
Arm Holdings has announced that the next revision of its ArmV8-A architecture will include support for bfloat16, a floating point format that is increasingly being used to accelerate machine learning applications. It joins Google, Intel, and a handful of startups, all of whom are etching bfloat16 into their respective silicon.
Bfloat16, aka 16-bit “brain floating point, was invented by Google and first implemented in its third-generation Tensor Processing Unit (TPU). Intel thought highly enough of the format to incorporate bfloat16 in its future “Cooper Lake” Xeon SP processors, as well in its upcoming “Spring Crest” neural network processors. Wave Computing, Habana Labs, and Flex Logix followed suit with their custom AI processors.
The main idea of bfloat16 to provide a 16-bit floating point format that has the same dynamic range as a standard IEEE-FP32, but with less accuracy. That amounted to matching the size of the FP32 exponent field at 8 bits and shrinking the size of the FP32 fraction field down to 7 bits.
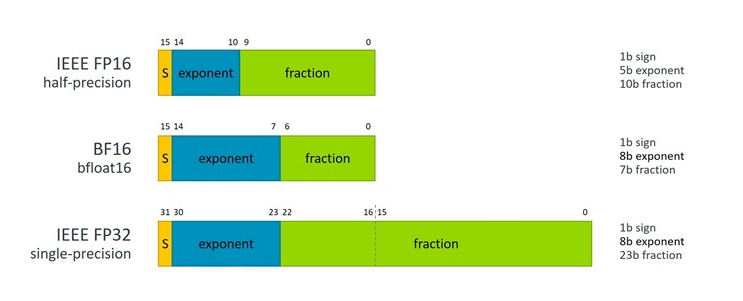
According to Nigel Stephens, a lead ISA architect and Fellow at Arm, in most cases, the format is as accurate as FP32 for neural network calculations but accomplishes the task with half the number of bits. As a result, throughput can be doubled, and memory requirements can be halved, compared to its 32-bit counterpart. And for the most part, blfloat16 can be a “drop-in” replacement for FP32 in these machine learning algorithms. “Fortunately, neural networks, due to their statistical nature, are surprising resilient to a small amount of noise, so long as the data type has sufficient range and precision,” Stephens told us.
In the case of Arm, the additional support will apply to all the floating point instruction sets supported under the ArmV8-A umbrella, namely SVE (Scalable Vector Extension), AArch64 Neon (64-bit SIMD) and AArch32 Neon (32-bit SIMD). The additional support is designed to be used for both machine learning inference and training across Arm-based clients and servers. While the Arm server space is still tiny, its client footprint is enormous, which means that future generation of hand-held and IoT device will soon be able to take advantage of the more compact numeric format.
In a blog he penned in August, Stephens reported that four new instructions will be added to support the multiplication of blfoat16 values, the most common computation used to train and inference neural networks. According to him, in most cases application developers won’t be fussing with the low-level code to add such instructions, since support will in all likelihood be provided by Arm’s own machine learning libraries. But for those interested in the nitty-gritty, the four new instructions are as follows:
- BFDOT, a [1×2] × [2×1] dot product of BF16 elements, accumulating into each IEEE-FP32 element within a SIMD result.
- BFMMLA, effectively comprising two BFDOT operations which performs a [2×4] × [4×2] matrix multiplication of BF16 elements, accumulating into each [2×2] matrix of IEEE-FP32 elements within a SIMD result.
- BFMLAL, a simple product of the even or odd BF16 elements, accumulating into each IEEE-FP32 element within a SIMD result.
- BFCVT, converts IEEE-FP32 elements or scalar values to BF16 format.
The inclusion of bfloat16 support in SVE is especially interesting, inasmuch as these vector instructions were developed specifically for high performance computing. As of today, the only known SVE implementation is in Fujitsu’s A64FX chip, the processor that will power the upcoming Post-K supercomputer, which now goes by the name of Fugaku. That implementation was too early to get the benefit of bfloat16, but later ones, like the Arm processor being developed for the European Processor Initiative (EPI) will almost certainly include it.
Stephens said that given the increased interest in machine learning from conventional HPC users and the suitability of their high performance systems to training large neural networks, the inclusion of bfloat16 in SVE seemed like a natural addition. He also noted that there are HPC researchers investigating the use of the new 16-bit format to accelerate mixed-precision calculations for traditional scientific applications. “Again bfloat16’s advantage is that it has the same dynamic range as FP32, which makes it easier to convert existing code that uses FP32 to use blfloat16 for early phases of a large, iterative computation,” he explained.
And since SVE can be implemented for different vector lengths, from 128 bits up to 2,048 bits, theoretically the bfloat16 throughput should scale accordingly compared to a 128-bit Neon implementation. In practice, though, Stephens said that throughput will also depend upon the specific hardware implementation choices, such as the number of SVE execution units versus the number of Neon execution units for a given implementation.
There is, however, a trade-off between the ease of deployment of a blfoat16-based network and its final size and the performance, when converted to types with smaller range such as INT8 and FP16. Stephens said that using blfoat16 for inference may be attractive for developers who cannot afford the additional cost and delay of retraining a network to utilize these smaller types (which can take several months) when there’s a single type that works for both training and inference.
The other thing to be aware of is that there is no standard for bfloat16 numeric behavior, so there’s no guarantee that the results of the same calculation will be exactly the same on different processors. But as Stephens points out, that kind of variability is even present with FP32 with regard to how dot products are ordered (IEEE leaves ordering open). In any case, rounding noise is almost always acceptable because, as Stephens said, machine learning is a statistical game.
Arm’s support of bfloat16 leaves GPUs – both Nvidia’s and AMD’s – as the only widely used machine learning engines that still do not offer native support of the format. But given that the two most widely used processor architectures on the planet now do, it would seem GPU support is all but inevitable. Including Intel’s forthcoming Xe GPU accelerators. Whether IEEE ever embraces bfloat16 and offers up some standards – well, that remains to be seen.

The Prospects For An Arm Server Insurrection
If you want to break into datacenter compute in a sustainable way, it takes the patience of a glacier. And not just any glacier, but one that predates the Industrial Revolution. The reason is that IT shops are a conservative lot, and change comes slowly, even when they seem to …
Inside Tesla’s Innovative And Homegrown “Dojo” AI Supercomputer
How expensive and difficult does hyperscale-class AI training have to be for a maker of self-driving electric cars to take a side excursion to spend how many hundreds of millions of dollars to go off and create its own AI supercomputer from scratch? And how egotistical and sure would the …
Nvidia Unfolds GPU, Interconnect Roadmaps Out To 2027
There are many things that are unique about Nvidia at this point in the history of computing, networking, and graphics. But one of them is that it has so much money on hand right now, and such a lead in the generative AI market thanks to its architecture, engineering, and …
The reason it’s called “Brain float” is that it was invented originally by Google’s Brain unit, one of the pioneering groups in machine learning. Google has been using bfloat16 in its chips since 2017, starting with TPUv2.
This blog goes into more detail
https://cloud.google.com/blog/products/ai-machine-learning/bfloat16-the-secret-to-high-performance-on-cloud-tpus
To
DAVID PATTERSON.
SIR
Why u devoted ur last book on Risc v an open source core.Do u think it replace ARM someday?
Excellent post. I was checking continuously this blog and I am inspired! Extremely helpful info particularly the last part 🙂 I handle such information a lot. I was looking for this certain information for a long time. Thank you and good luck. |