
To a certain extent, all of the major HPC centers in the world live in the future. Before a teraflops, petaflops, or exaflops supercomputer is even operational, a new team at the center is hard at work defining what the workloads five years from now might look like so they can try to bend hard and soft wares to their will to meet those needs.
If you think about it too long, it goes from exciting to exhausting. So don’t linger.
Glenn Lockwood, formerly the storage guru at Lawrence Berkeley National Laboratory and now an HPC guru at Microsoft Azure, posted this tidy little chart on Xitter outlining the expected operational status of the three big supercomputers in the Advanced Scientific Computing Research office of the US Department of Energy, and it got us to thinking. The DOE, of course, funds the pre-exascale and exascale systems that get installed for scientific and now AI use and has for several decades. (It used to be that the US Defense Advanced Research Projects Agency did a lot of funding for supercomputers, and then it realized that it needed a teraflops battlefield computer more than it needed an exaflops system sitting in a bunker underneath Cheyenne Mountain.)
Here’s the chart, which outlines the three current big ASCR systems and their follow-ons:
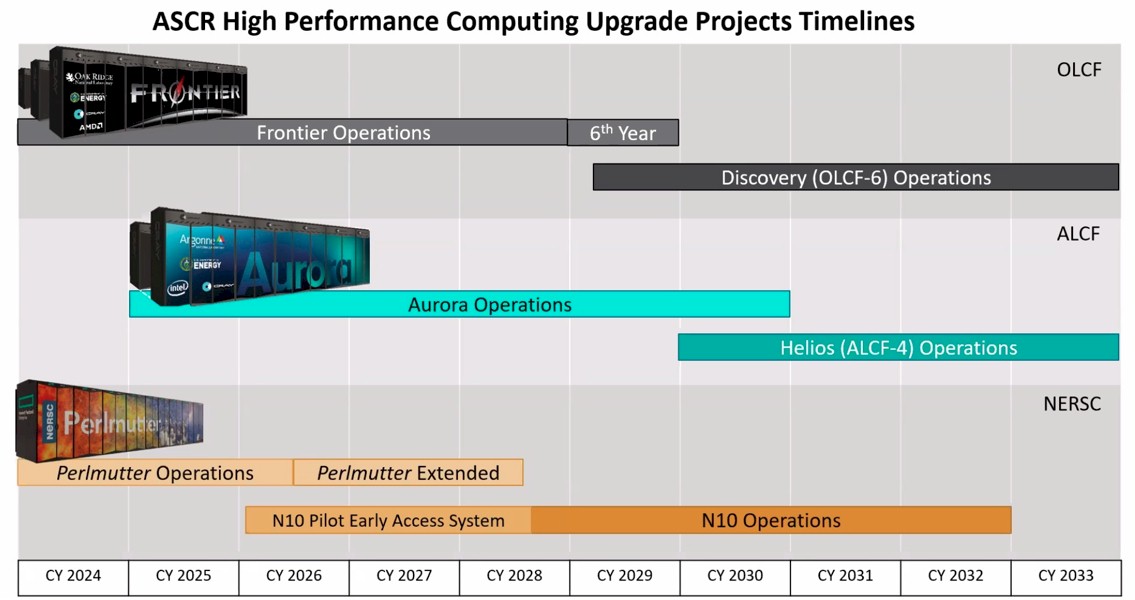
This is the first time that we have seen anything publicly about the kicker to the “Aurora” supercomputer at Argonne National Laboratory, which is apparently code-named “Helios” and which will be operational in early 2030.
This chart came from the Advanced Scientific Computing Advisory Committee meeting, which was held just as Hurricane Helene was barreling down on us, and we are finally getting around to talking about this now that we have power and Internet restored down here in the Appalachian Mountains of western North Carolina. (We are fine. The house took some hits on the port side, but it can be fixed; many out here in the mountains have fared far, far worse and are woefully in need of assistance.)
You will note as well that the kicker to the “Perlmutter” system at Lawrence Berkeley, the so-called NERSC-10 machine, which was supposed to be installed in 2024 if you look at old roadmaps and then was pushed out to 2026 as we wrote about back in April 2023 when the bidding was opened up for the machine. Now it looks like NERSC-10 is going to be operational in the second half of 2028, which probably means it won’t be installed until late 2027. The NERSC-10 pilot system is going to be installed in early 2026 according to this roadmap.
This companion roadmap chart for Lawrence Livermore National Laboratory, Sandia National Laboratories, and Los Alamos National Laboratory, which we dug out of another presentation from the meeting, gives an update on the capability and commodity clusters across the Tri-Labs:
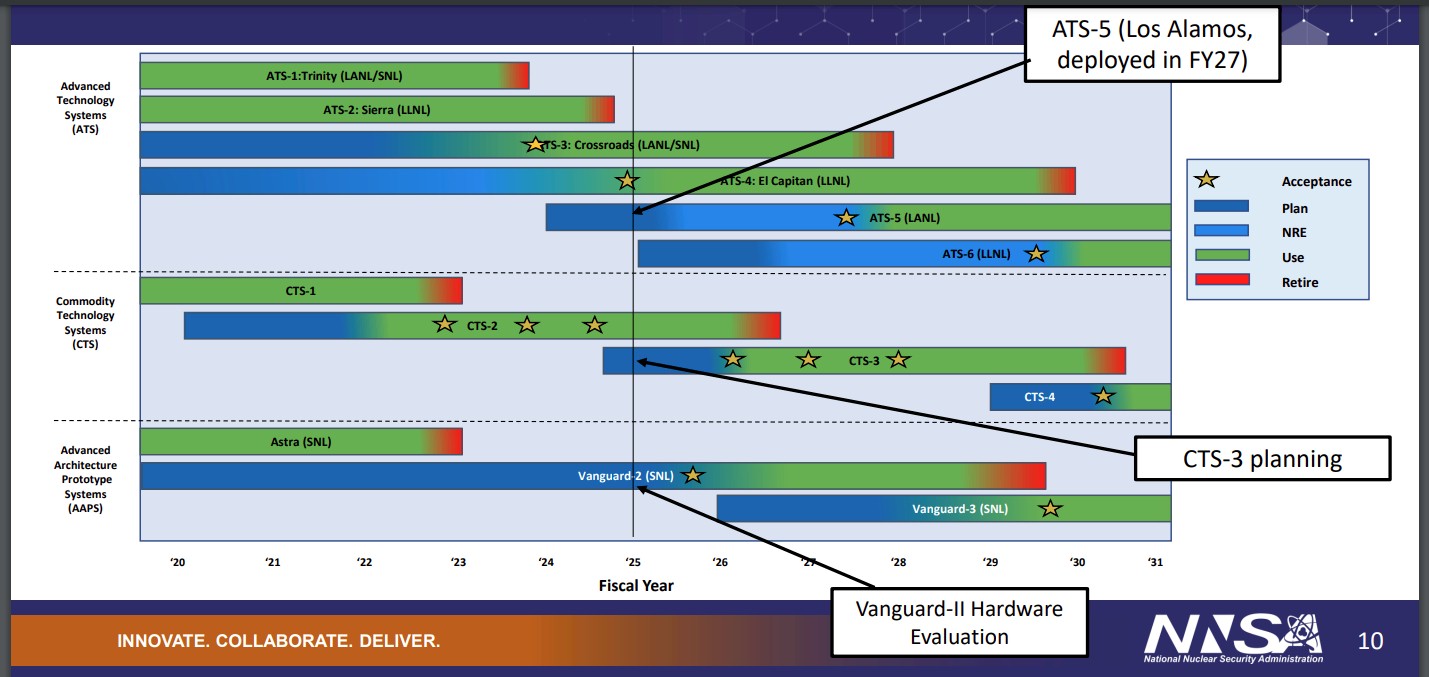
This roadmap shows fiscal US government years, which begin on October 1 each year. So right now it is fiscal 2025, which is why that vertical line is drawn across the roadmap. This is where we are at right now. Right now the planning for the ATS-5 kicker to the “Crossroads” machine shared by Los Alanos and Sandia is being planned and engineering work is starting on the system, which will be deployed in fiscal 2027 (which probably means sometime in calendar 2028). The CTS-3 commodity cluster is in the planning phase and the hardware for the “Vanguard-II” system at Sandia is in evaluation and will be accepted before the end of this fiscal 2025 year. The chart also shows that the “El Capitan” machine, which we think could weigh in at 2.3 exaflops of peak performance, has just been accepted.
We feel the need to say something here. When the DOE talks about forward progress, it steps down across its roadmap as each new machine comes out. But when most of us think of progress, it is always up and to the right. We find this distinction peculiar, and it has been bothering us for a while but we just remembered to point this out. (Sometimes, little things send subliminal messages.) By the way, when Oak Ridge does its roadmaps and LBNL does its roadmaps, they are up and to the right. This is not a big thing, but it is odd.
We think roadmaps should not just express time, but also performance or some other salient characteristic. And to get our brains wrapped around the topic of conversation at major HPC centers and across the hyperscalers and cloud builders – that operational times of massive machines are being stretched to make them more profitable – we decided to make a few roadmaps of our own. And to that end, we have plotted the machines at Oak Ridge, Argonne, NERSC, and LLNL over time from 2005 out through 2033, with their time in the field (which includes shakedown and operations) for each machine shown. We are only showing the big systems at each site, the capability-class machines at any given time.
We will start with Oak Ridge because it shows something we do not see a lot of these days: Upgrades.
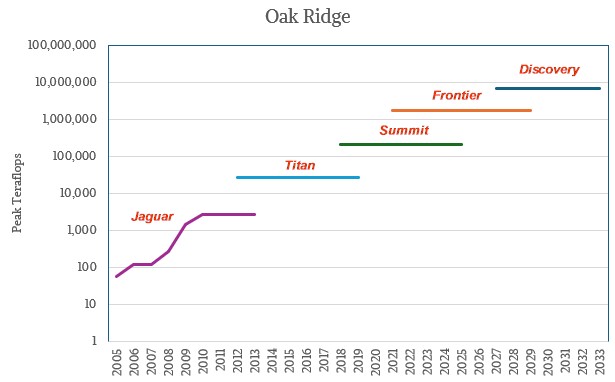
At the lower left of the chart above is the “Jaguar” system, which was upgraded several times over its life. And once again we will ask: Why aren’t exascale-class machines upgraded? Rather than thinking about keeping a machine in service for six years now instead of four or five, why not design it to be upgraded gradually and piecemeal from the beginning? Yes, you pay more electricity over the longer haul, but shouldn’t the hardware also get cheaper over time?
In the chart, those are log scales vertically for peak theoretical performance in teraflops at FP64 precision as given by the Top 500 supercomputer rankings. And the time on the horizontal axis is the years that the machine was installed, both for shakedown and operations. The “Discovery” follow-on to the current “Frontier” machine at Oak Ridge does not have a precise metric for performance, but the note attached to the technical requirements says that Oak Ridge anticipates that it will be somewhere between 3X and 5X faster on a suite of applications than the current Frontier machine. We took the midpoint of 4X and that gives you a peak FP64 throughout of around 6.9 exaflops for Discovery.
Our guess is that Discovery, whatever it is, will be in the field for seven years and operational for six of those years, with operations starting in early 2028 if all goes to plan.
What is also obvious in this chart is that the 10X performance jump that Oak Ridge enjoyed between Jaguar and “Titan” in 2012 started to fade a little with the 7.4X jump to “Summit” in 2018, recovered a little better with the 8.5X jump to Frontier, and now we are talking only a 3X to 5X jump to Discovery. There are power, cooling, and budgetary pressures that make a 10X jump impractical, or essentially impossible.
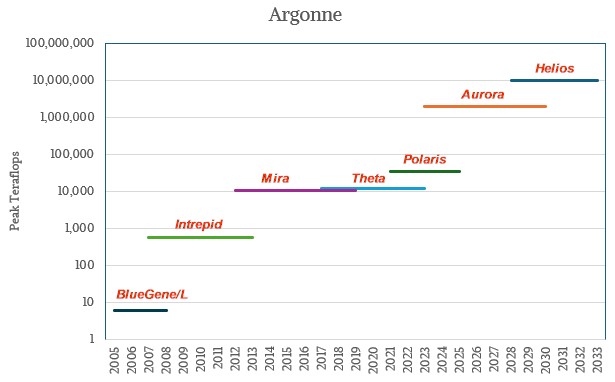
Argonne made some big jumps in the decade between 2005 and 2015 with IBM’s BlueGene/L and BlueGene/P massively parallel PowerPC machines, and the gap between “Mira” and “Theta” in the following decade and the “Aurora” machine installed last year was quite large, at 196.7X and 169.8X, respectively. But that is really because Aurora was five years late and came in with 11X more oomph than the original machine proposed for 2018 delivery with 180 petaflops at FP64.
With Helios, there is a chance to make things right for Argonne, and our chart shows at the same midpoint of a 4X performance increase expected for Discovery, Helios could come in at 7.9 exaflops at FP64 precision, giving it bragging rights over Oak Ridge and quite possibly with the future ATS-6 machine going into Lawrence Livermore a year or so later.
The National Energy Research Scientific Computing Center at Lawrence Berkeley has not traditionally been given the largest HPC system in the United States, but given how we needed controlled nuclear fusion power generation a decade ago, perhaps this should be a strategy going forward if we think advanced simulation might move the cause along and quite literally save the planet.

We think that NERSC-10 early access machine will be doing real work, which is why we show it as an upgrade and not as a distinct machine, and we think this because Perlmutter will be getting a bit long in the tooth by the time NERSC-10 goes into production in 2028. The stated goal is for NERSC-10, which has not yet been nicknamed as far as we know, to have 10X the application performance of Perlmutter on a suite of applications, and that is absolutely doable today and will be easier four years from now – and at a much lower price than Oak Ridge and Argonne paid to break the exascale barrier.
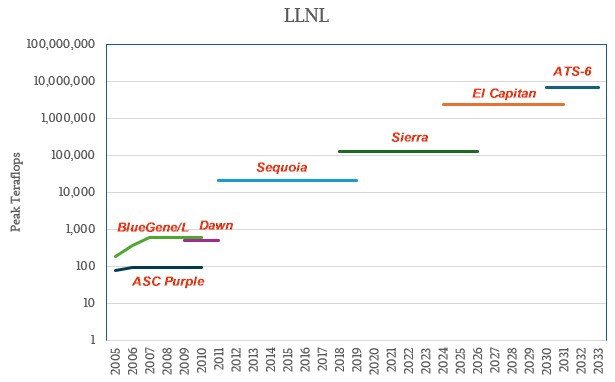
That leaves Lawrence Livermore in our analysis. The jump from BlueGene/L – the original BlueGene machine – to the “Sequoia” BlueGene/Q in 2011 was a factor of 33.8X leap in FP64 throughput, much better than log scale. But the jump from Sequoia to “Sierra” in 2018 was only 6.2X. However, the jump from Sierra to El Capitan this year could be anywhere from 15X to 20X, depending on what peak Lawrence Livermore was able to negotiate with Hewlett Packard Enterprise and AMD. We think it will be 18.3X, if you want us to call it.
We are expecting for ATS-6 to have a modest leap when it comes out around 2030 or so, perhaps only a 3X boost to 6.9 exaflops at peak FP64 precision. LLNL will get its time in the sun this fall and early next year as the top ranked supercomputer in the world, and it might be a title it holds for a couple of years.
We need nuclear fusion for power more than we need nuclear fission and fusion for war, so we think it is time to give NERSC the most funding of all of the US HPC centers.

The Final Frontier: Talking Exascale With Oak Ridge’s Jeff Nichols
Just ahead of the revelations about the feeds and speeds of the “Frontier” supercomputer at Oak Ridge National Laboratory concurrent with the International Supercomputing conference in Hamburg, Germany and the concurrent publishing of the summer Top500 rankings of supercomputers, we had a chat with Jeff Nichols, who has steered the …

Nuclear Weapons Drove Supercomputing, And May Now Drive It Into The Clouds
If the HPC community didn’t write the Comprehensive Nuclear Test Ban Treaty of 1996, it would have been necessary to invent it. More than any of the many factors that drive the development of capability-class supercomputers, including the desire to do great science to change the world for the better …

Slurm HPC Job Scheduler Applies For Work In AI And Hybrid Cloud
The Slurm Workload Manager that has its origins at Lawrence Livermore National Laboratory as the Simple Linux Utility for Resource Management – and which is used on about two-thirds of the most powerful HPC systems in the world – is looking for new jobs to take on across hybrid cloud …
> Why aren’t exascale-class machines upgraded?
A number of possibilities come to mind. If a system is intended as a NNSA “capability” machine (one application running on the entire system), rather than a “capacity” system (multiple, simultaneous, smaller jobs), there’s a big benefit to having a homogeneous (all nodes identical) design, rather than one that’s got multiple generations of CPUs, different B/F ratios for memory bandwidth, etc.
Another possibility has to do with the difficulty in planning for the interconnect network to span several generations of processors if you don’t want the final generation of CPU/GPU nodes to be hampered by a years-old network.
And tangentially, there may be some procurement and funding issues associated with trying to get an upgradeable system where much of the cost winds up front-end loaded.
Upgrading Machines –
If there were viable socket compatible upgrades that offered at least 2x performance benefit in the same thermal envelope, I bet you would see upgrades. That made a lot of sense when going from dual-core sockets to 6-core sockets in the same footprint.
A great rectification of the subliminal order of HPC things, rightwards, and upwards! And right in time for the 1-month countdown to the ballroom championship of supercomputing extravaganza that is SC24 (17–22 Nov’24, Atlanta, GA)! (within walking distance of Boone, NC!)
Can’t wait to see the suplex rhumba of the swashbuckling stronger swagger of El Capitan in full Kung Fu action on the dancefloor! Not to mention the tilt-a-whirl wheelbarrow tango of post-physiotherapy Sleeping Beauty, Aurora rising, from the countless kisses of dedicated (frogs) engineers, with wonderful hearts!
Which Frontier of computational choreography will they break this time? Will Fugaku’s Jujutsu be enough for it to keep its HPCG championship belt? Will the JEDI remain #1 at Green500? Will Sleeping Beauty fend off competitors on MxP? Who will steal the HPL crown from Frontier? And what of Graph500 and Io500? So many questions, so much suspense, and so many days of agony to wait for the answers! 8^b