

How different the datacenter would look if symmetric multiprocessing could somehow magically scale well beyond 32, 64, or 128 processors. And it would even be a vast improvement if NUMA scaling worked well over hundreds or even thousands of sockets. The programming models would have been easier because the management of coherency across processing elements and their related memories would have been embedded in hardware and largely masked from programmers. Instead of a cluster of discrete servers, everyone would be using something that looked, for all intents and purposes, like a giant workstation with hundreds, thousands, and maybe even tens of thousands of threads.
But, SMP doesn’t scale well and NUMA has been relatively expensive, so much so that both the hyperscalers and HPC shops invented alternative methods of parallelizing their applications and distributing them across clustered network servers, and this begat Message Passing Interface (MPI) in the HPC world and Hadoop in the hyperscale world.
Standard Xeon servers use NUMA clustering to have two, four, or eight sockets. The Xeon E5s top out at four sockets using E5-4600 processors (the details of the “Haswell” family of these E5-4600 chips are here), while the Xeon E7s can do four or eight sockets (the details of the new Haswell Xeon E7s are there). No one talks about AMD Opteron processors much these days any more, but they come in two-socket and four-socket versions and someday, AMD might even talk a bit more about how its Zen chips will help revive its server business and spill some details on its HPC and enterprise roadmap. (It sure didn’t happen with executives at the ISC15 supercomputing conference in Germany this week, but there is apparently a roadmap.) On the ARM server front, Cavium Networks has two-way NUMA for its ThunderX processor, and it seems likely that the Broadcom “Vulcan” and Qualcomm “Kyro” chips will also have NUMA to extend beyond one socket. But for many workloads, this scalability is not enough.
There has been a lot of talk recently about NUMA scaling to create large shared memory systems, with Dell inking a deal with SGI to resell its UltraViolet line of shared memory systems to customers wanting to run large implementations of SAP’s HANA in-memory database, and SGI just revamping the UV 300 line and launching the high-end UV 3000 line a bit ahead of schedule. The UV 300s are based on Intel Xeon E7s and have a fast NUMALink 7 interconnect that makes them look, more or less, like a big SMP server up to 32 sockets, while the UV 3000s are based on the NUMALink 6 interconnect and scale up to 256 sockets and, because of NUMA, are a little bit more tricky to scale but it can and is done. Hewlett-Packard is also chasing HANA and other workloads that benefit from having a single memory space to roam in with its Superdome X machines, which are based on Intel’s Xeon E7 processors and which top out at sixteen sockets at the moment but could be extended to 32 or 64 sockets based on HP’s ability to do so with its Itanium-based Superdomes. IBM has Power8 systems that scale up to sixteen sockets, and Oracle has 32 socket designs with its Sparc M series and an architecture that can push up to 96 sockets if it wants to. And if you really want to get funky, Cray’s Urika systems with their massively multicored “ThreadStorm” processors can lash together a whopping 8,192 processors and 512 TB of main memory into a single shared memory system. That’s 1.05 million threads, a stunning and elegant thing. (Cray has a global addressing scheme for its XC series of supercomputers, but it is less tightly coupled than NUMA and not, as yet, aimed at more generic enterprise applications but for very specific – and appropriately so – simulation and modeling applications.)
NUMA Is About Value, Not Just Price
For most businesses, all of these machines mentioned above are perceived to be too exotic and too expensive. We say perceived on purpose, because we would argue that you have to do a value analysis and see what is derived from the use of such machines. Sure, clusters are cheaper, but look at the system integration and management you have to do and at the programming model that is in many ways much more difficult than that of a shared memory model. All of the vendors mentioned above would make that same argument, telling customers to really look at it before dismissing their wares from the IT budget.
There are, as it turns out, alternative ways to build NUMA machines.
ScaleMP, for instance, built a special hypervisor that glues multiple Linux server nodes together over InfiniBand or Ethernet networks and through very clever caching makes them look and perform as if they were a shared memory system based on NUMA hardware and chipsets. Last fall, ScaleMP put out its vSMP Foundation 5.5 version of its clustering software – and no, it is not lost on us that this software doesn’t actually implement SMP but rather NUMA – and this software can scale up to 128 nodes with a maximum of 32,768 cores and up to 256 TB of physical memory. The company has a freebie version of the vSMP Foundation hypervisor that can span up to eight nodes and 1 TB of shared memory to get customers to play around with it, and had licensing deals with Cray and IBM, announced in the fall of 2013, for specific clusters. ScaleMP has, like other NUMA system makers, trying to jump on the SAP HANA bandwagon, but has been quiet recently, attending an HP user conference in Germany ahead of ISC15 and reminding everyone that its relationship with IBM transferred over to Lenovo Group, which bought IBM’s System x division last October.
The other company that we are keeping an eye on is Numascale, which created a hardware-based means of extending AMD Opteron systems. Some customers don’t care that the machines that Numascale is plugging into are based on Opterons that are several years old – as long as the price is right and the performance is reasonable, it actually doesn’t matter – but others most certainly do. That’s why Numascale has been hard at work transforming its NUMA hardware and microcode so it can be used on any system, not just Opterons, Morten Toverud, CEO at the company, tells The Next Platform. The current NumaQ cards are based on a homegrown ASIC that implements the NUMA protocols, which then plugs into a PCI-Express slot on the server. The cards hook into the HyperTransport (HT) point-to-point interconnect on the Opteron processors, and like other NUMA systems based on Xeons and their similar QuickPath Interconnect (QPI), the NUMA cards have to steal an interconnect port to route traffic off the CPUs and onto the NUMA links. So you need to use a chip that was designed for higher-scale NUMA and then backstep the socket count to free up the port. That means using an Opteron 6300 series, a Xeon E5-4600, Xeon E7-4800, or Xeon E7-8800 in the X86 world, and it will mean using NUMA-capable ARM and Power chips when Numascale expands out into other server architectures as is the long term plan, according to Toverud.
To make its NumaQ server-lashing technologies more broadly available, Numascale has done two things. First, it is switching from an ASIC specifically designed to support one point-to-point interconnect to the use of FPGAs to implement its NUMA protocols and caching algorithms. In the test version of the future NumaQ cards, Numascale is using Stratix V FPGAs from Altera (soon to be acquired by Intel, if the acquisition passes regulatory muster), but will switch to the latest-greatest Arria 10 chips when its revamped product is available within a few months. (It is reasonable to expect that Numascale is trying to time its launch to the SC15 supercomputing conference in November.) By moving to an FPGA, Toverud says the company can easily update its NUMA protocols as needed, either for performance tuning or to support new processor architectures. And that means Numascale can in theory support Power, ARM, or other chips so long as they have some kind of connection port like HT or QPI that can be exploited to get inside the processing complex.
“We are keeping our minds open about the possibilities,” says Toverud. “SAP HANA could be a big opportunity for us, too, and we could do the same thing with Supermicro or Lenovo that SGI has just done with Dell.”
The other thing that Numascale has done that radically increases its odds of going more mainstream is license the QPI protocol from Intel. This means it is collaborating with Intel instead of trying to compete against it. If NUMA does indeed have a resurgence and in-memory and other kinds of analytics and simulation drive that, it would not be at all surprising to see Intel snap up Numascale – or some other system vendor that wants to keep the NumaQ interconnect all to itself. In fact, this is precisely the kind of technology that AMD might want to consider owning going forward with its Opteron and ARM aspirations in the datacenter. (Norwegian oil and gas giant Statoil, which is a big user of Numascale gear and an investor in the company along with some other venture capitalists, would no doubt love to see someone acquire the company.)
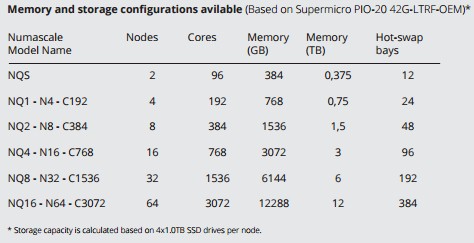
In the meantime, Numascale has been doing benchmark tests with customers and packaging up its NumaQ interconnect on Supermicro servers to pitch them as appliances for running various workloads such as R statistical analysis, Spark in-memory processing, and MonetDB columnar store. (The latter is popular in the financial services industry, while R and Spark are more generic tools.)
Like the formerly independent Revolution Analytics (which is now part of Microsoft), Numascale has done things to the open source R stats package, which Toverud says is notoriously memory hungry, to make it scale better across multiple threads, cores, and nodes – something that it intends to keep to itself as part of its value add. At the moment, Numascale is keen on configuring up R, Spark, and MonetDB appliances because, as Toverud puts it, it moves the discussion away from processors and towards the actual problem at hand.
While this is probably true, most datacenters are not actively seeking out Opterons because there is no upgrade path at the moment and there is one for Xeons, Presumably the PCI-Express 3.0 card that Numascale is developing will work in systems that use both future Opteron and current and future Xeon processors. (The Opteron 6300s, which were last updated in May 2012, only support PCI-Express 2.0 slots, and hence that is the form factor and interface of the NumaQ cards today.)
At the ISC15 show, Numascale was showing off a four-node cluster supporting a “smart cities” real-time management system, which had four Supermicro nodes, multiple terabytes of memory shared across them, and a Linux stack, which costs around $110,000 including the NumaQ hardware and software.
The scalability limits in the table shown above are not the absolute limits of the NumaQ architecture. In theory, the NumaQ 3D torus interconnect can link together up to 4,096 server nodes and 256 TB of main memory. (The node ID in the NumaQ architecture is 12 bits and the node physical address space is 48 bits, matching the physical addressing on both Opteron and Xeon processors today. These numbers are what determine the theoretical scalability of the NumaQ setup.) Numascale has not built such a large machine as yet – we presume the ones in use inside of Statoil are large, but the oil giant has always declined to be specific about its use of the Numascale products – but has machines in the field with between 600 and 700 cores at the top-end, according to Toverud.
Interestingly, a large North American energy company, who wants to be anonymous for now, will be using the very largest system that Numascale has built to date to take in telemetry data from remote power meters and mix it with historical data from its customers and its grid to do in-memory analytics in real-time on that collection of data. The precise application was not described, but ultimately the machine that will be used will have 108 of those Supermicro nodes and a total of 5,184 cores and 20.7 TB of shared memory across those nodes. To help Numascale make its marketing and technical pitch, this new customer helped Numascale run the STREAM memory bandwidth benchmark popular in supercomputing circles and the go-to test for memory bandwidth for all processors for many years now, on a subset of the iron. Here is how the machine stacked up against other NUMA iron in the STREAM test:
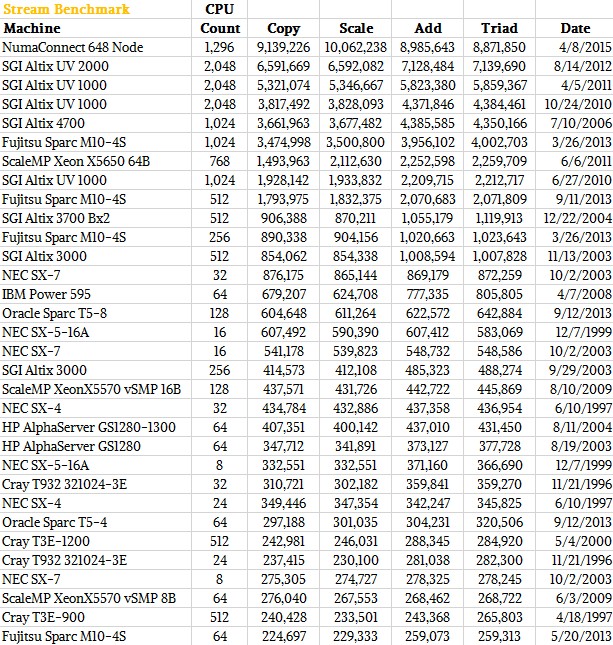
In the table above, the data is expressed in MB/sec of memory bandwidth performing copy operations or copy operations with some mathematical function also included.
The subset of the big NUMA machine being installed at the power company, which is shown in the image at the top of this story being fired up, had 108 nodes and a total of 1,296 cores and it was able to push between 8.8 TB/sec and 10 TB/sec, depending on the test, which significantly bested a UV 2000 system from SGI with more cores that was tested nearly three years ago and was the top dog for that time. The math is a bit tricky here, because that STREAM test says that the machine had 648 nodes, which is obviously a lot more than 108. Here’s what Numascale did. They took the full machine at the company, which is based on Supermicro servers with three (not four, not two) Opteron 6386 processors, which have 16 cores each, in each physical node. Then all but four cores per chip were de-allocated, providing a memory controller that would directly feed each core on the Opteron chip. There are a total of 324 active sockets on the system and 1,296 cores. I do not understand why the STREAM people think this is a 648 node system, but clearly a pair of cores and a pair of memory controllers are being treated as a node. The core count and memory count is what matters. Each server has 192 GB of memory, and across 108 physical nodes, that is your 20.7TB of memory. (It looks like what AMD might need to do is have lots more memory controllers and fewer cores on a die with future Opterons if it wants a competitive edge. . . .)
The interesting bits in the table above are the data for ScaleMP servers and then other hardware-based NUMA machines (from SGI and others). This is not a complete list by any means, but just the top 35 systems that have been tested. Some very old Cray and NEC supercomputers still make it to the top of the list, which shows just how far they were ahead of their time in understanding the importance of memory bandwidth for application performance for certain parallel workloads.
Hopefully, as Numascale brings its Xeon-compatible products to market, it can help drive down the cost of NUMA clustering and make it more widely available. Others have tried and have had a tough time of it. But there may be enough of a need today for more in-memory processing and simpler programming models that the idea finally takes root.




“I do not understand why the STREAM people think this is a 648 node system”
Opteron 63xx contain 2 NUMA nodes per socket. So I guess “using 4 cores per socket” actually means they’re using 2 cores per NUMA node for both NUMA nodes in each socket.
But of course. I forgot that their four-socket was really an eight-socket.
Of the HPCC benchmarks, STREAM seems to be the most completely devoid of useful information in this case. Far more interesting would be the global transpose or random access benchmarks. Those actually use the interconnect between processors.