

One of the benefits of the public cloud is that it allows HPC centers to experiment and push the limits of scalability in a way they could never do if they had to requisition, budget, and install machinery on premises. For a fairly modest sum – at least compared to acquiring a large cluster – they can do their experiments and perhaps help us all make better economic decisions about when, where, and how we run HPC workloads.
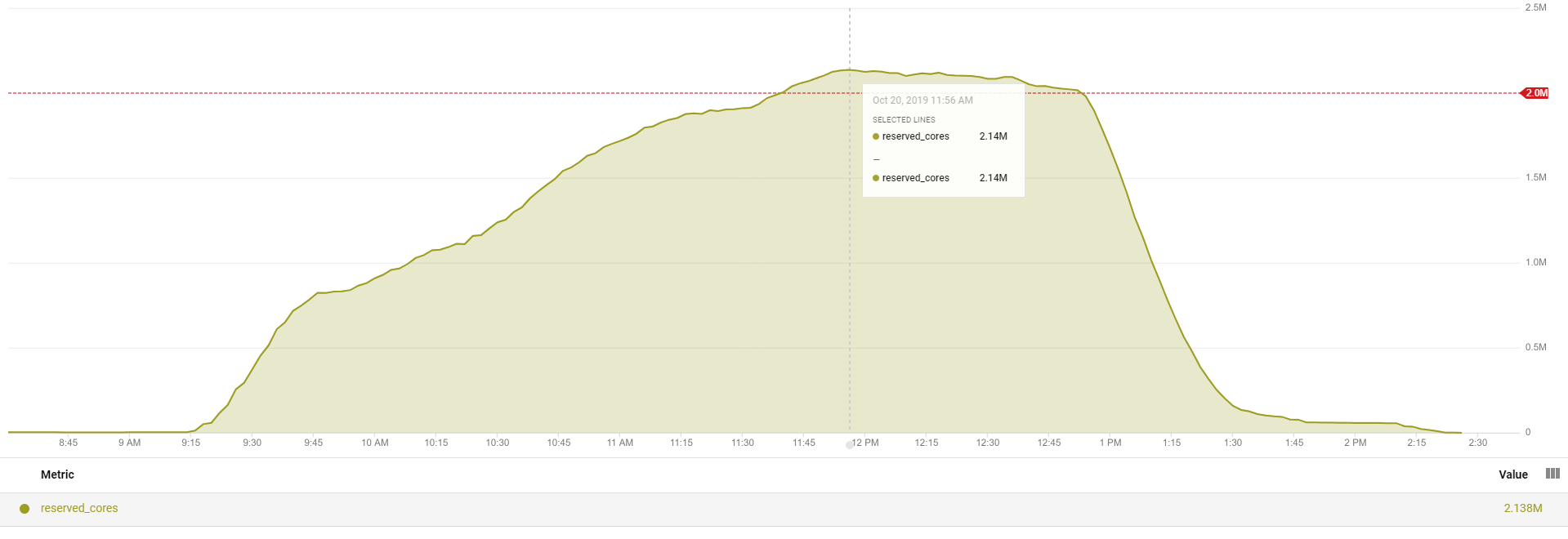
The Clemson University School of Computing recently set a new record for HPC in the cloud by running a data intensive application on 2.14 million virtual CPUs. This breaks Clemson’s previous record of 1.1 million vCPUs, which was also set by Clemson in 2017. HPC in the cloud at scale is now a reality as the Clemson team clearly showed that any organization with approximately $50,000 in budget can build, provision, and run a cloud-based, leadership-class supercomputer for precisely as long as it takes to do a particular simulation.
The Clemson team used 2.14 million vCPUs to visually count all the cars in 2 million hours of video, which is the amount of data captured every ten days from on the interstate highway network in the southeast United States, including South Carolina where Clemson is located. The application demonstrates how decision makers can use HPC to access precise, concrete real-world data when managing events like a hurricane evacuation. More specifically, the Clemson team used 210 TB of video data to simulate the size and number of video clips created by 8,500 camera feeds over a ten day period that would be collected during an assumed region-wide disaster event. (The Omnibond TrafficVision application counted cars, but also identified accidents, stopped vehicles, and other anomalies during the experiment.)
According to Amy Apon, director of the School of Computing, this work makes an important scientific contribution through its demonstration of “supercomputing at a scale that lets us investigate big systems, ones that we cannot observe completely and which exhibit complex behavior over time. Once verified, the data collected can be used to create and run models which scientists can then use to make predictions and perform experiments that would otherwise be impossible.”
Urgent HPC In The Cloud
As the Clemson experiment was not assisting in an actual emergency, the hero run was designed as a proof-of-concept at scale that the HPC community can reference for time-critical data-intensive “urgent HPC” in the cloud describes the ability the HPC community now has to support real-time, data-intensive emergency decision-making in situations that have strict time constraints. Apon points out that with cloud computing “organizations do not need to reserve massive amounts of computing or to stop all other on-going work at an organization to process massive amounts of data”. One such scenario occurs when decision-makers have to decide when and how to evacuate large numbers of people out of the path of a dangerous hurricane. In particular, the cloud-based run reflects and order of magnitude increase over the Clemson on-site computing resources, the Palmetto Cluster.

Computationally, think of cloud-based urgent HPC as a workload where researchers have to scale up the number of cloud instances (e.g. add resources) to deliver results according to a strict deadline, yet also scale-down when appropriate (meaning remove resources) to save on cost. Both are critical to cloud-based supercomputing.
It is important to note that the Clemson 2.14 million vCPU run was designed as a scalability trial use case as the team did not process data for a real evacuation. To show both cost affordability and scaling, the Clemson team duplicated some of the video data (which mean some of the vCPUs were processing identical video clips). The resulting run scaled-up to 2.14 million cores across 133,573 concurrent instances and took approximately 4 hours to complete after utilizing a total of 6,022,964 vCPU hours. Overall the run cost $52,598.64 which breaks down to an average cost of $0.0087 per vCPU hour. The scale-up/scale-down behavior is shown below.
Counting Cars In Traffic Camera Video Streams
The Omnibond TrafficVision application was used to visually assess the number of vehicles in the traffic cam video streams including counting cars. [i] The company provided the Clemson University team free access to their application, which conveniently utilizes existing highway camera infrastructure and provides a number of features needed to provide an accurate visual count of vehicles from traffic camera video streams including automatic recalibration after a traffic camera pans or zooms, an ability to work in all weather conditions, plus identification of stopped vehicles, debris on the roadway, pedestrians, lane changes, smoke or fog, along with many other features.
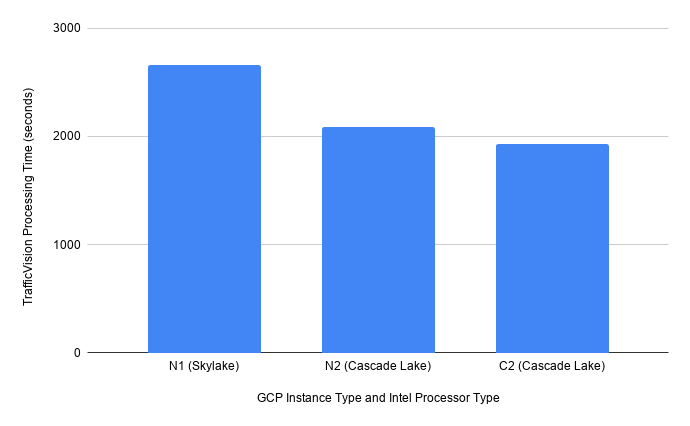
The TrafficVision software is designed to run efficiently on numerous hardware platforms including Cloud, COTS Servers, virtual machines, and hardened equipment in the field. As can be seen in the benchmark results below, the application can utilize the capabilities of the latest cloud hardware. The Google Cloud N2 machines used in the Clemson benchmark tests are designed to run general-purpose workloads, while C2 machines are compute optimized.
Implementing A Scalable Cloud Environment
Only three software systems were needed to implement this latest Clemson hero run on the Google Cloud: Omnibond CloudyCluster, the Clemson University automated Cluster Provisioning And Workflow (PAW) management system, and the TrafficVision application. The combination of CloudyCluster and PAWs is a tried and tested combination of tools for the Clemson team as this same combination was used in the earlier 1.1 million vCPU natural language cloud processing hero run performed on Amazon Web Services in 2017.
The user requirements to run at large scale while controlling costs are key requirements that guide the selection of the CSP and the selection of instance types for the urgent HPC run. The key lies in the provisioning of the workflow resources and managing the lifecycle of the scientific workflow while taking advantage of any low-cost cloud resources as they become available.
While common-sense at the high level, the implementation details are complex and rapidly changing as CSPs refine how they sell their spare capacity to users. Following is a comparison of spare computing capacity between the three main cloud providers made by the Clemson team as of August 23, 2019.
To prevent vendor lock-in, any urgent HPC project must be able to create a familiar, standard HPC environment that is both CSP agnostic and support on-demand dynamic scale-up provisioning.

The Clemson University PAW management system was used to provide researchers with a cloud-agnostic way to standup their HPC environment and manage both the cloud resources and scientific workflow. Succinctly, PAW automates the steps in dynamically provisioning a large-scale cluster environment, executing the HPC workflow, and de-provisioning the cluster environment when the workflow is finished. More detailed discussions of the relative benefits of PAWS vs vendor-specific frameworks are made elsewhere.
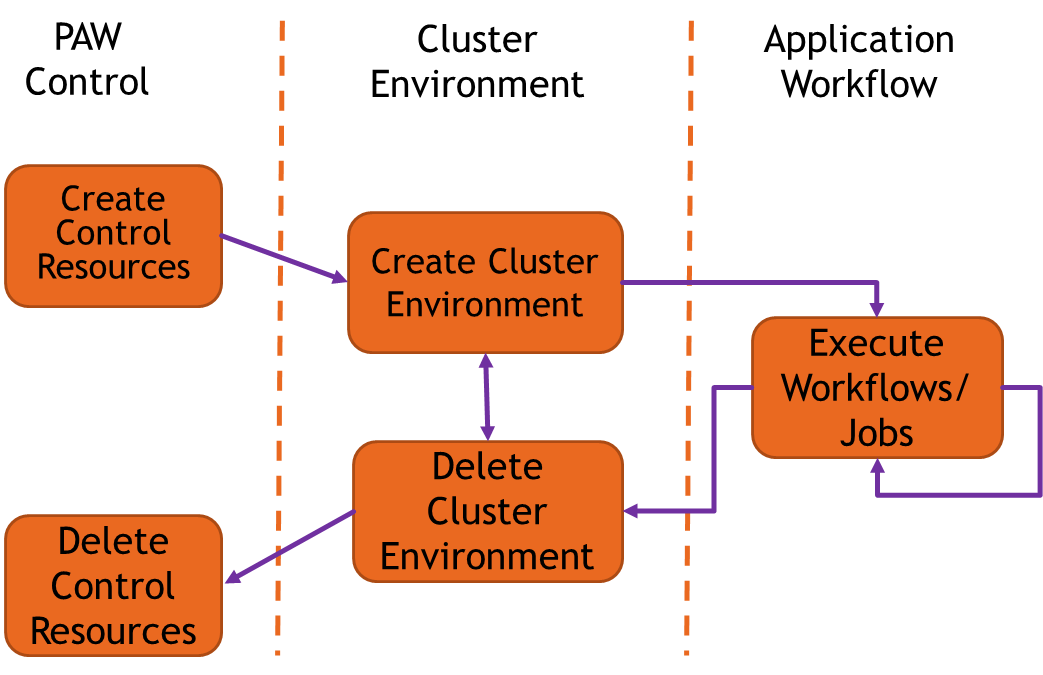
CSP workflow optimizations are possible within PAW, even though it is an agnostic tool. For example, the TrafficVision software is a CPU bound application that does not have a large memory footprint. With PAWS, the team was able to exploit this important feature to select the CSP technologies that reduced the costs of this experiment.
CloudyCluster Competition
CloudyCluster is used to quickly provision Intel Xeon Scalable processor-based compute instances on both AWS and Google Cloud.
Demonstrations show it can be used even by students to provision a wide selection of open HPC applications and dynamically configure the application access to storage. For example, CloudyCluster was used to provision the HPC environments at the recent Supercomputing 2019 student HPC Cloud competition in Denver, Colorado. Tom Krueger, Intel’s HPC sales enablement director, explains that the company helped sponsor the competition to demonstrate how accessible HPC in the cloud can be.
The CCQ meta-scheduler is important as it provides autoscaling capability so the HPC environment can scale-up the HPC environment as needed and scale-down to eliminate the costs of idle vCPUs. Readers will know that traditional HPC batch environments assume a fixed number of computational nodes. In reality, CCQ is a frontend system that provides a consistent interface to common and well known HPC schedulers such as Torque and Slurm.
In addition to autoscaling, CCQ handles a number of the challenges when running at scale such as denial-of-service issues that occur when thousands or tens of thousands of processor instances start up and attempt to communicate with the scheduler.
Tying it all together, the PAW implementation utilizes Omnibond CloudyCluster APIs and the Omnibond CloudyCluster Queue (CCQ) metascheduler to perform the key management tasks that can scale to on-demand million-of-CPU core HPC environments.
Regarding the PAW/CloudyCluster combination, Brandon Posey notes, “We can spin this up at scale wherever we want. “As shown in our previous work, we utilized the PAW/CloudyCluster combination to create a 1.1 million vCPU HPC cluster on AWS to perform topic modeling research. By utilizing a solution that has already been tested at a large scale on another cloud provider, we have the added benefit of a solution that can be deployed to multiple cloud providers which unlocks more available resources for urgent processing.”
Summary
The Clemson University hero runs demonstrate that HPC in the cloud when running workload on millions of cores is possible. This latest run using 2.14 million cores demonstrates how urgent HPC, again running at scale, can be used to provide information to decision-makers during emergency situations.
Rob Farber is a global technology consultant and author with an extensive background in HPC, AI, and teaching. Rob can be reached at info@techenablement.com.


Supply Chain Platforms Need A Disruption
Supply chains have become so complex and tangled that the traditional way of navigating everything from suppliers, inventory, transportation and analytics has been upended. As with all messes, there is deep commercial opportunity for any company that can handle clean-up in a novel, more streamlined way. In a post-2020 world, …

AI Accelerates Cloud Revenues As Well As Cloud Investments
Three years ago, thanks in part to competitive pressures as Microsoft Azure, Google Cloud, and others started giving Amazon Web Services a run for the cloud money, the growth rate in quarterly spending on cloud services was slowing. In the last few quarters, the rate of spending has begun accelerating …

Google Muscles Its Way Into Datacenters, Attacks From The Edge
Thomas Kurian’s arrival at Google Cloud in early 2019 after more than 22 years at Oracle marked a significant shift in Google’s thinking, putting an emphasis on expanding its cloud’s business use by enterprises as the key to making up ground on Amazon Web Services (AWS) and Microsoft Azure in …
Be the first to comment