Nvidia got a much more sophisticated DPU based on the Arm-based Bluefield processor, and according to its latest roadmaps, it plans to offer machine learning acceleration based on GPUs in future DPUs, which we discussed back in October at the fall GPU Technology Conference. (GTC is going to have to be renamed if Nvidia is going to supply CPUs and DPUs as well as GPUs. Hmmm. . . . Processing Unit Technology Conference, or PUTC, is amusing.)
The evolution – in almost the genetic sense – of the DPU from the network interface card, or NIC, to the SmartNIC to its emerging DPU form is an interesting development for the public clouds and even the hyperscalers, as well as large enterprises with complex workloads and a desire to boost the efficiency of their IT infrastructure. But we wanted to know how the DPU is going to affect supercomputing, and as part of our digging around during the SC20 supercomputer conference, we had a chat about the prospects for the DPU in traditional HPC simulation and modeling, getting a bit more precise than our lengthy Q&A interview with Nvidia co-founder and chief executive officer Jensen Huang back in April when the Mellanox deal closed and again when we did a video interview with Huang in the wake of the GTC fall conference back in October when more of Nvidia’s long-range plans were divulged.
To learn more about what Nvidia is calling the “cloud native supercomputer,” we had a chat with Gilad Shainer, senior vice president of marketing for HPC and AI networking at Nvidia.
“Today, if you are building a system, you have to decide what platform you want to build,” explains Shainer. “If you want to build a supercomputer, you are building something that is powerful and you are killing yourself to get the absolute maximum performance you can get. But all of the additional stuff for managing a multitenant environment, that is not your focus. So you don’t really have isolation between users and security between users; there is a scheduler that is submitting jobs, and unlike a public cloud, you trust those users. But if you look at the public cloud, isolation and security is the number one priority and performance comes further down the list.”
And we would add, absolute price/performance for the HPC workload over a given unit of time is also way down on the list, with HPC capacity costing anywhere from 5X to 9X what it costs to build it in-house over the same runtimes. But you get the benefit of flexibility with a cloud, and that has monetary and technical value, too.
What Nvidia wants to do – and the DPU is integral to this – is merge these two platforms – the performance of traditional HPC supercomputers and the security and isolation of the public cloud – into this new thing called the cloud native supercomputer. Like this:
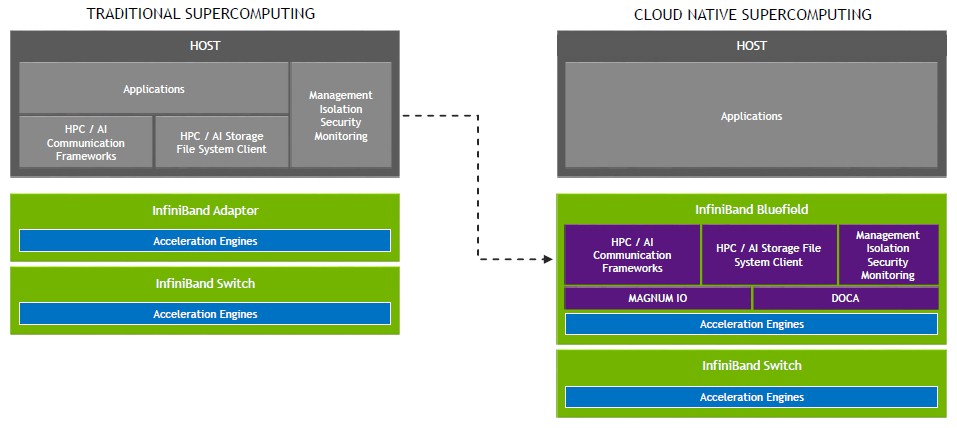
The Bluefield DPU, and one that will soon be accelerated by GPUs for sophisticated, AI-enhanced security, is the key to this change, says Shainer. The reason that virtual networking and virtual storage as well as encryption and other security software and multitenancy systems software like Kubernetes containers or hypervisors with virtual machines are generally not on supercomputers is because until now, all of this software had to run on the host systems in a cluster. Now, all of this stuff this can be moved down to a ConnectX SmartNIC that is enhanced with a Bluefield multicore Arm processor, which becomes a trusted domain, and taken off of those CPUs so they can focus on actually running the simulation.
We think this concept will be taken a lot further than even Shainer or Huang before him talked about. We submit that there will also be a case for offloading code associated with managing the GPUs from the CPUs to that DPU, and in future systems, and moreover that the DPUs could be disaggregated from the CPU and GPU compute completely and become a kind of center of gravity in the distributed system, managing the movement of data to the CPUs and GPUs and in fact, treating the CPU like a serial compute accelerator and the GPU as a parallel compute accelerator for itself. The actual application code will, in this scenario, actually run on a cluster of DPUs, all stitched together in a fabric, with banks of CPU and GPU accelerators also hanging off that fabric and all disaggregated and composable into blocks that make sense as workloads change. We may, in fact, have to rename these devices, calling one the Serial Processing Unit, or SPU, and the other the Parallel Processing Unit, or PPU. This may be taking it too far, we admit. HPC codes today are written to run on CPUs that are indeed central with GPU offload when they have it. But if CUDA can have directives to push code to GPUs we don’t see why it can’t have directives to execute serial portions of the code on fast CPUs, er, SPUs.
Aside from the architectural advantages of inserting DPUs into the supercomputer architecture, there are some practical ones. With the DPU, HPC centers will be able to create what Shainer calls “virtual protected enclaves” inside of a supercomputer, where everything in that enclave is encrypted and isolated and secure, and therefore can run workloads that deal with sensitive, personal information that is required to be isolated and secured by federal and state laws.
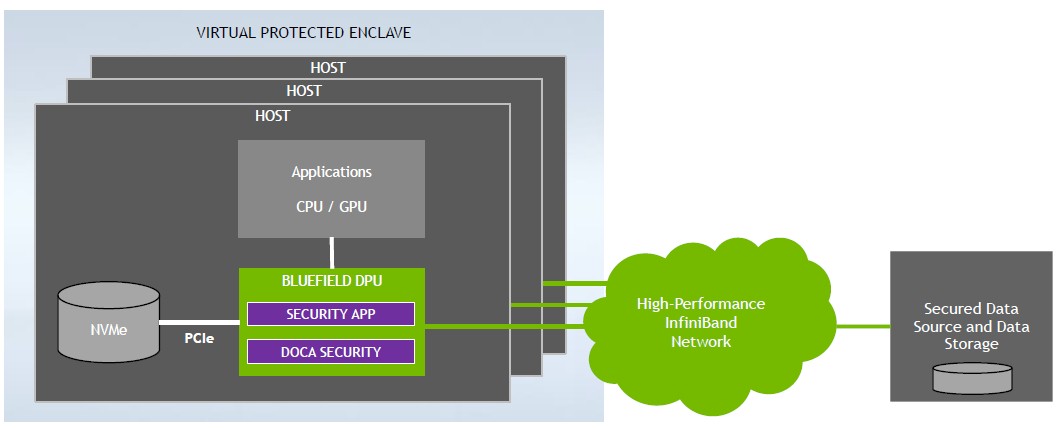
Think about patient records in the healthcare industry. It is not easy to run any HPC workload that needs these today on a supercomputing system because they lack the security features for the data even if they do have the absolute best security in the world around their perimeters.
Equally importantly, the parallel file system clients that would normally run on the host systems to provide them access to data can be pushed down to the DPU (if it is on the PCI-Express bus) or out to the DPU (if it is disaggregated by linked to the host over the fabric). Like this:
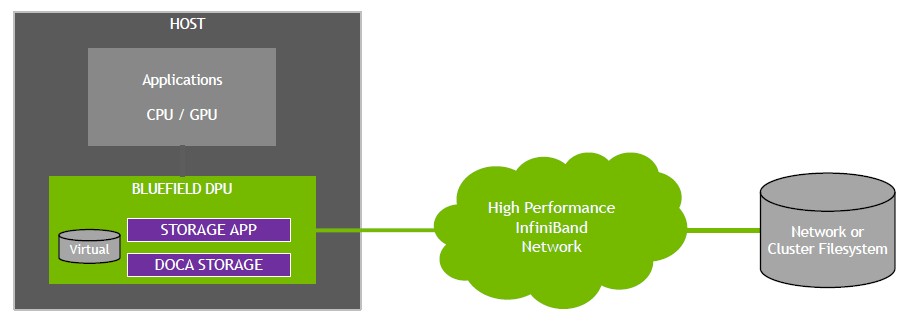
The Bluefield processors on the DPU are pretending to be the CPU for the file system and pretending to be the file system for the CPU, and doing all of the in-between work for the CPU, freeing up its resources, without having to make any substantial changes in the file system software or hardware.
And perhaps most importantly, HPC and AI communication frameworks can be offloaded to the DPU as well, much as Mellanox has been offloading MPI operations to its ConnectX network interface cards for many, many years to free up resources. To illustrate this broader principle, Nvidia has worked with DJK Panda’s MVAPICH group at Ohio State University to run some benchmarks – specially the Parallel 3D Fast Fourier Transform tests – on machines with a Bluefield SmartNIC installed, and was able to get a 21 percent boost in application performance by pushing certain functions down to the SmartNIC. Take a look:
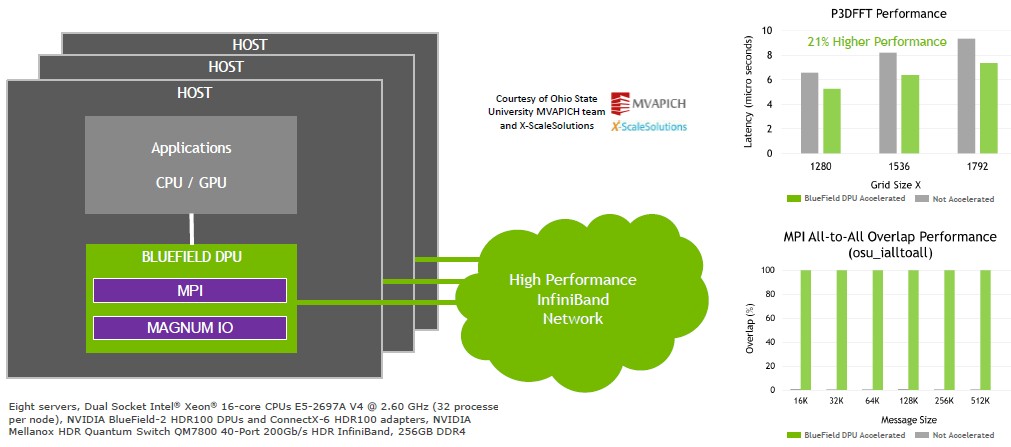
A more capable DPU, such as those with GPU accelerated security and encryption, would obviously also be able to provide the multitenancy as well as the MPI all-to-all offload capability shown in the tests above. As you can see, 99 percent of the raw MPI all-to-all communication is moved from the CPUs to the DPUs and with just this one change to the MPI code, the P3DFFT application ran an average of 21 percent faster across three different grid sizes. Admittedly, this particular offload won’t be necessary when the next generation, NDR Quantum-2 400 Gb/sec InfiniBand that Nvidia previewed two weeks ago starts shipping in the second quarter of 2021, since the Quantum-2 switch accelerates all-to-all MPI communications itself. But it illustrates a point: What the switch can’t accelerate, the DPU can, and it can do it quicker (meaning time to market) than a switch upgrade because it is implemented in software.

How Are GPUs Going To Change Your Working World? It’s AI, Everywhere
SPONSORED Mention GPUs these days, and you will naturally think about how they can accelerate the most challenging AI and machine learning workloads as well as how they are used in gaming platforms. But that’s only part of the story. The same platforms that underpin advances in both extreme AI …
After The 2022 Bump, Arista Is Back To The Grind In 2023
For Arista Networks, the poster-child of hyperscaler and cloud build networking that, more than any other vendor, has championed merchant silicon and Linux as the basis of a modular network operating system, 2022 was a bumper crop year. This year, there are many new things going on, but the compares …

JAMSTEC Goes Hybrid On Many Vectors With Earth Simulator 4 Supercomputer
Sponsored When it comes to compute engines and network interconnects for supercomputers, there are lots of different choices available, but ultimately the nature of the applications — and how they evolve over time — will drive the technology choices that organizations make. And such is the case with the new …
Be the first to comment