
There are a lot of different kinds of machine learning, and some of them are not based exclusively on deep neural networks that learn from tagged text, audio, image, and video data to analyze and sometimes transpose that data into a different form. In the business world, companies have to work with numbers, culled from interactions with millions or billions of customers, and providing GPU acceleration for this style of machine learning is just as vital as the types mentioned above.
Up until now, many of the popular machine learning tools, which are open source, have been exclusively used on workstations or servers that used CPUs as their processing engines. To be fair, the SIMD engines inside of many popular CPUs have been supported with many of these tools, the Apache Arrow columnar database being an important one that often underpins the data scientist workbench; the Apache Spark in-memory database has been tweaked to make use of SIMD and vector units and also has other means of acceleration by compiling down to C instead of Java. This all helps. But with the launch of Rapids, a collection of integrated machine learning tools that are popular among data scientists, Nvidia and the communities that maintain these tools are providing the same kind of acceleration that HPC simulation and modeling and machine learning neural network training have enjoyed for years.
While the acceleration of the performance of these machine learning tools is important, the graphics chip maker has once again done its part to accelerate adoption of these tools, as it has on its Nvidia GPU Cloud, a repository of containerized software stacks for HPC and machine learning, by integrating and packing up the popular open source data science stacks employed by enterprises, academics, and government agencies. So Rapids is not just about massively speeding up the parallel chunks of these pieces of software, but making it easier for organizations to grab the code and just get to analyzing without having to spend precious time integrating it all and getting it working.
They have better things to do than be IT experts. Such as being experts in their own endeavors, be they academic or commercial.
“Companies today – retail, logistics, finance, genomics, businesses across the board – are becoming more and more data driven,” explains Jeffrey Tseng, director of product management for AI infrastructure at the GPU maker. “And more and more they are using analytics and machine learning to recognize very complex patterns, to detect change, and to be able to make predictions that affect the operations of the company by generating more revenue or reducing waste. There are lots of different ways companies can benefit from using data, and it has become essential for any company that wants to lead in an industry. Companies need to manage these large sets of data. Even a slight bit of optimization – even a few percentage points – in how they are dealing with marketing spend or generating revenue can have a big impact on the bottom line.”
This is always about money. Sometimes the trend is to adopt a technology to save money or do things that were not previously possible – Hadoop is a great example of this – and sometimes it is about driving the business.
About a decade ago, data analytics had a second wave of innovation, due mostly to the creation of open source stacks like Hadoop or Spark, as well as tools from the Python community. These Python tools are important not so much because they have commercial entities backing them, but because millions of users who actually do data analytics, rather than build core infrastructure for the datacenter, have deployed them – with or without the help of the IT organization. The important Python tools include:
- The NumPy multidimensional array store that has hooks into C/C++ and Fortran and that includes linear algebra routines, Fourier transforms, and random number generation.
- Scikit-Learn, which is a machine learning tool built upon NumPy that can do classification, regression, clustering, dimensionality reduction, model selection, and data preprocessing and is distinct from the GPU-accelerated frameworks we talk about a lot here at The Next Platform.
- Pandas, which is a data store for tabular data and time series data that is used to manipulate data for various kinds of statistical analysis and machine learning.
- Anaconda, which is a Python framework for statistical analysis in the R language as well as for running Scikit-Learn, TensorFlow, H2O.ai, and XGBoost frameworks for machine learning. Anaconda has an open core model, with some enterprise add-ons that are closed source, and it has over six million users worldwide of its various stacks.
To be blunt about it, Anaconda had built a pretty broad stack of tools that did what lot of Python-happy data scientists needed, and it is reasonable to wonder why Nvidia is jumping in here. The answer is quite simple. The data science pipeline is a complex one, as you can see:
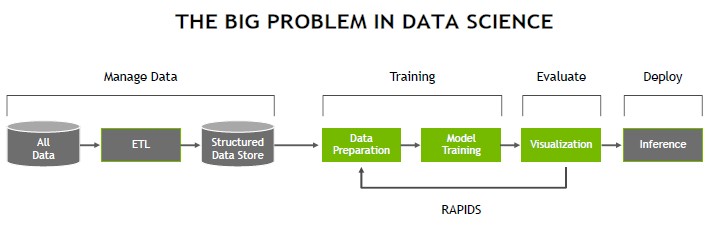
Similar, in fact, to the complex pipelines we find in HPC and the deep learning flavor of machine learning that uses neural networks (a very complex kind of self-feeding statistical analysis) instead of other approaches. Nvidia wants to make sure that every kind of machine learning and statistical analysis – including the data ingest, data manipulation, data interpretation, and data visualization – is accelerated by GPUs, thus increasing its total addressable market.
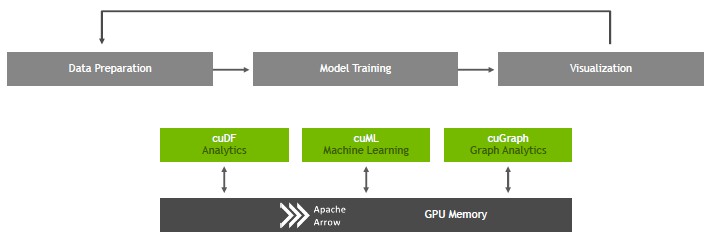
To that end, Nvidia, working with various communities creating the open source tools mentioned above, has created libraries that help to take parallel portions of these tools and offload them to GPUs for acceleration. The initial set includes three key libraries – cuDF for analytics, cuML for machine learning, and cuGraph for graph analytics – plus acceleration for the Apache Arrow columnar data store. Databricks is also working with Nvidia to have integration with the Apache Spark in-memory database (which it sells as a service but open sources for others to use), and it is reasonable to assume that in the fullness of time there will be more direct acceleration of Spark itself than has been done to date. These three libraries are being open sourced by Nvidia under an Apache 2.0 license and the source code is available now at rapids.ai as well as being packaged up in Docker containers and made available for download on private infrastructure or on public clouds with GPU instances through the Nvidia GPU Cloud.
As you might imagine, a slew of companies that sell own GPU-accelerated databases and visualization platforms have already created similar routines. The more the merrier, but it is reasonable to expect that now that these libraries are hardened and delivered by Nvidia, many of these players will think about employing the Nvidia libraries for acceleration and integrate it into their databases and data science workbenches. Tseng said as much, but gave no hints about who is doing what when. Databricks is working to integrate Spark with Apache Arrow storage, which is GPU accelerated and also, through Project Hydrogen, has the ability to schedule routines to run on GPUs. Wes McKinney, of Ursa Labs and the creator of Apache Arrow and Pandas, has endorsed it, which says a lot. Various system vendors and cloud builders, including Hewlett Packard Enterprise, IBM, Oracle all stood up and gave Rapids their blessing, and in addition to HPE and IBM, Cisco Systems, Dell, Lenovo, and Pure Storage have said that they will weave the Rapids stack into the data analytics and machine learning stacks on their systems and/or storage. Hadoop and Spark distributor MapR Technologies said the same. At the moment, Rapids needs a “Pascal” or “Volta” generation of GPU accelerator and needs to have CUDA 9.2 or 10 on the machine; only Canonical Ubuntu Server 16.04 LTS and 18.04 LTS are supported, and the Docker container has to be at CE v18 or higher.
The important thing about the libraries that Nvidia has hardened and packaged is how they make the data science workflow move more rapidly – hence, the name of the set of tools. Using the XGBoost framework for machine learning, here is how the whole workflow was accelerated running on a cluster of five DGX-1 systems (with 40 Volta Tesla V100 GPUs) and a single DGX-2 system (with 16 Volta Tesla V100 GPUs) compared to Xeon-based servers with clusters of 20, 30, 50, and 100 nodes. Take a look:
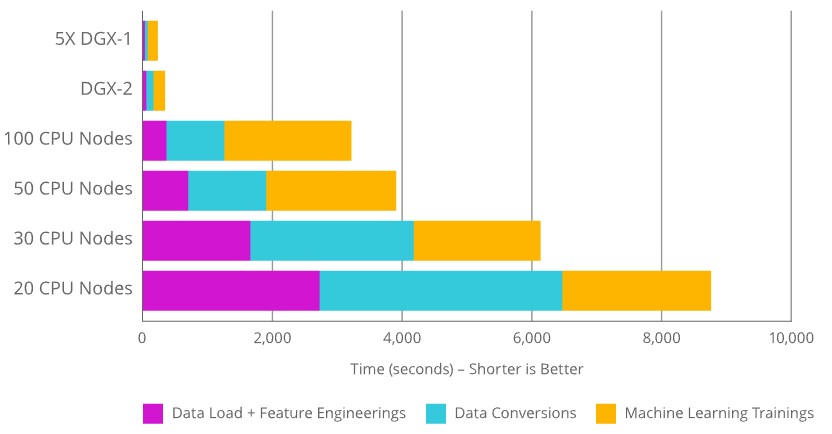
As this chart makes clear, the data analytics and machine learning pipeline is not just running statistics or building neural networks, but includes a substantial amount of time for data loading and data conversions so machine learning frameworks can chew on them. This is as true for tabular data as it is for image, video, text, and voice data. (Some day, with the right kinds of senses, the world will be awash with smell and touch data, completing the human sense set.) Nvidia said in its press release and the statements it made at GTC Munich this week that a single DGX-2 was up to 50X faster than a compute cluster. Wherever that statement comes from, it doesn’t come from the chart above.
We did not have access to the raw data, but we printed the chart out and got out our trusty drafting rulers and did some measuring. Assuming the chart is not flawed, it looks like that 20 node cluster did the whole workflow in 8,675 seconds, and adding ten nodes to the cluster dropped it down to around 6,100 seconds. Adding 20 more nodes reduced it down to around 3,900 seconds, and doubling it again to 100 nodes cuts it back to only 3,500 seconds. Obviously, there is a point of diminishing returns in scaling out the cluster. Putting it all on a few fat GPU accelerated nodes really kicks it up a few notches. As best as we can figure from this chart, the DGX-2 with 16 GPUs can do the entire workflow in about 312 seconds, and a quintuple of DGX-1 servers with eight GPUs each can do it in around 206 seconds. If you do the math on that, assuming the worst case cluster of 20 nodes, then that is a factor of 42X speedup for the DGX-1 cluster compared to the Xeon cluster and a factor of 28X speedup for the DGX-2. The DGX-2 costs $399,000 while the network of DGX-1 machines costs $745,000 and only reduces the time by 30 percent. It makes far more sense to buy two DGX-2 systems for about the same money and maybe get that workflow down to 150 seconds.

How Nvidia Blackwell Systems Attack 1 Trillion Parameter AI Models
We like datacenter compute engines here at The Next Platform, but as the name implies, what we really like are platforms – how compute, storage, networking, and systems software are brought together to create a platform on which to build applications. Some historical context is warranted to put the Blackwell …
Deep Dive Into Nvidia’s “Hopper” GPU Architecture
With each passing generation of GPU accelerator engines from Nvidia, machine learning drives more and more of the architectural choices and changes and traditional HPC simulation and modeling drives less and less. At least directly. But indirectly, as HPC is increasingly adopting AI techniques, having neural networks learn from real-world …
Deutsche Bank Tag Teams With Nvidia On Financial Services AI
In many industries, embracing AI in the application software stack it is not just a matter of training some large language models or recommender systems against general and then specific datasets and plugging it in. And in any regulated industry – particularly financial services because it deals with Other People’s …
Be the first to comment