

Artificial intelligence and machine learning, which found solid footing among the hyperscalers and is now expanding into the HPC community, are at the top of the list of new technologies that enterprises want to embrace for all kinds of reasons. But it all boils down to the same problem: Sorting through the increasing amounts of data coming into their environments and finding patterns that will help them to run their businesses more efficiently, to make better businesses decisions, and ultimately to make more money.
Enterprises are increasingly experimenting with the various frameworks and tools that are on the market and available as open source software, in both small scale experiments run by a growing number of data scientists who have the expertise to find the valuable information the growing lakes of data and in full blown production deployments that are, conceptually, every bit as sophisticated as what the hyperscalers are deploying.
The top cloud service providers and hyperscalers have for several years embrace data-driven AI and machine learning techniques and built their own internal frameworks and platforms that enable them to quickly take advantage of them. But as the technologies begin to cascade into more mainstream enterprises, the complexity of software and systems are throwing roadblocks in front of initiatives aimed at leveraging AI and machine learning for the good of the business. There are myriad frameworks on the market that enterprises can take advantage of, from TensorFlow, Shogun and Theano libraries and Torch and Caffe frameworks to the Apache Singa and Vele platforms. The problem is that many enterprises don’t have the time or resources to pull all that together themselves to create enterprise-grade, easy-to-use systems, according to Nima Negahban, co-founder and chief technology officer of Kinetica, one of the major suppliers of GPU-accelerated relational databases.
What is happening now is that data scientists at many of these enterprises are spending so much time pulling together the systems themselves – configuring and managing the databases and data management systems – that they’re aren’t doing what their jobs demand, which is coding and building algorithms that will enable their businesses to take advantage of AI and machine learning. What they are looking for are commercial platforms that automate and operationalize the processes around AI that take much of the grunt work out of building the systems out of their hands.
“You’ve got this real kind of challenge to try to bring valued-added data and leverage ML to operate more efficiently as a business and you don’t have the operational toolset on the operational side to actually support this,” Negahban tells The Next Platform. “What you’re seeing right now is this impediment causing this structural mismatch of capabilities deployment from an employee standpoint.”
Vendors are beginning to see an opportunity to help these businesses overcome the impediments, and “the data side is really excited,” says Negahban. “They’re starting to see where they can put this in a mission-critical way, and you’ve got a real need to make this something where you’re not forcing mathematicians to do process supervision, you’re not forcing mathematicians to deploy microservices. There’s a real opportunity here in the enterprise space to be that provider, and there’s leaders in the ML space already answering the call for that in their own enterprises.”
Negahban pointed to Uber’s Michelangelo machine learning-as-a-service platform as an example. The ride-sharing company built this platform that solved their issues, where a lot of the repeated patterns of building out an ML pipeline are systematized and done in a way that it could leverage system engineers for the operational infrastructure and let data scientists actually focus on the data science.
“What I mean by operational is that within a unified platform, you’re able to do data cleansing, intergeneration model training, model evaluation and model deployment and audit,” Negahban explains. “Now your data science team doesn’t have to worry about the service model going down or the TensorFlow serving process doesn’t go down. They can focus on the data science and when they’re ready to deploy it, they get a microservice definition that they give out to the other application developers, and I know that every score is tracked and I can do an audit and I can chop up everything that occurs with that particular instance of the model, I can compare it to other models, and I know that is the most efficient use of my data science team’s time and the best use of my whole entire enterprise’s time because I know the things that are being deployed and being used are being managed in an operational context, rather than what happens now, where you have folks who just come in and run scripts because that’s how they’re trained. They just run a Python script and run a bunch of scores and seed those scores out, or they have in mind scoring operational systems that don’t have any kind of process supervision or resiliency or disaster recovery.”
For most of its existence, Kinetica has focused on companies in the online analytical processing (OLAP) and geospatial spaces. The underlying technology grew out of work Negahban and KInetica co-founder and chief strategy officer Amit Vij did for the Department of Defense in building a database using GPUs to help track national security threats. The company rebranded itself as Kinetica in 2015 and has raised $63 million in funding, including $50 million during one round in June. About 18 months ago, Kinetica, which now has 75 employees and counts the US Postal Service, PG&E, and GlaxoSmithKline among its customers, began hearing from data scientists at enterprises who wanted to run their work on Kinetica’s technology, Negahban said. The data scientists wanted to leverage the data processing and GPU capabilities, so Kinetica built an API and framework to enable these people to plug into its eponymous database.
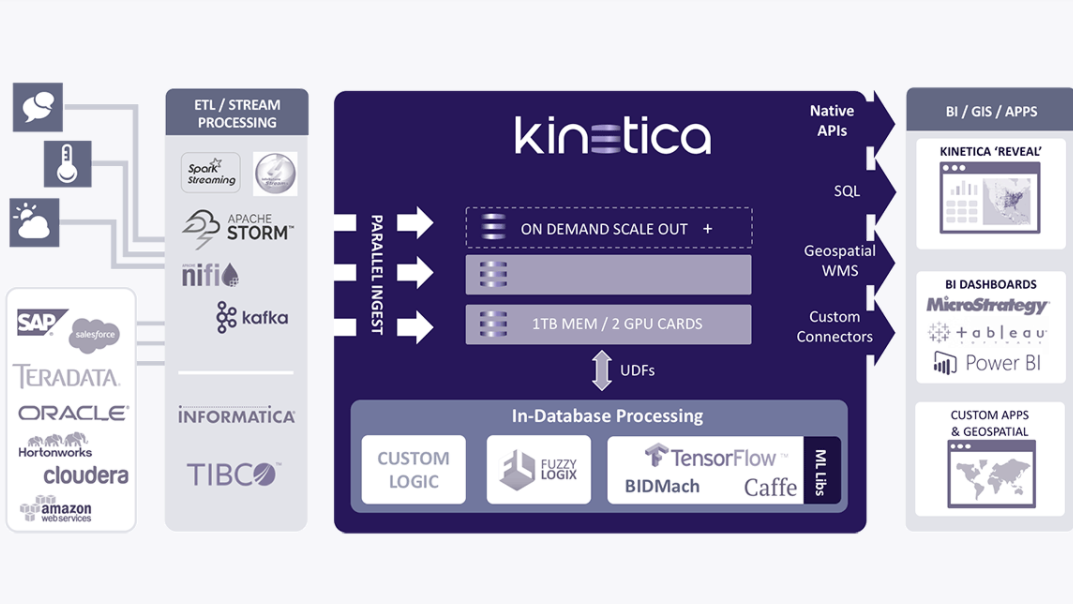
While sitting in meetings with enterprises, Negahban says he saw that in some companies, the data science team was secluded from the data and other operational teams, both organizationally and from an infrastructure perspective.
“We were coming into some places and the data sciences guys had just something like some towers under their desk, and when they wanted training, they would send some emails to their data warehouse teams and they were getting these static dumps and doing that work and iterating in this very slow, non-converged way,” he explains. “To me, that was a huge opportunity. That was one flag. Then we started working with teams that did have successful pipelines built out and had built out successful models of flow back and forth between the data warehouse teams and themselves. But once they did that, then they got parts of their enterprise excited and they wanted to go into production, but they were the ones being tasked with that work. Again, it was this big systems engineering work that was being onloaded onto data scientists, and that’s not really their primary skill set.”
It was a pattern Kinetica saw being repeated at many enterprises. At the same time, Kinetica realized the growing value of machine learning in the enterprise from a business perspective.
“It’s an outgrowth of the Hadoop/big data movement where, finally, you did have all this data and there is a demand to create ROI off this data, so businesses are asking, ‘OK, what can ML do? What insights can ML provide to my business and how can I integrate it into the actual operation stance of my business?’ You’ve got this sort of aha moment in the enterprise without the operational understanding how to make this a reality. That’s where we are today.”
Kinetica is one of a number of vendors, such as MapD and Domino Data Lab, that are looking to build the data science platforms that enterprises can use to grow their use of AI and machine learning. Other vendors like IBM also are pushing to make AI easier for enterprises to use. Negahban says a key differentiator for Kinetica are the Nvidia GPUs they leverage in their operational database engine and the company is putting more focus on AI and machine learning capabilities into the upcoming version 7.0 of its product. As enterprises get more comfortable with the idea of leveraging AI and machine learning, demand for automated platforms will grow, fueled in part by the widespread development and availability of open-source tools. It will also cascade down to mid-tier and smaller enterprises.
“If you think about your Googles and your Facebooks and your Ubers, they’ve all created operational systems internally that solve this issue for them,” Negahban says. “What you’re seeing now is, going down a line, your Fortune 500s understand the need for ML in their day-to-day operations and the efficiencies that brings, but they don’t want to necessarily spend the time or they have not yet identified this as a huge, repeated operational inefficiency.”
But, as it turns out, a lot of them do.
“We saw that a year and a half ago,” continues Negahban, “where there is this desire to give some basic operational context around this stuff. If you look at where ML was fifteen or even ten or five years ago, a lot of the open source frameworks out there and a lot of where people spend their time on was building out these computational or primitive algorithms that are now well-defined, robust and given out for free. I keep going back to TensorFlow, but TensorFlow and] the Anaconda kind of ecosystem of different Python libraries, these are all out there now and they’re getting better and better, and there are more and more programmers out there who know how to leverage them. What that does is kind of brings down the bar lower on the math side, where you don’t really have to know about the innards of the machinery, you can just understand how it fits into a broader ensemble that you’re trying to build. As that barrier of entry from the mathematical and the library perspective is brought way, way down, it’s opening it up to thinking about ML and how they can use it from a development standpoint. Ten years ago, if you were building an ML pipeline you’d have to get really deep into math and understand what’s going on and sometimes have to build out your own computational or algorithmic primitive. Now that’s taken care of.”


A GPU Upgrade For “Leonardo” Supercomputer But Not A Budget Upgrade
Neither scientific progress nor the budgetary process can wait for compute engine and interconnect roadmaps. At some point, an HPC center is at a cadence for upgrading its supercomputers that is difficult to change, and you get the best supercomputer you can get at any time and you try not …

UALink Fires First GPU Interconnect Salvo At Nvidia NVSwitch
Compute engine makers can do all they want to bring the performance of their devices on par or even reasonably close to that of Nvidia’s various GPU accelerators, but until they have something akin to the NVLink and NVSwitch memory fabric that Nvidia uses to leverage the performance of many …

GPU-Armed Scientists Solve A Quantum Annealing Debate
There is a seemingly endless list of problems to be solved and issues to be addressed in vendors’ steady march toward quantum computing. Researchers in Europe say they recently solved a “decades-old controversy” and used GPU-laden supercomputers running simulations to do it. In the research published earlier this month in …
Be the first to comment