

Applications do not need to use all elements of a system all the time, and usually not all at the same time for that matter. And not all elements of a system need to be upgraded at the same time, either. A composable system architecture, which seeks to smash the server and put it back together again with interconnects and software and which a number of system makers are working on right now, aims to solve these problems. But you don’t have to wait for the CCIX, Gen-Z, and OpenCAPI protocols to all get rectified to get going. You can start building somewhat composable systems today with PCI-Express switching.
We are enthusiastic about the kind of asymmetric processing that is happening in the industry as we move away from a single Xeon substrate in the datacenter – with a mix of CPUs, GPUs, FPGAs, and in some cases even custom ASICs, as well as various levels of non-volatile storage all linking into the core compute complex all being woven together in interesting ways to more tightly tune the hardware to the needs of the software, rather than the other way around. To get the most efficiency out of a system, the hardware and the software have to be co-designed together, and this is commonly done by hyperscalers, cloud builders, and HPC centers. (You could argue that HPC customers have been doing this for a very, very long time.)
Here’s the problem, though. Conditions change, applications change, workloads come and go, and core components on a hybrid system are upgraded on different cycles. While main memory and processors of various kinds – CPUs, GPUs, and FPGAs – are still tightly coupled and probably will be for some time yet to come, all of the other elements in a system can be configured using a switch fabric based on the PCI-Express protocol that has traditionally been used as a point-to-point interconnect between CPUs and peripheral devices. This is possible thanks to the advent of sophisticated PCI-Express switching, and with the latest updates to these switches they include features for dynamic device sharing across multiple hosts at the hardware level.
This will be a boon to system architects that want to create pools of shared resources and compose them to servers on the fly. And the same PCI-Express fabric can be used to hook multiple and incompatible processors together, too. That’s not something you can do with traditional NUMA clustering within a given chip architecture and inside a single system. And there are plenty of companies – particularly in the financial services industry – that are doing the latter already, Herman Paraison, vice president of sales and marketing at Dolphin Interconnect, a supplier of a PCI-Express switched fabric and the software stack that makes this possible, tells The Next Platform.
Dolphin is a spinoff of research on coherent computing that was done at the University of Oslo and at Norsk Data, a minicomputer maker, in Norway back in the 1980s. (NumaScale, which we have written about before, is another spinout that used to make use of Dolphin chips in earlier NUMA scale-up chipsets and server adapters, but has long since developed its own NUMA chips for Opteron and Xeon processors.) Dolphin was founded thirty years ago and was instrumental in creating a point to point interconnect for system components called the Scalable Coherent Interface, and to a certain way of looking at it, the interconnects on a typical system-on-chip design today look, conceptually, a lot like SCI writ small. Starting in 2006, with the acquisition of StarGen, Dolphin moved to a PCI-Express fabric as the transport layer and hasn’t looked back since. The Dolphin fabric software can run on PCI-Express switches from Integrated Device Technology, Broadcom (through its PLX Technology subsidiary), and now Microsemi, a relatively new player that is now part of ASIC maker Microchip, which specializes in industrial and defense systems, after being acquired last May.
Dolphin has been swimming along with the PCI-Express roadmap as adapter and switch ASICs become available. Six years ago, the company rolled out PCI-Express 3.0 switches based on IDT chips and last year it announced a switch based on a recent Microsemi chip; Dolphin has adopted the Switchtec PFX family of fanout switch chips, and is evaluating how it might use the PSX storage family, according to Paraison. For whatever reason, Dolphin has not chosen the “Capella 2” family of PEX chips for its switches, which have the scalability and performance of the Microsemi devices it has chosen. The company has opted for IDT and PLX chips for adapters in the past decade, has similarly brought in Microsemi for a PCI-Express 3.0 two years ago and will be rolling out its first PCI-Express 4.0 adapter this year based on Microsemi chips.
The IXS600 and MXS824 switches that Dolphin makes have very different capabilities, as you can see below:

The IXS600 has eight ports with a 200 nanosecond port-to-port hop latency and supports up to 64 GT/sec per port; it supports PCI-Express x8 (eight lanes) per port and obviously has 64 lanes in total across the chip. The MXS824 has a total of 96 lanes and with four lanes per port (x4) it can drive 24 ports. The Microsemi device only has 768 GT/sec of aggregate bandwidth across the chip, and it gears down to 32 GT/sec per port across a single cable. If you need more bandwidth on a link, you can gang up the ports to create virtual x8 and virtual x16 ports. The port-to-port hop latency on the MXS824 is 170 nanoseconds, a little better than what the IDT chip offers and a little bit lower than what Broadcom says it can deliver with the PEX family at 150 nanoseconds for the same 96 lanes of PCI-Express 3.0 capacity.
The interesting bit with the Microsemi switches is that they have features that allow for the cascading of switches to create tree and mesh topologies that allow for up to 64 or 128 devices to be linked together over the switch. These can be CPUs, GPUs, or FPGAs. At the moment, the Dolphin software stack that creates the PCI-Express fabric can support Intel Xeon and AMD Epyc hosts as well as systems based on Arm processors; the company is working on support for IBM’s Power chips.
What is also interesting when it comes to PCI-Express switching is that clusters of iron are no longer limited by the length of copper cables, which was true a number of years ago. Dolphin is able to support only copper iPass cables on the IXS600 switch, which are two meters in length maximum, but the MXS824 switch can use five meter copper cables or 100 meter optical cables. With those fiber links and the cascading of switches, the PCI-Express switch fabric can span a row in the datacenter instead of being limited to maybe two or three racks.
These capabilities are going to broaden the appeal of PCI-Express fabrics to new markets, says Paraison. Here are the target workloads:
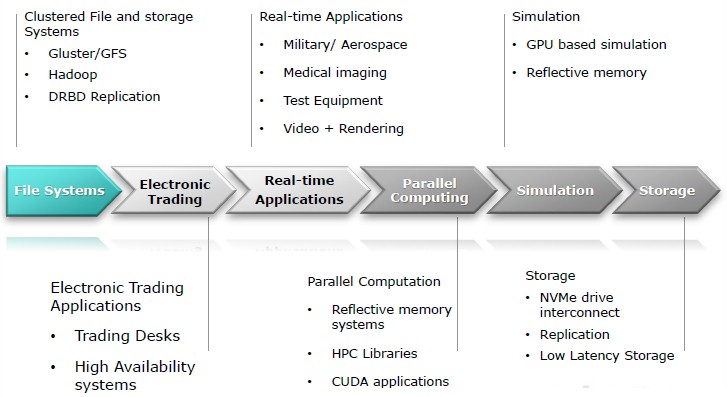
It is important to remember that Dolphin is not doing NUMA shared memory clustering with the PCI-Express fabric. Dolphin is leaving that part of the market to its sibling, NumaScale.
One of the big uses for the PCI-Express fabric is what is called reflective memory, which is another term for high speed multicasting of data from one system to another. This is a common workflow in the financial services sector, where a data feed received by one system has to be pushed to other systems very fast and usually parsed out and pushed out in different ways to other systems. In this case, the PCI-Express switch houses the multicast groups and handles the parsing in an offload model. This multicasting is used in military and defense applications, where data has to be processed by different elements of the system. In the past, says Paraison, multicast systems used a ring topology, where each node passed on the data to the adjacent one after it received it, which as you might imagine adds a lot to the latency in the nodes at the end of the loop.
A Borrower And A Lender Be
“What we are providing is a low latency, deterministic interconnect based on PCI-Express that can solve a lot of different problems,” Paraison explains. “One of the newest things we are doing is called device lending, which we are calling Smart I/O. With device lending, you have some systems with GPUs, in others you have NVM-Express drives, and maybe on others you have an Intel network interface with SR-IOV virtual networking support. With device lending, you can treat those PCI-Express devices as a pool of resources, and you can make them available to any node in the PCI-Express cluster and to any node, it will look, to the operating system and to the firmware, like those devices are installed locally in that node.”

Dolphin has been working for the past two years to have its eXpressWare software stack, which is blocked out above, ready for this day. The latest 5.10 release is the one that supports the device lending, and you will need one of the Microsemi-based switches as well if you want to scale beyond five hosts in a ring topology to do lending; the current top-end scale for device lending is for 128 hosts. Device lending can be done without any patches to the Linux kernel and without any changes to the application, and it is also possible to hot plug PCI-Express devices. (To be more accurate, to lend a device is to dynamically hot plug it over the PCI-Express fabric.)
Dolphin contends that there is little performance degradation with PCI-Express devices that are loaned out over the switch compared to having them plug directly into a system. But realistically, there has to be some difference because of the port to port hop on the switch and possibly the extra latency in a short copper or long fiber cable that links the servers hosting all of the PCI-Express devices and the PCI-Express switches. (The Dolphin presentations say that remote PCI-Express transport “adds less than 500 nanoseconds” of latency.) Regardless of that, it looks like this device lending is a heck of a lot faster than using GPUDirect over the RDMA protocol at the heart of InfiniBand, as you can see below in this device-to-host memory transfer test:

The benchmark above was done with a pair of two-socket Xeon server equipped with Nvidia Quadro P400 GPUs based on the “Pascal” architecture. The servers used in the test were linked to each other using the PXH830 adapter card, which is a PCI-Express 3.0 adapter card that dates from 2016; presumably they were linked in a peer-to-peer manner and not using a PCI-Express switch, since none was mentioned. The GPUDirect RDMA benchmark was routed over the PCI-Express adapters using the Non-Transparent Bridging and DMA features of the cards.
It goes without saying – but we will say it anyway – that anyone looking at any new interconnect for any purpose would be wise to have a benchmarking bakeoff and test some real applications in their own shops. This is particularly true as the depth of the network goes up and there are more hops between devices on the borrowing and lending hosts.
Testing this out is not as expensive as it might seem. One of the Dolphin PCI-Express adapter cards runs around $1,200, including the license to the eXpressWare software, and a high-end PCI-Express switch costs around $7,500. The eXpressWare software can be licensed separately on a per node basis if you want to run it on other PCI-Express gear.

Like A Drumbeat, Broadcom Doubles Ethernet Bandwidth With “Tomahawk 5”
If there is anything that hyperscalers and cloud builders value more than anything else, it is regularity and predictability. They have enough uncertainties to manage when it comes to customer demand that they like for their systems to behave as deterministically as possible and they like a steady drumbeat of …
With VMware, Broadcom Has A Real Enterprise Software Stack
Once Dell spun out VMware on Wall Street, it was only a matter of time before someone would put together enough money to acquire it. A year ago, we mused about Intel being the logical buyer of VMware once Pat Gelsinger left the top job at VMware to return to …
What If Omni-Path Morphs Into The Best Ultra Ethernet?
UPDATED: Nvidia is a member of the Ultra Ethernet Consortium. The jury is still out on a lot of things about this exploding AI market and the re-convergence that it will have with traditional HPC systems for running simulations and models. But one of the ideas that a lot of …
prolixity is not a virtue
So upcoming (Q2 2019 ?) Zen2 CPUs will have 128 PCIe 4.0 lanes – and those switches have 64-96 PCIe 3.0 lanes? That seems like nowhere near enough.
True. But then again, Rome Epyc isn’t here yet, and the PCI-Express switch vendors will catch up. I agree with you that every lane is sacred.
technically, i don’t see the reason to go after PCIe .vs. Ethernet at PHY level. Above PHY/SerDes level, it is mostly who gets developers and communities motivated enough to back the idea up. Hyperscalers could bring something like that in life but I cannot think of anyone potentially interested in deploying PCIe switches.