

As artificial neural networks for natural language processing (NLP) continue to improve, it is becoming easier and easier to chat with our computers. But according Nvidia, some recent advances in NLP technology are poised to bring the much more capable conversational AI into mainstream applications.
Significantly, in the past several months, the capabilities of some of the models that perform NLP have reached an accuracy level that surpasses humans, repeating a pattern that the industry saw back in 2014 when image recognition software could do an equal job to the best humans at this task against a database of known images. This is the point where image recognition could take off as an application in the real world, not just an interesting research project in industry and academia.
Included in the NLP application space are digital voice assistants, document summary systems, customer service chatbots, and sentiment analytics. Juniper Research predicts that digital voice assistants alone will grow from 2.5 billion to 8 billion over the next four years. And according to Gartner, 15 percent of all customer service interactions will be completely handled by AI in 2021, representing a four-fold increase from 2017.
NLP is already mainstream in a number of web service and business applications. A well-known use case is Microsoft Bing, which is employing it to deliver better search results from queries that are fed to it. However, some of the more interesting applications are coming from startups. Clinc, for example, has built a conversational AI system for customers in healthcare, banking, and auto manufacturing. Another startup, Passage AI, is building a state-of-the-art chatbot, while another, Recordsure, is applying NLP technology to conversational analytics, with an eye toward regulatory compliance in the financial sector.
Bryan Catanzaro, vice president of Nvidia’s Applied Deep Learning Research group, says while progress in the field is moving quickly on both the research and commercial fronts, teaching computers to have really high quality conversations with human beings remains one of AI’s more ambitious goals. “This is a difficult task because in order to do this, the computer needs to be able to understand meaning,” he says. “And that’s always been challenging.”
According to Catanzaro, what is primarily needed is larger models that can understand the nuance inherent in human conversations. The ability to understand context also demands more sophisticated models with larger numbers of parameters. And being able to train those models rapidly, so that researchers can refine them in reasonable time frames is also needed.
On the inference side, what is required is real-time responses, typically 10 milliseconds or less. “The reason they have that target is because if it takes too long to compute the answer for the model, people will feel that the response is very slow, making the interaction less natural and less useful,” explains Catanzaro.
A popular NLP model today is BERT, which stands for Bidirectional Encoder Representations from Transformers. The reference to transformers refers to a type of neural network that can transform an input sequence to an output sequence. In the case of BERT though, the model is trained in both directions, that is, it evaluates text in the context of what’s to the left and right of it. Many in the community consider BERT a turning point for NLP, something equivalent what ResNet did for image recognition in 2015.
Recently Nvidia was able to train a BERT model in 53 minutes using a DGX-2 SuperPOD. Typically, this would take several days on a multi-GPU server. Even on a 16-GPU DGX-2, training this model took 2.8 days. But since the SuperPOD is comprised of 92 DGX-2 systems, Nvidia was able to scale the training nearly linearly across the 1,472 GPUs, performing the task in less than an hour.
BERT was developed by researchers at Google in 2018, but since then a number of variations of if have been developed by different companies, including Facebook (RoBERTa), Alibaba (Perseus-BERT) and Microsoft (MT-DNN). XLNet, developed by researchers at Carnegie Mellon University and Google borrows some techniques from BERT, but also integrates others from Transformer-XL.
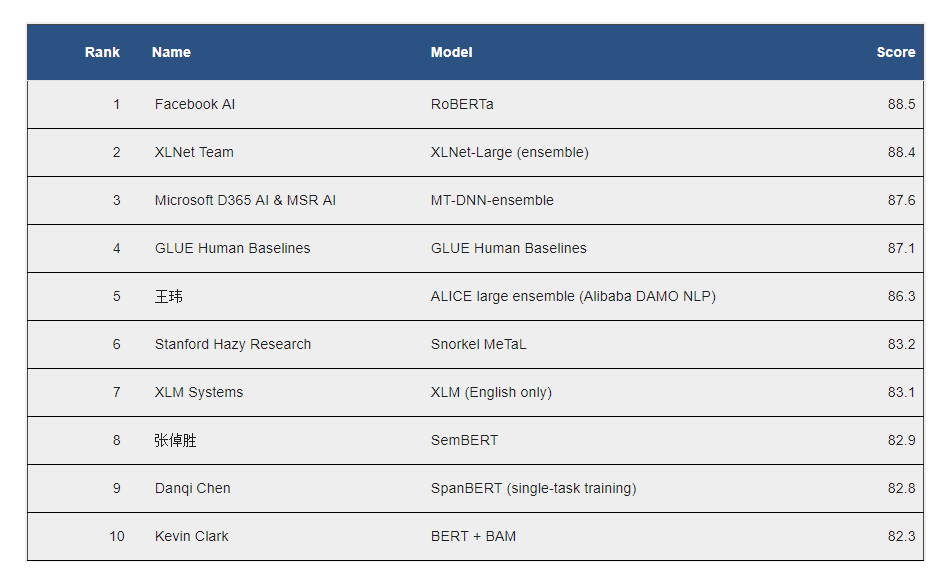
Some of these models are now outperforming humans on the General Language Understanding Evaluation (GLUE) benchmark, a collection of metrics for evaluating NLP systems. Below is the current GLUE leaderboard for the top 10 models, with the human baseline now sitting at number four.
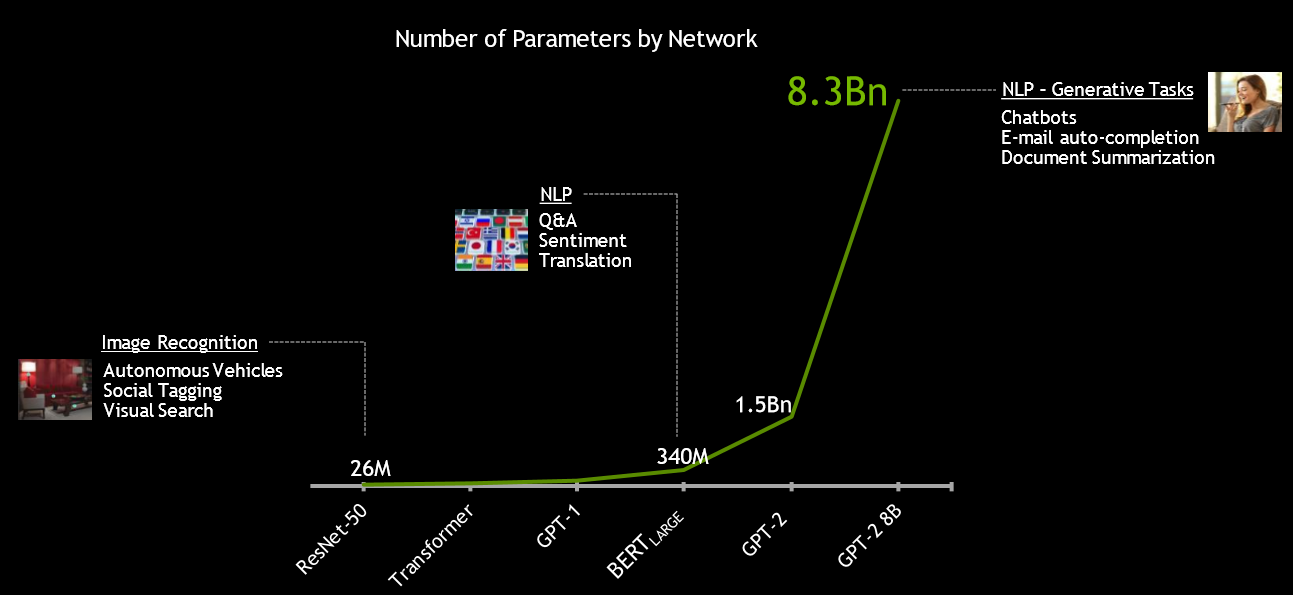
The BERT-Large model includes about 340 million parameters, but under Project Megatron and running on its DGX-2 SuperPOD supercomputer, Nvidia has built an even more complex network that has 8.3 billion parameters. The GPU-maker believes models of this complexity will be required to perform NLP generative tasks, such as document summaries, state-of-the-art chatbots, and email auto-completion. Catanzaro says it took weeks to train that model on the same DGX-2 SuperPOD. Inevitably though, that time will shrink as GPUs get more powerful and systems get bigger and better connected (thanks Mellanox). We are on the hockey stick of ever-improving performance, as you can see below:
On the inference side, Catanzaro points to their latest results from their T4 GPUs running TensorRT-optimized code. Using the SQuAD dataset on a BERT-Base mode, responses were delivered in 2.2 milliseconds, which is well within the 10 millisecond conversational threshold. In their tests, CPUs took 40ms to run the same inference task. Of course, FPGA-based solutions and a wide array of custom ASICs aimed at AI inference promise to deliver similar, if not better, latency. And since CPUs, like the “Cascade Lake” Xeon SPs, are now being optimized for inference, we should not be too quick to dismiss them.
Despite all this progress, Catanzaro thinks we still have a way to go until these systems can pass the Turing test, a point at which the responses from a computer would be indistinguishable from that of a human. As a result, he believes NLP is destined to remain an active field for research and development for the foreseeable future. Which, come to think of it, is just what Nvidia would want.

The Buck Still Stops Here For GPU Compute
It has taken untold thousands of people to make machine learning, and specifically the deep learning variety, the most viable form of artificial intelligence. And this is so true today that people just say AI for all three because the distinction is academic. One of the key researchers who has …
Tuning Up Nvidia’s AI Stack To Run On Virtual Infrastructure
Having to install a new kind of systems software stack and create applications is hard enough. Having to master a new kind of hardware, and the management of it, makes the situation worse. And for normal enterprises, this makes embracing AI in its many forms difficult. Enterprises looking to embrace …

AIST Taps HPE And Nvidia For Next-Gen AI Cloud Machine
The National Institute of Advanced Industrial Science and Technology (AIST) in Japan is going to be installing the third generation of its AI Bridging Cloud Infrastructure 3.0 supercomputer. The machine will consist of thousands of Nvidia’s current “Hopper” H200 generation of GPU accelerators, which is not surprising. But interestingly, it …
Be the first to comment