

This week is the eighth annual International Workshop on OpenCL, SYCL, Vulkan, and SPIR-V, and the event is available online for the very first time in its history thanks to the coronavirus pandemic.
One of the event organizers, and the conference chair, is Simon McIntosh-Smith, who is a professor of high performance computing at Bristol University in Great Britain and also the head of its Microelectronics Group. Among other things, McIntosh-Smith was a microprocessor architect at STMicroeletronics, where he designed SIMD units for the dual-core, superscalar Chameleon and SH5 set-top box ASICs back in the late 1990s. McIntosh-Smith moved to Pixelfusion in 1999, which created the first general purpose GPU – arguably eight or nine years before Nvidia did it with its Tesla GPUs, where he was an architect on the 1,536-core chip and software manager for two years. In 2002, McIntosh-Smith was one of the co-founders of ClearSpeed, which created floating point math accelerators used in HPC systems before GPU accelerators came along, and was first director of architecture and applications and then vice president of applications. ClearSpeed sold its accelerators from 2005 through 2008 very aggressively, which had 64 cores in the CS301 prototype, 96 cores in the CSX600, and 192 cores in the CSX700. But GPU accelerators started sucking all of the oxygen out of the HPC sector starting in 2006, and really got rolling in 2012 with AI workloads. Although we would point out that matrix math units that are not based on GPU architectures are popping up like mushrooms for AI workloads.
The point is, McIntosh-Smith knows his stuff when it comes to HPC and AI, and since 2006, which was a year when accelerators in HPC started to get initial traction and also when Amazon launched its cloud, he has been combing through the research papers posted on Google Scholar and counting the number of papers mentioning various parallel programming environments to gauge their relative strength in the HPC research and, to a certain extent, AI research being done out there in academia, government, and industry. Consider it a leading indicator of sorts for where more production environments are likely to be heading. Take a look:
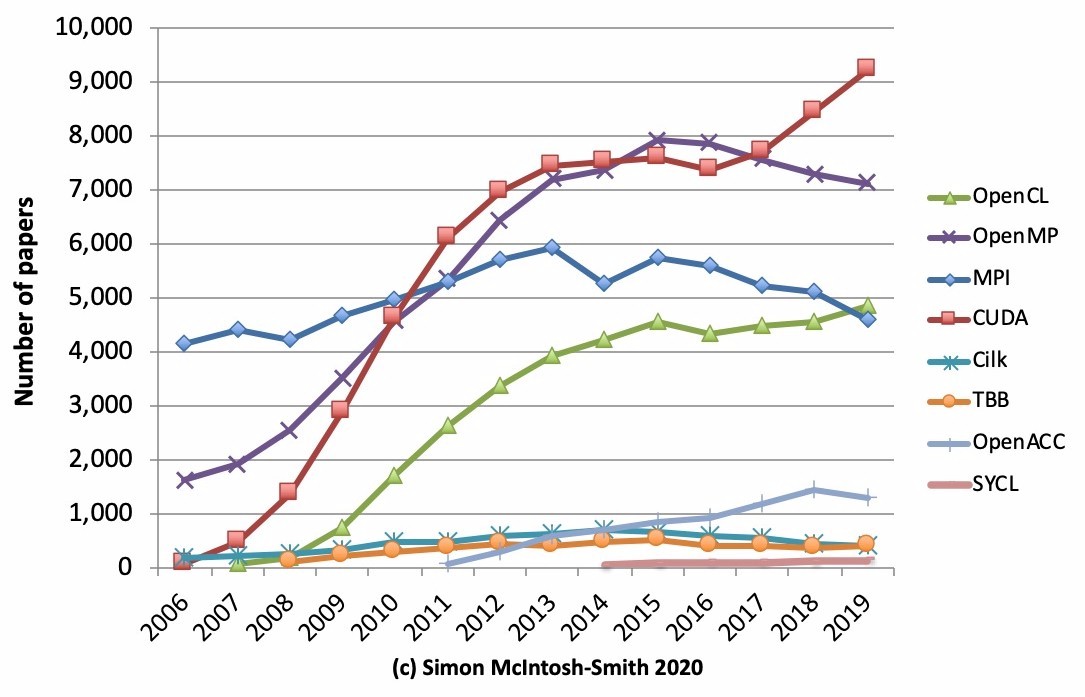
This is a very interesting chart, and the important thing is that not all of these parallel programming approaches are mutually exclusive. Message Passing Interface, or MPI, is often layered on top of or embedded within OpenMP or OpenACC tools commonly used in extreme scale HPC applications, for instance. Ditto for CUDA, the parallel programming environment that Nvidia created for its Tesla GPU accelerators, which is often used in conjunction with or side-by-side on machines that support OpenMP or OpenACC.
Cilk is a parallel version of C and C++ that dates back to work done at the Massachusetts Institute of Technology back in 1994 and was used on the CM5 supercomputer from Thinking Machines. It was eventually commercialized by Cilk Arts and then acquired by Intel in 2009 and releases as part of its C++ Composer XE compiler.
For those of you who are dyslexic, Cilk is not to be confused with SYCL, which is a cross-platform, parallel abstraction layer for C++ that rides on OpenCL; it was created in 2014 and that is supported commercially by Khronos Group. It bears some similarities to Nvidia’s CUDA parallel programming environment. SYCL is, in effect, a domain specific implementation of C++ that runs on the OpenCL API, and there is a variant called hipSYCL that lets it ride on CUDA. And SYCL, you will remember, is the plumbing that Intel has chosen for its OneAPI cross-platform parallel computing programming effort, which was announced last year and which marries data parallel C++ and SYCL to span all kinds of compute engines with parallel components. Meaning, everything we can think of, but we suspect initially only for Intel CPUs, GPUs, NNPs, and FPGAs. (Codeplay has apparently created a oneAPI stack shim using SYCL and data parallel C++ so it can run atop CUDA and drop code onto Nvidia GPU accelerators.)
TBB is short for Thread Building Blocks, which was created out of ideas coming from OpenMP and Cilk as well as STL and STAPL, which didn’t make the chart above so they are probably not important anymore. TBB was created in 2004 and launched in 2006 and has kept a fairly low level of activity – but a consistent level of interest nonetheless – since then. Presumably TBB will be superseded by SYCL and parallel C++ for C++ applications, but then again, if you are coding in Fortran, Intel has said absolutely nothing to us thus far about how oneAPI is going to integrate with Fortran.
But, as one intrepid reader has pointed out, there are articles like Get Started Using the OpenMP Offload to GPU Feature of the Intel C++ Compiler and the Intel Fortran Compiler (Beta), which was pushed out on April 19 with no fanfare and which shows that Fortran with OpenMP offload is going to work in the OneAPI environment. That said, the oneAPI spec is a little thin when it comes to talking about Fortran integration, as you can see here. And, as this very smart reader also points out, Intel knows that Fortran matters a lot in HPC and therefore it must be well supported. And that means it needs good math libraries and so on, and there’s no way you want to do one set of those for Data Parallel C++ and another for Fortran and OpenMP offload. So interoperability between Fortran and OneAPI libraries is absolutely required.
OpenCL, notes McIntosh-Smith in his presentation, which you can watch here, and there are nearly 5,000 articles citing OpenCL in 2019, up 6 percent from the research paper count in 2018. CUDA had a big run in HPC from 2008 through 2011, and then continued growth as machine learning took off on GPUs in 2012, and after a slight dip, the paper count for research involving CUDA is growing at 9 percent per year in 2018 and 2019. MPI and OpenMP are seeing dips, but the growth in OpenACC sort of fills in the gap in the dip with OpenMP, so that seems to us just like a new choice taking some share. The decline in MPI is very likely the result of other ways that are being deployed to gang up processing and memory across distributed systems.
There is a big gap between these parallel environments and Cilk, TBB, and SYCL, and SYCL is, as McIntosh-Smith points out, is the relative newcomer on the block. “It will be interesting to see how SYCL does now that Intel has adopted it as part of its OneAPI, and I expect to see quite an uptick in SYCL citations over the next few years,” he says.


Can SYCL Slice into Broader Supercomputing?
There are a few unignorable trends in high performance computing, especially in the exascale age. First, heterogenous and differing architectures at the major HPC sites are diverging with some using AMD CPUs and GPUs, others Nvidia, and of course, still others sticking with the well-tread Intel path. Second, codes are …
Building A Hassle-Free Way To Port CUDA Code To AMD GPUs
Emulation is not just the sincerest form of flattery. It is also how you jump start the adoption of a new compute engine or move an entire software stack from one platform to another with a different architecture. Emulation always involves some form of performance hit, but if you are …

OpenACC Cozies Up To C, C++, and Fortran Standards
Not so long ago, there was a question whether exascale supercomputers would be built from a very large number of thin nodes containing only modest amounts of parallelism or a smaller number of fat nodes powered by specialized accelerators and powerful manycore processors. As PGI’s Michael Wolfe pointed out, the …
Be the first to comment