

If this is the middle of November, even during a global pandemic, this must be the SC20 supercomputing conference and there either must be a speed bump that is being previewed for the InfiniBand interconnect commonly used for HPC and AI or it is actually shipping in systems. In this case, it is the former rather than the latter, but the time between the preview of 400 Gb/sec InfiniBand from Nvidia and the delivery of this technology is a bit shorter than usual with shipments of new switches and adapters expected in the second quarter of 2021.
The IT world might have been a better placed had all of the vendors who originally backed the InfiniBand to create this new interconnect switch fabric actually done through with it as they promised back in the late 1990s. We would have already had a low latency, high bandwidth switched fabric between all computers and indeed all elements of computers, and it would have been ubiquitous enough and therefore cheap enough that the disaggregated and composable future that we are now struggling to build might have already come to pass.
Instead of that, what we got was a great interconnect for those who really need something better than Ethernet can deliver, something unique that does not have to support every little protocol everyone ever thought of and sticks to its high performance knitting and shows Ethernet ASIC designers the future they will have to try to get to. Anything that InfiniBand does – Remote Direct Memory Access is perhaps the most important feature – Ethernet eventually has to graft onto itself. But it is always playing catchup.
A decade ago, with its Switch-X chips, Mellanox Technologies, which has been the standard bearer for InfiniBand for a long time and which is now part of Nvidia, actually tried to converge Ethernet and InfiniBand onto the same switch ASIC with its aptly named Switch-X chip. The side effect of this convergence, however, is that port to port hop latencies, and therefore latencies throughout a network comprised of layers of Switch-X devices, went up and this was not precisely palatable to the HPC customers that were used to not only low latencies but lowering latencies. This left the door open a little for QLogic’s TrueScale InfiniBand switching business, and it is not a coincidence that Intel bought this business shortly after that and that Mellanox re-forked its switch ASICs, creating the Spectrum Ethernet ASICs aimed at hyperscale and public cloud networking and the Switch-IB and Quantum ASICs supporting just InfiniBand and aimed at HPC and AI workloads.
At the SC20 supercomputing conference this week, Nvidia previewed its forthcoming NDR InfiniBand, with NDR being short for Next Data Rate, the kicker to the current 200 Gb/sec HDR InfiniBand sold under the Quantum brand, and running at 400 Gb/sec per port. This is a preview several quarters before shipments, as is often done with InfiniBand technology leaps. This happened with 100 Gb/sec EDR InfiniBand, which previewed at SC14 in the fall of 2014 and started shipping in systems in early 2015, based on the Switch-IB ASIC. A kicker Switch-IB 2 chip with more on-chip HPC and AI code acceleration was revealed a year later at SC15, also running at 100 Gb/sec per port. At SC16 four years ago – yes, that was four years ago – Mellanox unveiled its Quantum ASICs and the jump to 200 Gb/sec per port, what is called HDR InfiniBand. It took about a year, until the fall of 2017, for these switches to be deployed in the field, which is about the same time as it takes from the launch of a merchant Ethernet ASIC and its deployment in hyperscaler and cloud builder datacenters. We no longer have the same visibility into the sales of InfiniBand at various speeds, as Mellanox provided in its quarterly financials, but the expectation was for a very fast ramp to HDR InfiniBand, much faster than the move to EDR InfiniBand, which obviously had some benefits over the 100 Gb/sec offered by the Switch-IB and Switch-IB 2 ASICs but increased port speed was not one of them.
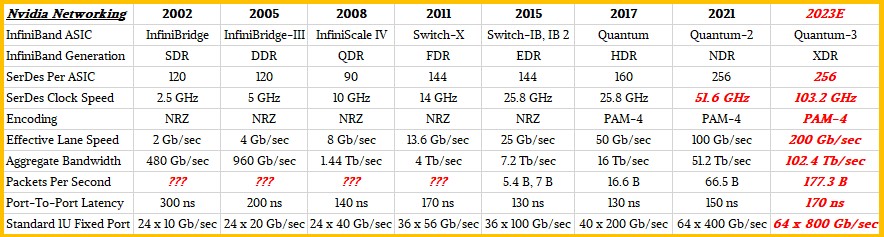
In the chart above, we added in the clock speed for the underlying SerDes on each switch ASIC. The point is, there is an underlying clock speed, which we don’t often talk about but there is a consensus out there that for conventional switch ASICs as we know them, something a little north of 100 GHz is a barrier. We have gotten more clever with the data encoding on switch ASICs, which helps. The early InfiniBand could use 8 bits for every 10 bits it sent — so called 8b/10b encoding — but with FDR InfiniBand and later the more efficient 64b/66b encoding could deliver 64 bits for every 66 bits sent. If you work encoding backwards from the lane throughput, you can calculate the clock frequency of the SerDes, which we have done. We have estimated that Quantum-2 NDR InfiniBand will use the same 64b/66b encoding, but it may not, and with Quantum-3 XDR InfiniBand, we are estimating that Nvidia can crank the SerDes clock up to just north of 100 GHz, stick with PAM-4 encoding, and get the bandwidth up to 800 Gb/sec across four lanes. There are, we admit, several other ways to get there.
The point is, doing something clever, like adding PAM-4, means we did not have to crank the SerDes clocks — and that is a very good thing. We only have so much GHz left in this ASIC game as it currently is structured.
You might have been expecting 200 Gb/sec Quantum-2 switching already. But frankly, the competition with Intel’s variant of InfiniBand, which was called Omni-Path and which has been spun off into a new company called Cornelis Networks founded by a bunch of people from QLogic and Intel, was not intense in 2018 and 2019 and that has allowed Nvidia’s networking division to make the Mellanox acquisition and integrate all of its technologies into the fold. And Cray’s Slingshot Ethernet, which runs at 200 Gb/sec, is still not deployed in the field anywhere yet, either. So everybody was taking a Moore’s Law breather before the coronavirus pandemic kicked in and slowed all kinds of things down.
Hence, with the Mellanox acquisition still not done at SC19 last year, we did not see a preview of 400 Gb/sec NDR InfiniBand, which we are calling Quantum-2 but for which Nvidia has not yet announced a brand. But the $6.9 billion Mellanox acquisition closed in April, and we talked to Nvidia co-founder and chief executive officer Jensen Huang in detail about his datacenter aspirations at the time, and now is the best time to preview the Quantum-2 ASIC and provide some insight into the coming networking advances as relates to HPC and AI workloads.
Switch ASIC vendors do not like to give out a lot of details about their devices, but Gilad Shainer, senior vice president of marketing for HPC and AI networking at Nvidia, gave us some details about the forthcoming Quantum-2 ASICs and the switches that the company will be building based on them. We think that the development of the Spectrum-3 Ethernet ASICs and the Quantum-2 InfiniBand ASICs were done in tandem, with many technologies, such as SerDes communication circuits, borrows across the devices. Mellanox had launched the Spectrum-3 Ethernet ASICs in March of this year, with 400 Gb/sec per port, and it has 256 SerDes running at 50 GHz native delivering 50 Gb/sec per lane, and on top of this is layered PAM-4 pulsed amplitude modulation encoding that allows each signal on each lane to carry two bits instead of just one using plain vanilla non-return-to-zero (NRZ) encoding that has been used for decades for network transports. And there will be no surprises that Shainer confirmed to The Next Platform that the future Quantum-2 InfiniBand ASIC has 256 SerDes crammed on it running at 50 GHz and sporting PAM-4 encoding to double up the effective bandwidth per lane to 100 Gb/sec.

To get 64 ports running at 400 Gb/sec, four lanes coming off the SerDes are ganged up together; this is in fact what Nvidia plans to do to create a 1U fixed port switch. There is also the capability of carving up the aggregate bandwidth of the Quantum-2 ASIC, which at 51.2 Tb/sec is 3.2X higher than with the first-generation Quantum ASIC with its 16 Tb/sec of aggregate bandwidth, to create a fixed port switch that has 128 ports running at 200 Gb/sec. Depending on the heat dissipated by the optics, this switch configuration might have to be 2U high. While there should be a way to further use that bandwidth to increase the radix of the switch, Nvidia is not supporting a further halving of bandwidth to allow 256 ports running at 100 Gb/sec – something it absolutely does with its Spectrum-3. It is also interesting that each SerDes in the Spectrum-3 chip can be run independently so a switch can run a mix of ports at a mix of speeds; it does not look like this capability is in the Quantum-2 ASIC, although it might be latent in the design. It is possible that with cable splitters outside of the switch a fixed port switch with 128 ports running at 200 Gb/sec could be converted to an effective 256 ports running at 100 Gb/sec.
The rule of thumb in networking, and something that the Ethernet and InfiniBand managers at Nvidia and indeed all switch ASIC makers always remind us of, is that you always, always, always move to the latest generation of switches because the cost per bit moved has always gone down. And until we get to 4 nanometer or so chip etching technologies, the Moore’s Law increases in transistor density will probably keep the cost per bit moved dropping, and chiplet designs will probably help keep it pushing for a few years beyond that. This is as true for Quantum-2 NDR InfiniBand as it was true for InfiniBridge ASICs from two decades ago that gave Mellanox its start with SDR and DDR InfiniBand.
Pricing has not been set as yet, but Shainer says that customers should expect for a Quantum-2 NDR InfiniBand switch port to cost somewhere around 1.4X to 1.5X at its native 400 Gb/sec speed compared to a Quantum HDR port running at 200 Gb/sec. If you use the radix of the switch to run ports at 200 Gb/sec – and thereby flatten the network so it doesn’t need as many switch layers and therefore physical switches to interconnect a certain amount of nodes – the cost of the switch port drops and the number of switches drop, and this can radically cut the cost of interconnect for a distributed system. The fact that the HDR switches had only 40 ports running at 200 Gb/sec while the NDR switches have 128 ports means the radix can go up by a factor of 3.2X, and the cost per port will come down by 40 percent. How much the overall cost of the network drops depends on the scenario, of course. But if you can eliminate another 30 percent of switches thanks to the increased radix, and the cost per port is inherently lower, moving from 100 Gb/sec to 200 Gb/sec just got a whole lot cheaper. And, when customers are ready to move up to 400 Gb/sec they have switches that can do it if they use cable splitters instead of hard coded fixed port switches.
Adding to this is the case that moving to the more recent switches, even if they don’t run at full bandwidth per port, saves energy and rack space as well. And finally, Mellanox has figured out how to do this all with copper cabling, which is a lot less expensive than optical cables. The 400 Gb/sec copper cables can be 1.5 meters long, just a little bit shorter than the 2 meter copper cables that were available with 200 Gb/sec InfiniBand switches. Presumably, when we get to 800 Gb/sec InfiniBand at some point in the future, the copper cables will shrink again, perhaps to a mere 1 meter in length and pushing the limits of what can be done in a rack. For those who need to length than this, there are active copper cables (which amplify signals) and then of course also optical fiber cables. In the HPC space, most customers only need to do a maximum of 30 meters across their systems, sometimes topping out at 50 meters. Hyperscale customers tend to need 100 meters and sometimes maybe as much as 150 meters for their podded distributed systems.
With the Quantum-2 ASICs, Nvidia is supporting the usual topologies, including traditional fat tree but also supports Dragonfly+, SlimFly, and 6D torus topologies, and in this case the topologies have been radically extended to support wider networks in part because of the adoption of InfiniBand by the hyperscalers and cloud builders for the HPC and AI clusters, which are much, much larger than even the largest supercomputers in the world. (Sad, but true.) Running at 400 Gb/sec, Quantum-2 ASICs in a four-tier network will be able to support more than 1 million nodes in a Dragonfly+ topology, and at 200 Gb/sec, that doubles up to more than 2 million nodes.
This may not seem like a lot until you realize that each GPU in a hybrid CPU-GPU machine running AI training workloads tends to get its own InfiniBand network interface card so GPUDirect memory addressing and Magnum I/O addressing can be attached to each GPU so data can be shared GPUs located across nodes. (PCI-Express switching or NVLink switching is used for data sharing within nodes.) And given that the processing capacity of the Nvidia GPUs keeps going up fast, we will not be surprised to see machines that have eight 400 Gb/sec ConnectX-7 NICs – if that is what they indeed will be called when they ship in the second quarter of 2021 along with the Quantum-2 switches – to keep feeding those “Ampere” A100 GPU accelerator beasts.
There are, of course, other kinds of acceleration that matters at least as much, and perhaps more, than more bandwidth and lower latency. (The days of lower latency are pretty much gone, in fact, and we expect for latencies to keep creeping up as bandwidth increases and encoding gets fuzzier to drive up that bandwidth.) Over the past many generations of Mellanox InfiniBand adapter and switch ASICs, acceleration for different kinds of MPI, SHMEM, and PGAS operations have been added to these devices and offloaded from the CPUs in cluster nodes. As an example, the current Quantum ASICs handle all-to-all reductions, which reduces the latency from 30 microseconds to 40 microseconds when they are done on the CPUs to somewhere between 4 microseconds to 5 microseconds, or somewhere between 6X and 10X lower, averaging around 7X according to Shainer. With the Quantum-2 ASICs, all-to-all collective operations can be offloaded to the ASIC.
“The new NDR offload engine will be able to do all-to-all operations, and this is one of the most complex operations in MPI and deep learning,” says Shainer. “Right now we are seeing somewhere between 4X and 5X, but we will probably be conservative and just say 4X.”
MPI all gather operations, which are not yet supported with either Quantum or Quantum-2, will have switch acceleration in the next generation of InfiniBand chips, called XDR on the roadmap and probably Quantum-3 by Nvidia.
One last thing. Nvidia will be making massive director switches based on Quantum-2 ASICs, according to Shainer. The full director switch, which has yet to be named, will have 2,048 ports running at 400 Gb/sec or 4,096 ports running at 200 Gb/sec with an aggregate switching bandwidth of 1.6 Pb/sec across the enclosure. Nvidia will also sell a variant of the device with half the number of ports and half the aggregate bandwidth, so 1,024 ports at 400 Gb/sec and 2,048 ports at 200 Gb/sec, with 800 Tb/sec of bandwidth across all the ports.


Sizing Up AWS “Blackwell” GPU Systems Against Prior GPUs And Trainiums
This week, Amazon Web Services announced the availability of its first UltraServer pre-configured supercomputers based on Nvidia’s “Grace” CG100 CPUs and its “Blackwell” B200 GPUs in what is called a GB200 NVL72 shared GPU memory configuration. These machines are known as the U-P6e instances, and come in full rack and …
Nvidia Says “Blackwell” GPU Issues Are Fixed, Ramp Starts In Fiscal Q4
Welcome to the most important earnings call in history, with the weight of the aggregate stock markets of the entire world hanging on what Nvidia says and doesn’t say. Well, the most important one until thirteen weeks from now. And get used to that cadence until this GenAI boom either …

Who Will Build Europe’s First Exascale Supercomputer – And With What, And Why?
Exascale supercomputing is just as important to Europe as it is to the United States and China, but each of these geopolitical regions on Earth has its own way of developing architectures, funding their development and production, and figuring out where the best HPC centers are to host such machines …
Be the first to comment