
There is much value in separating storage from compute, particular for cloud database deployments. To this end, Alibaba has targeted low latency and high availability with a newly developed distributed file system called PolarFS, which pairs with its own PolarDB database service on its cloud.
Cloud database services like PolarDB (or those found on any major cloud provider’s platform for that matter) can take advantage of this decoupling of storage and compute resources by having a more scalable and secure foundation to take advantage of containers and having support for backend storage clusters with fast I/O, checkpointing, and data sharing.
With all the innovation happening in cloud I/O for database services, however, it can be hard to integrate hardware advances that speed read and writes significantly, including RDMA and NVMe, for instance. Here the Alibaba architecture is noteworthy from a performance standpoint because it leverages recent innovations in RDMA, NVMe, and SPDK, which produces write performance on par with the local file system on an SSD.
“PolarFS adopts emerging hardware and state-of-the-art optimization techniques, such as OS-bypass and zero-copy, allowing it to have the latency comparable to a local file system on SSD. To meet the high IOPS requirements of database applications, we develop a new consensus protocol, ParallelRaft. ParallelRaft relaxes Raft’s strictly sequential order of write without sacrificing the consistency of storage semantics, which improves the performance of parallel writes of PolarFS. Under heavy loads, our approach can halve average latency and double system bandwidth. PolarFS implements POSIX-like interfaces in user space, which enables POLARDB to achieve performance improvement with minor modifications.”
It might sound obvious for cloud vendors with database services to offer the latest in hardware tweaks for high performance but getting there is not as simple as it sounds. As the Alibaba researchers explain cloud providers use an instance store as the basis of their services with a local SSD and high I/O virtual machine instance for databases. But this approach limits capacity, especially with scale.
Further, reliability is reduced since databases are left to handle replication on their own. Finally, instance stores use general purpose file systems at their core and when trying to implement RDMA or PCIe-based SSDs to boost performance, the message passing cost between kernel and user space comes with serious overhead.
Alibaba used to have the above limitations with its own PolarDB service. Now, PolarFS is primed to take advantage of new I/O boosts including RDMA and NVMe SSDs with a lightweight network stack and I/O stack in user space to avoid being locked in kernel. The PolarFS API is POSIX-like in that it can be compiled into the database process and can replace the file system interfaces provided by the OS that the while I/O path can be kept in user space.
The Alibaba team also notes that the I/O model of PolarFS’s data plane is designed to eliminate locaks and avoid context switches on the critical data path. “All unnecessary memory copies are also eliminated while direct memory accesses are used to transfer data between main memory and RDMA NIC/NVMe disks.” It is here in particular where the latency is reduced quite dramatically.
Alibaba also had to develop with reliability in mind. At the core of their tweaks is the Raft protocol for solving consensus. “Distributed file systems deployed in the cloud production environment typically have thousands of machines. Within such a scale, failures caused by hardware or software bugs are common. Therefore, a consensus protocol is needed to ensure that all committed modifications will not get lost in corner cases, and replicas can always reach agreement and become bitwise identical.” To build with this in mind Alibaba created ParallelRaft to distribute this function at scale.
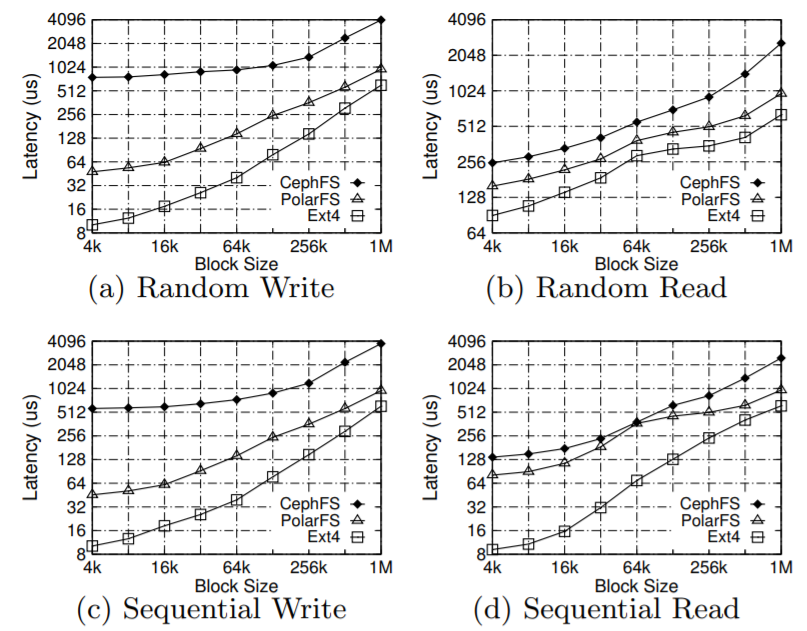
The full discussion of performance results and tuning can be found in this detailed paper.


The GPU Database Evolves Into An Analytics Platform
As the name of this publication suggests, we are system thinkers and we like to watch the evolution of a collection of tools into a platform. That’s the neat bit, when all the propellerheads have done the work on the components and the integration and when those tools can be …

The Cloud Outgrows Linux, And Sparks A New Operating System
Ultimately, every problem in the constantly evolving IT software stack becomes a database problem, which is why there are 418 different databases and datastores in the DB Engines rankings and there are really only a handful of commercially viable operating systems. But what if the operating system is the problem? …
Oracle Goes Massively Parallel, Low Cost With Exadata Exascale
Maybe, if you need blazing performance extracting data and chewing on it from a relational database, it belongs in a cloud. Because for certain workloads, including vector search and retrieval augmented generation, having a blazingly fast database – and one that can scale from terabytes to petabytes of capacity – …
Be the first to comment