
We have to admit that it is often a lot more fun watching an upstart carve out whole new slices of business, or create them out of what appears to be thin air, in the datacenter than it is to watch how it will respond to intense competitive pressures and somehow manage to keep growing despite that.
But honestly, that is the easy part. Being truly innovative once or twice or even three times, while not normal, is something that has been done by many companies in the six decades of commercial and technical data processing and visualization. Innovating to a decade is hard, for two or three decades is tough as hell, and doing it for longer than that – IBM has been at it for a dozen decades now and is still in the information technology game it created more than any other firm in history – is highly improbably but not impossible.
We have great admiration for those companies that find niches, create markets, and crack them wide open to benefit with revenues and profits. This is how the system – the economic one – is supposed to work.
Nvidia is one such company, and it is important to remember that Nvidia is relatively new to compute but has definitely changed the game for certain kinds of simulation, modeling, analytics, and machine learning workloads. Mellanox Technologies has similarly been an innovator, commercializing the InfiniBand networking protocol – which was supposed to be a kind of universal switched fabric for all kinds of clients and servers but it didn’t quite work out that way – for HPC centers and then moving on a few years ago to Ethernet switching. Mellanox has been a champion of offloading as much of the networking workload onto network interface cards and the switches themselves to free up compute capacity on servers, and this has freed up untold of amounts of compute capacity to do real work on many clusters over the past two decades that InfiniBand has been shipping.
Of course, Nvidia is in the middle of acquiring Mellanox for $6.9 billion, and it is this fact as well as increasing competition from Intel and AMD and the first awards for exascale systems in the United States that has us pondering what possible paths Nvidia might take to get its datacenter business growing again despite both Intel and AMD moving in on its GPU acceleration turf for both HPC and AI workloads.
Both Nvidia and AMD were caught a little flatfooted by the steep decline in demand for GPU compute for cryptocurrency mining as 2018 was winding down, and this turns out to have been a bigger component of sales of GPU cards than either company had expected. To be fair, it is tough to track who is using what card for what job when the vast majority of Nvidia and AMD GPU sales are pulled through channel partners, who don’t always have perfect visibility into customer accounts. Compute clusters doing funky stuff like risk management, advanced analytics, machine learning, private HPC, and cryptocurrency mining are precisely the kinds of machinery that people keep mum about. So it is hard to blame Nvidia or AMD for not knowing how much of this business is driven by what precise workloads and for not seeing the massive drop off in revenues from the cryptocurrency segment that happened in 2018. If Intel had been shipping its 11th generation Xe discrete GPU graphics and compute cards two years ago, instead of next year, it would have ridden up its share of the wave and would have been equally bruised up when that wave crashed on the rocks.
One has to be philosophical about such ephemeral phenomena. Companies make the money when they can and where they can, and they do not look gift customers in the mouth. So it was with Nvidia and AMD and the cryptocurrency miners and their several year affair with GPUs, which happened to drive up demand for GPU compute at precisely the same time that HPC and AI workloads accelerated by GPUs were ramping sharply. This allowed Nvidia in particular to command a hefty premium for its Tesla GPU accelerator cards in general, which pumped up its datacenter business considerably in recent years. Entering the systems business, where Nvidia sells components for nearly completed systems (HGX) or finished systems (DGX) has also helped accelerate Nvidia’s datacenter business in recent years.
Depending on if three fourths of the OpenPower hardware partnership – that’s IBM, Nvidia, and Mellanox, but not including Xilinx in this case – is able to close a deal for an exascale system with Big Blue as the prime contractor, Nvidia could try to go it alone and bid on its own for future exascale system and it could even chase sub-exascale hybrid AI/HPC system deals. Stranger things have happened, and Intel has certainly set a precedent for this, starting way back with the Paragon Touchstone Delta system at Caltech in 1992, ASCI Red at Sandia National Laboratories in 1996, and now the Aurora A21 system at Argonne National Laboratory due in 2021 as the first exascale system in the United States, and one that will deploy a mix of Xeon CPUs and Xe GPUs. The Aurora nodes will be connected using Cray’s “Slingshot” HPC-style Ethernet interconnect, and Cray, which is being acquired by Hewlett Packard Enterprise for $1.3 billion, is the system integrator on the project, working with Intel. Oak Ridge National Laboratories, which currently is running applications on its new “Summit” hybrid IBM Power9 CPU/Nvidia Tesla “Volta” V100 GPU accelerator, the first exascale class system at this lab, called “Frontier,” was not based on IBM’s future Power10 processor paired with a future (perhaps “Einstein”) Nvidia GPU, but rather a mix of Epyc CPUs and Radeon GPUs from AMD, with the nodes also linked by Cray’s interconnect and with Cray as the prime contractor. Well, soon to be HPE.
These two machines represent about half of the $2.4 billion budget for exascale systems in the United States, and there is one and potentially another system in the works. The other system in the CORAL-2 round of funding that we know about for sure is the “El Capitan” ATS-4 successor to the “Sierra” system (also a hybrid Power9/Volta system) at Lawrence Livermore National Laboratory. Because the Department of Energy has traditionally liked to spread out its risk across two or three different vendors and their respective architectures, El Capitan has a high probability of staying with a Power/Tesla combination, but as Oak Ridge’s 1.5 exaflops Frontier system, slated for late 2021 or early 2022, shows, there is no guaranty in this market and LLNL said as much as Sierra was being prepped for roll out at the end of 2017. But the expectation back in late 2017, as Bronis de Supinski, chief technology officer at Livermore Computing, the IT arm of the nuclear research lab, was for the El Capitan machine to offer GPU acceleration of some sort.
It is possible that El Capitan could be based on that Power10/Einstein combo and likely with 400 Gb/sec InfiniBand interconnect from Mellanox and therefore give the OpenPower partners some funds to cover development costs. (Most of the $600 million or so dedicated to an exascale system is used up buying parts to build the machine, with some leftover for software development, chassis and enclosure design, maintenance, and we presume a tiny bit of profit.) But given what happened with the Summit and Sierra machines, which were both based on IBM’s Power AC922 server with different GPU and main memory configurations (but the same CPU and network interface cards), it is now equally likely that Lawrence Livermore will follow suit and deploy a clone of or variant of the Frontier system based on AMD compute engines and Cray interconnect.
Should that happen, this would obviously be a big blow to IBM, Nvidia, and Mellanox. Nvidia GPUs are being used in the pre-exascale “Perlmutter” NERSC-9 machine at Lawrence Berkeley National Laboratory, which is being built by Cray for $146 million and which uses “Rome” Epyc CPUs from AMD; Cray’s Slingshot interconnect is being used here, too. It seems very unlikely that the NERSC-10 exascale follow-on, due in 2024 or so, would shift to Power10 processors and a future InfiniBand interconnect and use future Nvidia GPUs, but anything is possible even it if is not probable. NERSC has picked a different CPU and then accelerator architecture for the past four machines, so there is precedent. A lot depends on how well AMD’s CPUs and GPUs and Cray’s Slingshot interconnect works – and what AMD and HPE want to charge for an exascale supercomputer.
For the moment, Nvidia can count on its Tesla GPU accelerators being the engines of choice for machine learning training, no matter what host CPU is deployed to manage the work that those GPUs use, and to still be the dominant accelerator used for traditional HPC simulation and modeling applications for those places that can employ accelerators rather than just raw CPU clusters. This is true mainly because all of the key machine learning frameworks and the core commercial and open source HPC applications have all been tweaked to support the CUDA parallel programming environment created by Nvidia to manage the work on the GPU accelerators. While AMD has ROCm alternative for its CPU-GPU combinations, and Intel is working on OneAPI to make a development environment that can span CPUs, GPUs, and FPGAs, for now OpenMP, OpenACC, and CUDA are being used in various ways to develop and tune hybrid CPU and Tesla accelerator applications, and Nvidia has tuned up all of the various math libraries needed for their applications to run well on GPUs, and so Tesla GPUs remain the de facto accelerator for those organizations that need more than just what a straight CPU can deliver in terms of compute and memory bandwidth.
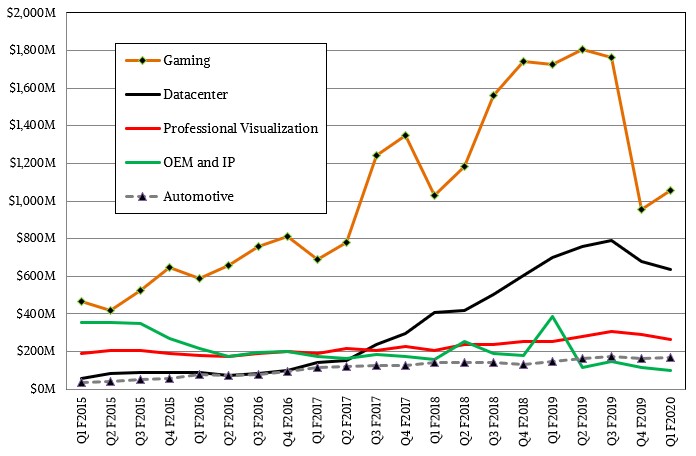
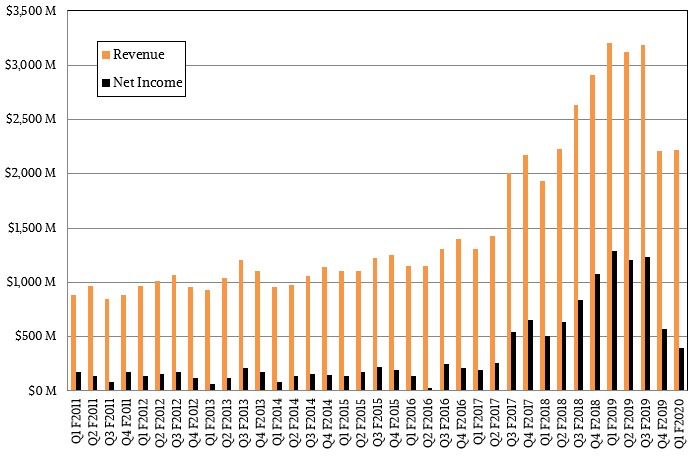
This is, of course, the key driver to Nvidia’s datacenter business. Relatively speaking – and against some very tough compares last year when Nvidia booked sales of GPUs for the Summit and Sierra supercomputers, the hyperscalers were spending like tipsy sailors, and cryptocurrency mining had not dropped – the datacenter group at Nvidia is doing pretty well. The hyperscalers took a pause in the first quarter of fiscal 2020 ended in April, and as we have pointed out many times, spending by HPC institutions and by hyperscalers and cloud builders is choppy, and sometimes the curves build to new highs and sometimes they combine to dive to lows. This is one of those times, and even still, Nvidia’s datacenter business was only off 9.6 percent to $634 million. Gaming GPU sales, by sharp contrast, were down 38.8 percent to $1.06 billion; professional visualization products actually had a 6 percent increase to $266 million, and self-driving car initiatives drove Nvidia’s automotive sales up 14.5 percent.
Interestingly, Nvidia is starting to get some traction with its Tesla T4 GPU accelerators, whose “Turing” GPUs can be used for machine learning inference at prices and performance and thermals that are competitive with FPGAs and can also be used for training in a pinch and for visualization with dynamic ray tracing as well. (The Tensor Core dot product engines are the key there.) In a conference call with Wall Street analysts recently, Nvidia chief financial officer Colette Kress said that “the contribution of inference to our datacenter revenue is now well into the double-digit percent.” Call it $65 million out of $634 million, just for fun. That means without the T4 accelerators and the drive for better bang for the buck on inference, the datacenter business would have been off around 19 percent. All of the major clouds and server OEMs are supporting T4 cards for inference workloads.
It remains to be seen if Nvidia can own machine learning inference as it does machine learning training. Most machine learning inference is being done on CPUs still, but this is an inefficient and expensive way to do inference (at least at hyperscale) and very large companies that are leaders in applying machine learning are looking an offload model to inference engines that cost a lot less and burn even less juice than modestly sized GPUs and FPGAs. Intel’s Nervana unit as well as Wave Computing, and Graphcore are taking aim at FPGAs and CPUs for inference, but Intel has to be careful to not denigrate its own CPUs and FPGAs as it pushes Nervana devices.
With machine learning training, everyone is gunning for Nvidia’s Tesla GPU accelerators, and at a time when Nvidia is being particularly quiet about its future roadmaps. Graphcore, Nervana, and Wave Computing are out there, pushing the heftier of their devices for machine learning training, and some of the folks at Google who worked on the Tensor Processing Unit (TPU) project have left to form Groq, which seeks to create and commercialize a clone of the TPU. Google claims that its TPU 3.0 AI engine can do both inference and training on the same device.
All of these companies, plus myriad others chasing the nascent but presumably hockey sticking inference markets, are going to put a tremendous amount of pressure on Nvidia. But, then again, Nvidia is used to pressure. It’s not like competing with AMD in graphics and wedging its way into the supercomputer arena was a walk in the park.
The good news is that for the moment, GPUs are the only practical accelerators for certain accelerated HPC simulation and modeling applications, and given the nearly 400 applications that can be GPU accelerated, this should provide a steady – if bumpy – revenue stream for Nvidia’s datacenter business. Hyperscalers and cloud builders will be buying Tesla accelerators for HPC and machine learning training workloads, and there will be ups and downs here. The cloud builders in particular will be averse to using a specialized device aimed just at machine learning because they need to create infrastructure that can be repurposed on a whim. A device that can do virtual desktop infrastructure, visualization, database acceleration, HPC simulation and modeling, and machine learning training and inference in a pinch will trump a device that just does machine learning training on the clouds – even if it costs a premium. Cloud builders need flexibility – but not at any cost, of course.
When Nvidia was the only game in town, it can – and did – charge a premium for its Tesla GPU accelerators. With AMD getting its CPU and GPU acts together and Intel trying to break into the discrete GPU market with more earnestness than it did with “Project Larrabee” (which spawned the Knights family of many-cored processors that had some play in HPC and AI) so many years ago, Nvidia is not going to be able to command the premiums it has enjoyed. This is going to get harder, not easier, and even if the top line grows, it may be difficult to grow operating income for the datacenter unit.
Mellanox will snap in, hopefully by the end of this fiscal year in January 2020, to bolster the datacenter group’s numbers at Nvidia, to roughly something on the order of $1 billion a year, carved up in the choppy ways that hyperscalers, cloud builders, and HPC centers spend on server adapters and switches (or OEMs and ODMs spend on the chips to make these devices). Mellanox finished up its first quarter in March, and did not hold its normal conference will Wall Street where it goes over the different aspects of its business. This is about all we know:
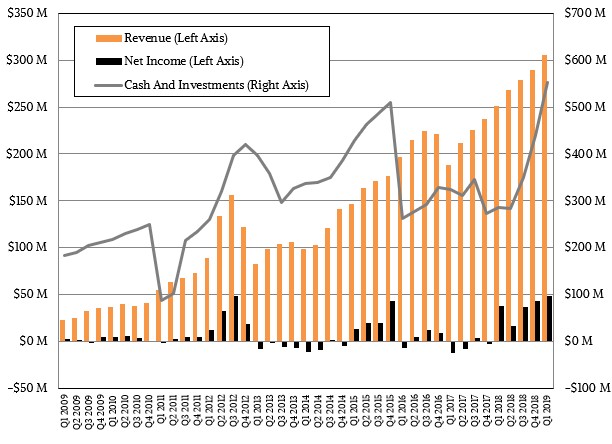
Mellanox revenues rose by 21.6 percent to $305 million in the first quarter, and net income rose by 28.5 percent to $48.6 million. Mellanox ended the quarter with $533 million in cash, which ends up going back into Nvidia’s pocket once the acquisition is done. We have no idea how well or poorly any Mellanox products did, because Mellanox did not host its call with Wall Street, but we suspect that InfiniBand sales are flat sequentially as they have been for the past few quarters and Ethernet sales continue to rise. By the way, that is the most revenue that Mellanox has ever posted in a quarter, but it has been twice as profitable – for a brief time back in 2012 – before. Add Mellanox to the datacenter business at Nvidia, and you have a company that sells around $4 billion a year in stuff, even with the downdraft that Nvidia is coping with.
It is still not clear exactly how Nvidia will make use of Mellanox, but a few things are clear. One, AMD is back in the CPU and GPU game and its products are winning deals at the hyperscalers, cloud builders, and HPC centers of the world and enterprises won’t be that far behind. Two, Intel is getting its manufacturing act together and it has a new team that is working to get better CPUs and now new GPUs in the field to complement its Altera FPGAs. Several Arm server chip vendors – mainly Marvell and Ampere – are keeping the pressure on Intel and AMD a little and there are upstarts coming out of the woodwork going after the machine learning money with specialized ASICs that promise better efficiencies than GPUs or FPGAs can deliver.
That leaves the OpenPower founders – IBM, Nvidia, Mellanox, and Xilinx – as a kind of counterbalance to Intel and AMD. In early 2017, we contemplated why IBM should literally buy Nvidia, Mellanox, and Xilinx to build momentum for a modern systems business with all the elements needed. IBM’s Power Systems business generates north of $2 billion a year, and so does Xilinx, and if you add in the $4 billion or so from the datacenter businesses of Nvidia and Mellanox, this is a better counterbalance to the hegemony of Intel and the rising AMD. If Nvidia wants to preserve its own Switzerland status with its OEM and ODM partners, it might want to think about working with IBM and Xilinx to create a partnership that can take down exascale-class deals as well as sell components to those OEMs and ODMs.
We have thought, and continue to think, that in a world accelerated by FPGAs and GPUs, IBM should cut the vector engines out of a Power9 or Power10 chip and just create a screaming fast serial engine with huge amounts of memory bandwidth and lots of ports to offload work to those accelerators. IBM and Nvidia have worked out coherency across the CPU and GPU, and the FPGA can be woven into this, too. These are real advantages.
There might be time still to set up the OpenPower Company before it is too late. It would have to be called something different, of course. Spectrum is an obvious name that both Mellanox and IBM use in their high performance products, and it would truly sell the spectrum of compute and networking. These companies can pool their wares a little more intensely instead of wasting money buying each other.
It’s a thought.

Gordian Knot: Broadcom And TSMC To Cut Intel Into Two?
People are impatient for Intel to get fixed, and have been for many years. Weird deal after weird deal keeps coming out of the rumor mill, and now we have rumors that rival chip designer and seller Broadcom and rival chip manufacturer Taiwan Semiconductor Manufacturing Co want to cleave Intel …

OpenAI To Join The Custom AI Chip Club?
It would be hard to find something that is growing faster than the Nvidia datacenter business, but there is one contender: OpenAI. Open AI is, of course, the creator of the GPT generative AI model and chatbot interface that took the world by storm this year. It is also a …

Who Will Build Europe’s First Exascale Supercomputer – And With What, And Why?
Exascale supercomputing is just as important to Europe as it is to the United States and China, but each of these geopolitical regions on Earth has its own way of developing architectures, funding their development and production, and figuring out where the best HPC centers are to host such machines …
It is my personal belief that the world is pretty much stuck with the x86 ISA for the next few decades. What IBM should have used their perpetual x86 license to create a line of x86 processors with NVLink or compatibility with NVSwitch. That would have given the industry three choices to procure x86-based servers with differing memory and I/O capabilities (HyperFabric, NVSwitch etc), depending on the chip design. The IBM Systems business would have grown instead of the permanent shrinking mode with the POWER and Z line + storage. But then, that requires a CEO and an executive team with guts and foresight….nah, there is none of that in IBM at the moment.