

A collaboration including the University of Oxford, University of British Columbia, Intel, New York University, CERN, and the National Energy Research Scientific Computing Center is working to make it practical to incorporate of Bayesian inference into scientific simulators. The project is called Etalumis, which is the word “simulate” spelled backwards, and it is a reference to the fact that Etalumis essentially inverts a simulator by probabilistically inferring all choices in the simulator given the output of the HPC model.
One outcome, says Wahid Bhimji, big data architect at NERSC, “is that Etalumis lets scientists discover new processes with a greater understanding of the true uncertainties and how to interpret those discoveries in their model of the world.”
Reverse Engineering At A Massive Scale
The Etalumis paper was presented at the SC19 supercomputer conference in Denver, and is currently available on arxiv.org. The important idea in the project is that Etalumis flips that traditional view of HPC modeling and simulation.
Think of all those HPC simulators that people have been using for decades. These can be considered as software that implicitly define probabilistic generative models, or forward models, that go from choices x to outcomes y. Scientists have worked very hard to create simulators that accurately generate outcomes that correlate strongly with real-world observations. Stated simply, Etalumis uses statistical, specifically Bayesian inference (and remarkably backtraces from the simulation executable itself) to, in a somewhat imprecise sense, reverse engineer the choices made in the simulation that generated the outcome. As a result, scientists get a behind-the-scenes view of the behavior (that is, choices) that resulted in the observations.
Atilim Gunes Baydin, postdoctoral researcher in machine learning at the University of Oxford, believes, “This means that the simulator is no longer used as a black box to generate synthetic training data, but as an interpretable probabilistic generative model specified by the simulator’s code, in which we can perform inference.”
So, think of that really complex HPC simulator as a probabilistic generator, which is an admittedly unconventional but valid view. Etalumis gives scientists the ability via something called a probabilistic programming language to study the choices x that went into producing each outcome y. Along with increased understanding that can be gained from studying those choices, comes the opportunity, as Wahid pointed out, to potentially refine those choices to more accurately predict outcomes.
While this is not a mathematical article, it is appropriate to say that the HPC simulator acts as a generator that produces samples from the joint prior distribution p(y, x) = p(y|x)p(x) in each execution. Thus the simulator is a forward model going from choices x to outcomes y. Etalumis runs that same program using a variety of general-purpose inference engines available in the probabilistic programming system to obtain p(x|y), the inverse going from observations y to choices x.
The process is relatively straight-forward can be seen in the figure below, although the math might be obscure to those who have not studied Bayesian inference:
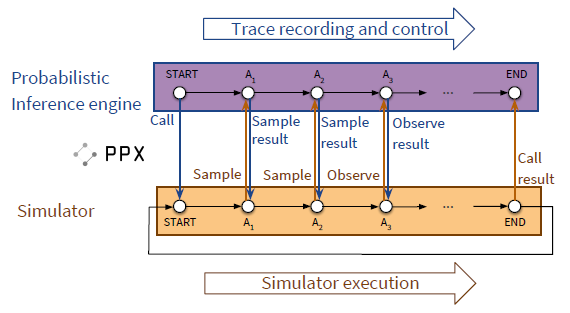
Now we can understand in layman terms why the Etalumis authors claim that Etalumis “enables, for the first time, the use of existing stochastic simulator code as a probabilistic program in which one can do fast, repeated (amortized) Bayesian inference; inferring the interpretable latent state of a simulator given its output.”
Making Etalumis Concrete
Particle physicists have spent considerable effort creating the Sherpa (Simulation of High-Energy Reactions of Particles) Monte Carlo event generator. Sherpa is a class of general-purpose generators designed to handle many (ideally all) different physical process types, and be able to take care of all aspects of the event simulation. Sherpa is part of a class of simulators that are the main workhorses for particle physics simulations.
The Question To Be Answered
To prove the value of Etalumis, the team poised this question: “Given an actual particle detector observation y, what sequence of choices x are likely to have led to this observation?” The team then endeavored to answer this question using the Sherpa simulator. This is a scientifically interesting problem as Sherpa is one system under active investigation by physicists at the Large Hadron Collider at CERN and important to uncovering properties of the Higgs boson.
Computing the evidence to answer this question requires summing over all possible paths that the simulation can take. The team notes that this is impossible to compute in polynomial time so sampling-based inference engines are used. They note, “This specifically is where probabilistic programming meets, for the first time . . . high-performance computing.”
A large number of inference engines are available ranging from MCMC-based lightweight Metropolis Hastings (LMH) and random-walk Metropolis Hastings (RMH) algorithms to importance sampling (IS) and sequential Monte Carlo. It is also possible to use deep-learning-based proposals trained with data sampled from the probabilistic program, which is also referred to as the inference compilation (IC) algorithm.
Controlling The Simulator And Collecting The Data
To collect the data, the team created a probabilistic programming execution protocol (PPX), which defines a cross-platform API for the execution and control stochastic simulators as shown previously in Figure 1. The team then connected the Sherpa simulator to this protocol by redirecting the random number requests in the simulator to sample random numbers from this API.
Essentially the PPX means that (1) execution traces of the stochastic simulator can be recorded, and (2) Etalumis can control the execution of the simulator at points of random number draws by providing random numbers from proposal distributions.
The details are manyfold, but succinctly the PPX protocol provides language-agnostic definitions of common probability distributions. Essentially, this provides a form of instrumentation covering the call and return values of: (1) program entry points; (2) sample statements for random number draws, and (3) observe statements for conditioning.
Thus, using the Etalumis PPX protocol as the interface, the team implemented two main components: (1) pyprob, a PyTorch-based PPL in Python and (2) a C++ binding to the protocol to route the random number draws in Sherpa to the PPL and therefore allowing probabilistic inference in this simulator.
Using Deep Learning
The team implemented an Inference Compilation (IC) approach (using deep learning in this application) which required running the Sherpa simulator a large number of times to generate the execution traces used to train a recurrent neural network (RNN). Yes, Sherpa stack traces were used in training. To improve performance, stack traces were obtained with the backtrace function where the Sherpa symbolic function name was found with the dladdr() function.
The overall simulation and inference flow is shown below:

Training Performance And Scaling
Performance was measured on three NERSC systems: Cori, Edison, and the Diamond cluster. Offline training was used to facilitate reproducible experiments. The runs produced a sample of 15 million traces that occupied 1.7 TB on disk. Generation of this 15 million trace dataset was completed in 3 hours on 32 nodes of the Edison system, which is based on 12-core “Ivy Bridge” Xeon E5-2695 v2 processors and which is a Cray CX30 system that has a total of 5,586 nodes.
Weak scaling behavior for training the RNN with distributed PyTorch training is shown below for training on both Cori and Edison. Please consult the paper for a detailed description of the weak scaling evaluation.

Performance Compared To RMH Inference
Etalumis is novel in treating the existing Sherpa simulator as a very large scale probabilistic model, and there is no direct baseline for comparison in the literature. Thus the team used their own implementation of an MCMC (RMH)-based approach for validation.
However, MCMC methods such as RMH are computationally expensive. In contrast, once the RNN for IC inference is trained to convergence, the deep-learning based IC method became competitive in performance at a fraction of the RMH computational cost. Further, inference with the RNN is embarrassingly parallel, as many instances of the trained RNN can run distributed on a given observation at the same time.
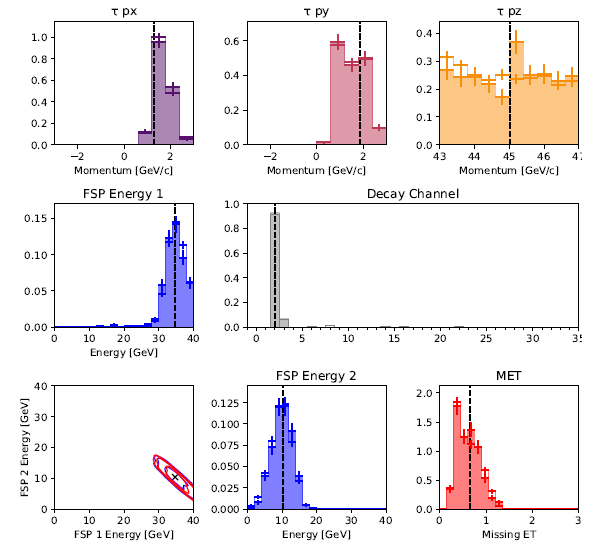
For this work, the RMH approach ran for 115 hours on an Edison node to produce the 7.68 million trace result shown in the figure below. The corresponding 6 million trace IC result completed in 30 minutes.
As can be seen, despite this considerable difference in compute time, the agreement between the IC and MCMC methods is quite good.
Summary
The Etalumis framework can potentially be applied to a variety of HPC simulations used to model real-world systems, including epidemiology modeling such as disease transmission and prevention models, autonomous vehicle and reinforcement learning environments, cosmology, climate science, and more. As noted, the ability to study the choices that resulted in an observation improves our understanding, and potentially may lead to better predictions in these, and other, important scientific and engineering domains.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. Farber can be reached at info@techenablement.com.


Python Delivers Big On Complex Unlabeled Data
A collaboration of researchers from the University of California Davis, the National Energy Research Scientific Computing Center, and Intel are working together on the DisCo project to extract insight from complex unlabeled data. DisCo is short for the Discovery of Coherent Structures, and it discovers the inherent structures in unlabeled …
The Stepping Stones In America To Exascale And Beyond
To a certain extent, all of the major HPC centers in the world live in the future. Before a teraflops, petaflops, or exaflops supercomputer is even operational, a new team at the center is hard at work defining what the workloads five years from now might look like so they …
Berkeley Lab First In Line for Cray “Shasta” Supercomputers
For the past five years, supercomputer maker Cray has been diligently at work not only creating a new system architecture that allows for a mix of different interconnects and compute for its future “Shasta” systems, but has also brought long-time Cray chief technology officer, Steve Scott, back into the company …
Be the first to comment