
(Sponsored Content) By its very nature, high performance computing is conflicted. On the one hand, HPC belongs on the bleeding edge, trying out new ideas and testing new technologies. That is its job, after all. But at the same time, HPC centers have to compete for budget dollars and they have to get actual science done, and that means they also have to mitigate risk just like every other kind of IT organization.
What this has meant, historically, is that HPC centers have had a rich tradition of experimentation that is not unlike – but which definitely pre-dates – the fast-fail methodology espoused more recently and more famously by the big hyperscalers that dominate the Internet with their services.
Whether HPC or hyperscale, the effect is the same during a technology transition. When an idea works, it is quickly tweaked across many different architectures and vendors and before you know it, the way HPC is done radically and swiftly changes. To simplify quite a bit, this is how the industry moved from proprietary vector supercomputers to parallel clustered RISC/Unix NUMA machines to massively parallel systems based on generic X86 processors running Linux and the Message Passing Interface (MPI) to allow nodes in clusters to share data and therefore scale workloads across ever larger compute complexes. It is also how we have come full spiral back around again to GPU-accelerated vector compute engines, which mix the best of the serial CPU and the parallel GPU to create a hybrid that can push the performance envelope for many simulation and modeling applications.
The first time that AMD broke into the bigtime with server processors, back in the early 2000s with its “Hammer” family of Opteron CPUs, HPC customers were on the front end of the adoption wave because of the substantial benefits that the Opteron architecture offered over the Intel Xeon processors of the time. The Opteron chip had fast HyperTransport pipes to link CPUs together in NUMA shared memory clusters and to hook peripherals, such as high-speed interconnects from Cray, into their compute complexes. Opteron was also architected from the ground up to have 64-bit memory addressing (thus breaking the 4 GB memory barrier of the 32-bit Xeons of the time). And it was designed to scale up inside the socket, with multiple cores on a die to drive up performance per socket when Moore’s Law hit its first speed bump.
Every chip maker hits its own speed bumps, and there are no exceptions. In the mid-1990s, Intel was working to extend the Xeon line with 64-bit memory addressing when it decided instead to partner with Hewlett Packard to create the Itanium chip which had a radically different architecture that, in many ways, was superior to the X86 architecture that had come to dominate the datacenter. We could go on at length about the Itanium strategy and products, but suffice it to say that Intel’s bifurcated strategy of keeping Xeons at 32-bits and pushing Itanium for 64-bit processing and memory addressing left a big gap for AMD Opterons to walk through right into the datacenter. And while the Itanium enjoyed some success in HPC, thanks in large part to Hewlett Packard and SGI, it was the Opterons that took off, eventually powering a quarter of the bi-annual TOP500 rankings of supercomputers.
History never precisely repeats itself, but it does spiral around in a widening gyre. Now, some ten years after AMD ran into issues with its Opteron line, it is Intel that is struggling – in this case, both with architectures for HPC systems (the Knights family that was aimed at HPC and AI workloads has been shut down, as has been Itanium finally) and with its vaunted manufacturing capability to push the Moore’s Law curve stalled due to substantial delays in rolling out its 10 nanometer wafer etching processes. And if all goes according to plan, AMD looks to capitalize on Intel’s woes with its next generation Epyc processors, codenamed “Rome,” due in the middle of this year.
It has taken more than six years to get to this point for AMD, which exited the server field of combat a decade ago and which has spent the last two years talking up (and selling) its first generation Epyc processors, formerly codenamed “Naples,” and building credibility with public cloud, hyperscaler, enterprise, and HPC customers alike. To re-establish trust with both the OEMs and ODMs who design and build servers and the customers who buy them takes time, and that means setting performance and delivery targets and hitting them. To its credit, AMD has thus far kept to the roadmap it laid out two years ago with the Epyc processors, and confidence in these chips is building just as the company is preparing its assault on the HPC space. A lot of things, not the least of which being the 7 nanometer manufacturing processes from Taiwan Semiconductor Manufacturing Corp, which is now etching AMD’s server CPU and GPU processors, are coming together to give AMD a very good chance to revitalize its HPC business.
“Last year was an important time in the ramp of Epyc,” Daniel Bounds, senior director of data center solutions at AMD, tells The Next Platform. “From cloud builders and hyperscalers to high performance computing, the value of Epyc caught hold and helped those organizations raise the bar on the performance they can and should expect from a datacenter-class CPU. There is such a stark difference in the economies of scale compared to what the competition can bring. For HPC, there are two camps. The first deploys memory bandwidth-starved codes, which is where the current generation of Epyc really shines giving customers a massive advantage either with the capability of more performance per rack unit or equivalent level of performance with less gear. With codes like CFD and WRF, you can really think about hardware configuration differently and increase the effectiveness of every IT dollar spent. The second camp has been split between taking advantage of current offerings like the Epyc 7371, which has a killer combo of high frequency cores at very reasonable price points or waiting for the next generation 7 nanometer Epyc product due out mid-year which we expect will bring 4X the floating point performance.”
The jump in floating point math capability is going to be substantial moving from the current generation of Epyc to the next generation, as we discussed in detail last November when AMD revealed some of the specs of its future CPU. The vector units in the next generation Epyc cores will be twice as wide, at 256-bits per unit, and there will be twice as many cores on the die as the first gen parts, at 64 cores. So, at the same clock speed, the next generation Epyc products should be able to do four times the floating point work as the first generation Epyc chip, which was already able to stand toe-to-toe with the “Skylake” Xeon SP-6148 Gold and Xeon SP-6153 Gold processors that are commonly used in the price-conscious HPC sector.
This last bit is the important thing to consider, and it gives us a baseline from which we can compare the first generation and the next generation Epyc chips from AMD to the current Skylake and newly announced “Cascade Lake” processors from Intel. Most HPC shops cannot afford the heat or the cost of the top bin Skylake Xeon SP parts from Intel, and they tend to use low-cost parts where memory capacity and NUMA scaling are not as important as in those top bin parts.
Here is how AMD stacks up a pair of its top bin first gen Epyc 7601 processors, with 32 cores running at 2.2 GHz each, against a pair of the mainstream Skylake Xeon SP 6148 Gold processors on the SPEC integer and floating point tests, which is the starting point in any comparison:
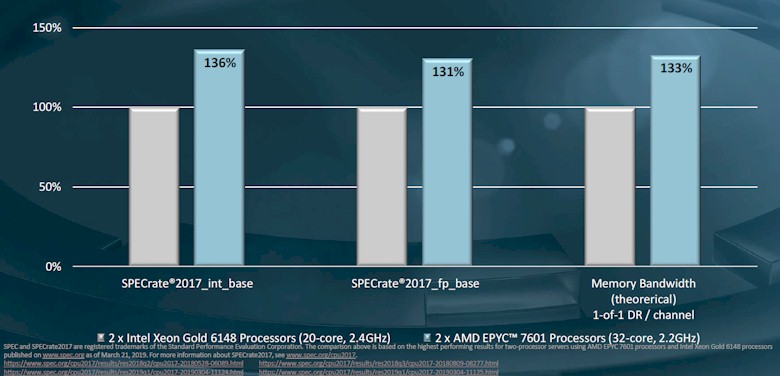
At list price, the performance increase is basically neutralized by the difference in price of the machines. The Intel Xeon SP 6148 Gold processor has a list price of $3,072 when bought in 1,000-unit quantities, while the AMD Epyc 7601 costs $4,000 a pop in those same 1,000 unit quantities. But list price is just a ceiling on the price that HPC centers pay for the large number of processors they deploy in their compute clusters – a starting point for negotiations. AMD and its partners can – and do – win deals by being competitive with street prices for processors for HPC iron.
There are a lot of ways to dice and slice the processor lineups from AMD and Intel to try to gauge performance and price/performance. Another way to do it is to try to get two processors that have something close to the same core counts, clock speeds, and raw double precision floating point performance. In this case, AMD likes to compare its Epyc 7371 chip, which is essentially an overclocked Epyc 7351 that just started shipping in the first quarter of 2019, which has 16 cores running at 3.1 GHz (29 percent higher than the base frequency of the Epyc 7351), to Intel’s Xeon SP-6154 Gold processor which has 18 cores running at 3 GHz.

The Epyc 7371 started sampling last November, and it is specifically aimed at workloads where single-threaded performance is as important as the number of threads per box, and wattage is less of a concern because of the need for faster response on those threads. Think electronic design automation (one of the keys to driving Moore’s Law, ironically), data analytics, search engines, and video transcoding. In any event, AMD Epyc 7371 and Intel Xeon SP-6154 Gold chips have essentially the same SPEC floating point performance, and the AMD chip, at $1,550, costs 56 percent less than the Xeon in this comparison, which has a list price of $3,543.
Of course, SPEC is not a real application, but just a microbenchmark that illustrates theoretical peak performance for a given processor. It is a good starting point, to be sure – akin to table stakes to play the game. To make a better case for the Epyc chip, AMD pit the top bin Epyc 7601 against Intel’s top bin Skylake Xeon SP-8180M, which has 28 cores running at 2.5 GHz, running the Weather Research and Forecasting (WRF) weather simulation using the CONUS 12 kilometer resolution dataset. Here is how a single node running WRF stacked up:
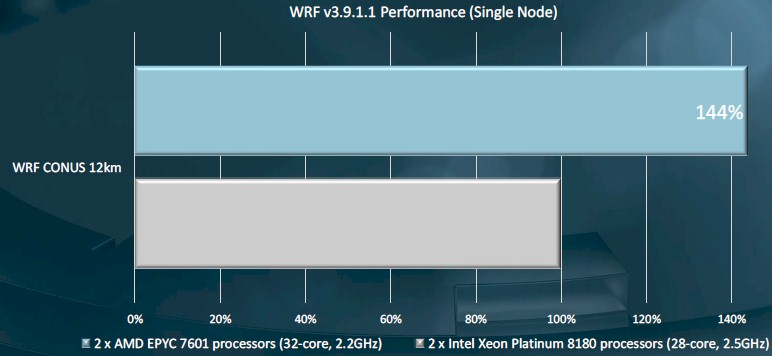
Each server running the WRF code had a pair of the AMD and Intel processors, and the AMD machine delivered 44 percent more performance, due to the combination of more cores and more memory bandwidth. In this case, the Xeon SP-8180M has a list price of $13,011, which is 3.25X as expensive as the Epyc 7601, so the price/performance advantage is definitely to AMD on this one. Walking down the Skylake bins will lower the price, but it will also lower the performance, so there is no way for Intel to close this gap until it launches “Cascade Lake,” and shortly thereafter, AMD is expected to be able to quadruple its floating point performance with the next generation Epyc, potentially burying even the two-chip Cascade Lake AP module on performance and price/performance. We won’t know for sure until both products are announced. But the game is definitely afoot.
AMD has also done a series of comparison benchmarks using the ANSYS Fluent computational fluid dynamics simulator on single nodes and across multiple nodes equipped with Skylake Xeon and Epyc processors. In these tests, AMD compared two socket machines using the middle bin Xeon SP-6148 Gold (20 cores at 2.4 GHz) to the middle bin Epyc 7451 (24 cores at 2.3 GHz) and the new HPC SKU, the Epyc 7371 (16 cores at 3.1 GHz). The Epyc 7451 delivers more performance than the Epyc 7371, but at $2,400 each compared to $1,550, it also costs more, too. Take a look:
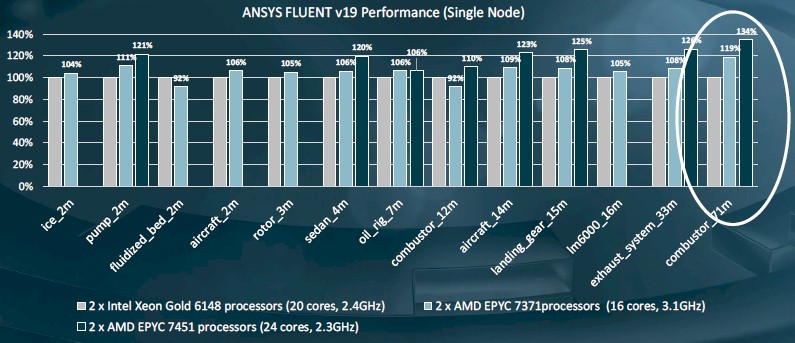
It is a bit peculiar that not all of the ANSYS Fluent tests were performed on the Epyc 7451 in the chart above. But it almost doesn’t matter since the Epyc 7371 costs less and still competes with or beats the Xeon SP-6148 and costs 49.5 percent less per CPU.
This more interesting HPC comparison is one that AMD did for the ANSYS Fluent simulation of a flow through a combustor with 71 million cells, a fairly dense simulation, across 1, 2, 4, 8, and 16 nodes with these three different processors.
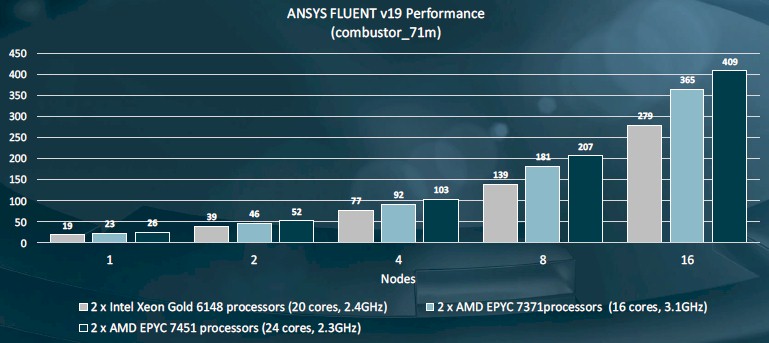
The nodes with the Epyc 7371 processors bested the performance of those with the Xeon SP-6148 Gold, and shot the gap between these Xeon chips and the more expensive and more cored Epyc 7451 processors. The incremental cost of the higher bin Epyc chip is greater than the performance gain, and this would also be true if you jumped from the Epyc 7451 to the Epyc 7601. This is just the nature of chip manufacturing – higher bin parts are more rare and therefore cost more to make, hence they have a higher price – whether it is the Xeon or Epyc lines. Or pretty much any other processor, for that matter. The question you have to ask is who ramps the prices fastest as you climb the bins.
Incidentally, all of the results shown above are using the open source GCC compilers on both the Intel Xeon and AMD Epyc processors.
The HPC Ramp Takes Time
Given the pressure that HPC centers are always under to get the most compute for the buck or euro or yen or renminbi, you might think that the current generation Epyc processor would have taken off in HPC already. But the HPC ramp has taken time as software vendors have tuned their code for the Epyc architecture.
The 32-core Epyc chips pack four eight-core chiplets on a die, which are linked together using PCI-Express transports and the Infinity Fabric protocol (a kind of new-and-improved HyperTransport), in a single socket to look like a single compute element. These chiplets present NUMA regions in the socket to the operating system kernels, and that can be an issue for certain kinds of workloads, such as a virtual machine running on a hypervisor that spans two or more chiplets in a socket or multiple chiplets across a pair of sockets.
But with capacity-class supercomputers that have lots of users and codes that run on CPUs and that cannot be accelerated (or haven’t been accelerated by GPUs because of the hard work involved), HPC centers usually just stack up MPI ranks, one per core, and off they go a-scaling. Those latencies across the chiplets inside of a multicore module don’t matter as much because the HPC workload is not trying to span two or three or four chiplets at once. But supercomputers tend to be on a three or four year upgrade cycle, and a lot of customers, who first started hearing about the current generation Epyc processors with any detail in 2016, took a wait and see attitude, especially after many thought AMD burned them by leaving the field all to Intel back in 2009. (It is hard to quantify how much the lack of competition in the X86 server processor space added to the cost of compute, but it could be easily billions of dollars.)
Here is the fun bit. The next generation Epyc processors, which will use a mix of 7 nanometer cores and 14 nanometer I/O and memory controller chips, will be better suited to HPC because of architecture tweaks, both in the floating point units and in the Infinity Fabric within the socket, at exactly the time when Intel is starting to run out of gas on its 14 nanometer process used for the prior two generations of Xeon chips and also for the Cascade Lake and future “Cooper Lake” Xeon SP processors. For all of the talk about application scalability, a lot of HPC jobs only need 64 cores or 128 cores, and with the next generation Epyc processors, what that means is that one or two sockets of aggregate compute will do the trick for running most jobs – a very interesting development indeed. This could mean an uptick in the deployment of single-socket server nodes in the HPC sector, just like The Nikhef National Institute for Subatomic Physics in Amsterdam has done with the current generation of Epyc using a Dell EMC PowerEdge R6415 cluster.
“Without sharing the number, there was a big, big chunk of our overall 2018 volume that was for one socket servers,” says Bounds. “The way we think about it is: Why wouldn’t everybody want to build off a single socket platform if there are licensing as well as operational, power, and cooling benefits? If it is a better and more performant solution, why wouldn’t you do that?”
And the answer was something interesting, there’s still a notion that you need need a two-socket server because it is redundant. Yeah, we know. A regular two-socket server is not a redundant machine, just a scaled one. You lose one processor, you lose the whole machine. But apparently a lot of people in the IT biz don’t know the difference between NUMA shared memory and a Stratus or Concurrent fault tolerant machine from days gone by.
“With the next generation Epyc processor, you combine the fact that we have introduced this idea to the market and we anticipate functionally doubling if not quadrupling what you can get out of a socket – integer and floating point, respectively – and that is going to continue to grow the adoption of single socket,” says Bounds.
And there is a very good chance that HPC shops will be as enthusiastic about the next generation Epyc chips as they once were with the Opterons, no matter what Intel does with Cascade Lake and its next-in-line “Cooper Lake” – and maybe even the 10 nanometer “Ice Lake” CPUs coming in 2020, too.

Now Comes The Hard Part, AMD: Software
From the moment the first rumors surfaced that AMD was thinking about acquiring FPGA maker Xilinx, we thought this deal was as much about software as it was about hardware. We like that strange quantum state between hardware and software where the programmable gates in FPGAs, but that was not …
AMD Makes A Big DPU Move With $1.9 Billion Bid For Pensando
Lisa Su has had the datacenter in her sights since taking over as president and chief executive officer of AMD in 2014, charting a course that would allow the processor maker to once again become a factor in the global server market after a decade or so in the wilderness …
Ampere Readies 256-Core CPU Beast, Awaits The AI Inference Wave
How many cores is enough for server CPUs? All that we can get, and then some. For the past two decades, the game in compute engines has been to try to pack as many cores and additional functionality as possible into a socket and make the overall system price/performance come …
“To re-establish trust with OEMs and ODMs who design and build servers and customers who buy them takes time, means setting performance and delivery targets and hitting them.
Time to tape out, sample, market, yield, volume on contract then the Intel cross license guns take the market on standard supply bi lateral tied contract volumes stimulating in excess of real time demand procurements.
“To simplify quite a bit, this is how the industry moved from proprietary vector supercomputers to parallel clustered RISC/Unix NUMA machines to massively parallel systems based on generic X86 processor and the Message Passing Interface (MPI) . . .
Supplying on time on budget industrially competitive volumes controlled by dealers, see no evil, hear no evil, smell no evil by Justia is definitively deaf, blind and dumb, limited on essential Intel bi lateral channel procurement contracts.
Gold 6148 20C @ 50% off 20C Average Weighed Price $1437.51; $461.80 @ 85% discount, Intel MR = MC at $215.63.
“At list price, performance is basically neutralized by the difference in price of the machines. Xeon 6148 Gold processor list price of $3,072 bought 1,000-unit quantities, AMD Epyc 7601 costs $4,000 a pop in same 1,000 unit quantities. But list price is just a ceiling on the price HPC centers pay for the large number of processors they deploy in compute clusters – a starting point for negotiations. AMD and its partners can – and do – win deals competitive with street prices for processors for HPC iron.”
“There are a lot of ways to dice and slice the processor lineups from AMD and Intel to try to gauge performance and price/performance.”
“AMD likes to compare its Epyc 7371 chip, which is essentially an overclocked Epyc 7351 which has 16 cores running at 3.1 GHz (29 percent higher than the base frequency of the Epyc 7351), to Intel’s Xeon SP-6154 Gold processor which has 18 cores running at 3 GHz.
Gold 6154 18C @ 50% off 18C Average Weighed Price $1604.41 that is industrial price discrimination v 20C; $481.32 @ 85% discount; Intel MR = MC at $244.66.
Epyc 7371 16C and Epyc 7351 16C @ 50% off 16C 1K AWP = $475.77; $317.18 at design producer 3 way stakeholder split; manufacturer MR = MC @ $159.59.
“In any event, AMD Epyc 7371 and Intel Xeon SP-6154 Gold chips have essentially the same SPEC floating point performance, and the AMD chip, at $1,550, costs 56 percent less than the Xeon which has a list price of $3,543.”
😉
Xeon SP-8180M has a list price of $13,011, which is 3.25X as expensive as the Epyc 7601.”
Platinum 8180M 28C @ 50% off 28C Average Weighed Price $5369; $1610 @ 85% discount; Intel MR = MC at run end $351.79 to $305 on a good yield day.
Epyc 7601 32C @ 50% off 32C 1K AWP = $1130.61; $753.7 at design producer 3 way stakeholder split; manufacturer MR = MC @ $376.87
“In these tests, AMD compared two socket machines using the middle bin Xeon SP-6148 Gold (20 cores at 2.4 GHz) to the middle bin Epyc 7451 (24 cores at 2.3 GHz)”
Epyc 7451 24C @ 50% off 24C 1K AWP = $934.12; $622.75 at design producer 3 way stakeholder split; manufacturer MR = MC @ $311.37.
“Without sharing the number, there was a big, big chunk of our overall 2018 volume that was for one socket servers,” says Bounds.”
All 1P Epyc = 11.77% of uni, 2-way and 4-way Epyc. Adding TR 32C = 20x Epyc 1P. Adding 24 and 16C TR = 26x all Epyc 1P. Majority 1P is Thread ripper.
“You make the best of it. You tweak the Skylake architecture in a number of ways, in quick succession, to keep customers moving. This is precisely what Intel did with its Cascade Lake chips today”
In a re-equilibrium Intel will supply Cascade Lake 2X demand through 9 months then move to period doubling?
“By cramming 56 cores onto a single ball grid array (BGA), Intel can talk about performance leadership and perhaps even decent price/performance in a two-socket machine”
This is just the nature of chip manufacturing – higher bin parts are more rare and therefore cost more to make, hence they have a higher price”
Not exactly, slippery slope.
“(It is hard to quantify how much the lack of competition in the X86 server processor space added to the cost of compute, but it could be easily” trillions “of dollars.)”
I guarantee it.
Presler AWP @ 1K AWP < 50% volume discount = $101.27
Cedar Mill AWP @ 1K AWP < 50% volume discount = $129.50
Smithfield Dual core AWP @ 1K AWP < 50% volume discount = $241
Mike Bruzzone, Camp Marketing
“Adding TR 32C” All of your credibility whent out the door when you mixed in a the consumer Threadripper(“TR 32C”) part in the same post/article that only concerns Epyc/Professional Server SKUs compared to Intel’s Xeon professional competition. And this is not the first time you have done so.
Let’s stop that nonsense this very instant as parts that have no proper vetting/certification for ECC Memory usage have no place being included for actual usage in any professional Server/HPC production workloads.
Limit your “analysis” to Epyc/SP3 SKUs compared to Xeon/Other’s professional SKUs only and do not ever bring any Threadripper/consumer SKUs into any discussions. You are never going to see the designers of Airplanes, Trains, or Automobiles, or Buildings/Bridges/Other Sturctures/Sub-Structures or devices, legally able to make use of Threadripper for any production workloads.
Do you really want to fly on an Airplane that was designed on any Threadripper/MB or other consumer grade platform that’s never been properly vetted/certified for ECC memory usage on even has the proper amount of extra ECC available/enabled for the interconnect fabric for that part of the equation.
@ThatManFromMarsIsMoreCogent,
If your observation was to me pursuant 1P TR 32C, I acknowledge / understand your certified ECC point please expand because TR 32C are commercial workstation parts are they not? Please explain the certification difference; CPU, board, ECC support and whose cert . . . I don’t disagree with your point but am at platform knowledge void here because I’m not procuring and validating in eval manufacturer claims.
What I was pointing out and in the past pointing out is that Epyc 1P parts are just 11.77% of channel availability, the point, I don’t buy AMD’s 1P volume sales claim; Epyc 1P volume in relation to 2P unless 2P boards are single populated.
For AMD to have “overwhelming 1P demand” means its not Epyc. So what is it? real or invented or something channel data does not see?
Mike Bruzzone, Camp Marketing
Oh, on Presler, Cedar Mill, Smithfield tis clarification, that’s Average Marginal Cost on 1K AWP.
Mike Bruzzone, Camp Marketing
“History never precisely repeats itself, but it does spiral around in a widening gyre.”
You are calling Intel some rough beast, aren’t you?