

There is no real middle ground when it comes to TensorFlow use cases. Most implementations take place either in a single node or at the drastic Google-scale, with few scalability stories in between.
This is starting to change, however, as more users find an increasing array of open source tools based on MPI and other approaches to hop to multi-GPU scalability for training, but it still not simple to scale Google’s own framework across larger machines. Code modifications get hairy beyond single node and for the MPI uninitiated, there is a steep curve to scalable deep learning.
Although high performance computing system developments have been key enablers for the revival of large-scale machine learning, particularly in terms of GPU computing, scalability, and ultra-low latency networking, there is a gap in extending HPC system size to deep learning problems. While there have been notable efforts to this end, there are still some big hurdles, particularly that with popular frameworks like TensorFlow, codes have to be modified significantly to run across several nodes while managing the vagaries of MPI in the process.
The goal is to create an implementation that can get around this and other scalability barriers by providing a distributed memory base and incorporating all the runtime alterations directly into TensorFlow, says Pacific Northwest National Laboratory’s Abhinav Vishu. His team at PNNL has created just such an implementation—one that uses MPI as the backbone while abstracting all the messy code changing required for deep learning analysts and HPC system operators that want to integrate TensorFlow into existing HPC workflows or sites or in other large-scale datacenters.
The team’s implementation is called the Machine Learning Toolkit for Extreme Scale (MaTEx) and is available via GitHub. Vishnu says that their initial presentations have drawn interest from other scientific computing centers, including NERSC, and they have presented the concept to IBM and Mellanox, among others.
“We have observed that, due to pre-existing, complex scripts, the distributed memory implementations available are inadequate for most deep learning uses. Hence, it is important to consider implementations that would provide distributed memory deep learning while abstracting the changes from the users completely.”
“On the backend, the nodes are working together via MPI. Each node has one or multiple neural network models that replicate across nodes, but with such large datasets, each node just gets a part of that and has a copy of the model. Each of the nodes trains in batch on that model and everything synchronizes on that model to bring it all together,” Vishnu explains. This all-reduce method is not unfamiliar in concept, but the key difference is the abstraction. “We redefine new user level operations that are automatically executed when a TensorFlow graph is executed. That graph executes on layers of the network and we auto-insert our user operations into this graph so the synchronization happens but is hidden from the user.”
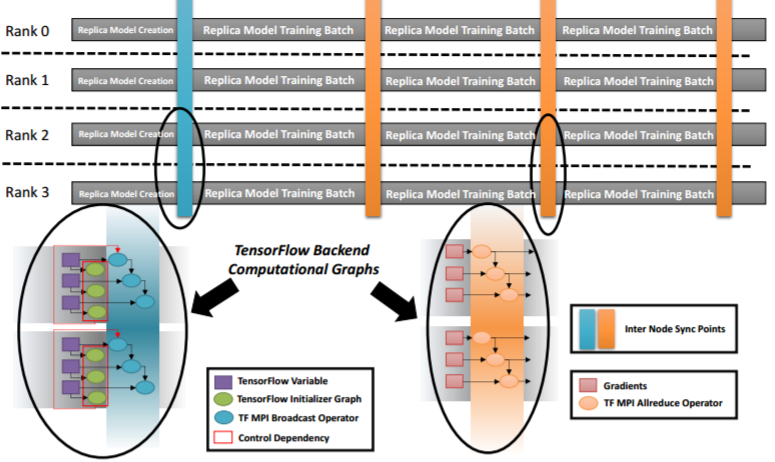
This is certainly not the only MPI-oriented platform for scaling deep learning on HPC clusters, although many other initial efforts have focused on Caffe and those that haven’t have overlooked the extensive code modifications required to scale. Google has its own distributed TensorFlow package (gRPC) but Vishnu says this is optimized toward cloud-based systems with standard Ethernet and is not robust enough to hum on HPC systems with Infiniband, custom interconnects, RDMA capabilities and other features. Even those efforts at scaling TensorFlow on HPC systems from companies like Baidu, which are also MPI-based, perform well but require extensive changes to the code as it relates to MPI in existing TensorFlow scripts, Vishnu explains. What I needed
“Most data analysts aren’t HPC experts and most HPC experts don’t put forth the effort to bridge the gap between their systems and the things that use HPC machines,” Vishnu tells The Next Platform. “We wanted to bridge that gap between HPC systems and all the interest in Tensorflow—and not just for the large supercomputing sites, but also for systems that are tightly connected on platforms like Amazon Web Services and running at scale.”
The team has provided benchmark results on systems that feature Haswell CPUs and much older generation Nvidia Tesla GPUs (K40) but Vishnu says they are already working on scaling the effort to the DGX-1 appliance to take advantage of NVlink and much more capable communication. We will describe those results when they are made public later this summer.
“We observe that MaTEx TensorFlow scales well on multiple compute nodes using ImageNet datasets and AlexNet, GoogleNet, InceptionV3, and ResNet-50 neural network topologies,” Vishnu says. From a hardware perspective, the main point is that MaTEx has the ability to “leverage multi-node CPU systems and multi-node GPU implementations without modifying any source code specific to TensorFlow.” He recommends users take advantage of the data readers, which offer an interface for reading data in multiple formats.
“We’ve been looking at how this fits in several domains. We’ve talked to physicists about our code, we’ve applied this to SLAC’s particle data, and internally at PNNL, we’ve applied it to graph analysis that uses machine learning. In all of these cases, these are not HPC experts that want to worry about using HPC systems and managing memory and MPI,” Vishnu concludes.


Rethinking MPI for GPU Accelerated Supercomputers
In the accelerated era of exascale supercomputing, MPI is being pushed to its logical limits. No matter how entrenched it has become over the last two decades, it might be time to rethink programming for increasingly large, heterogenous systems. Every field has its burdens newcomers must bear and for HPC …
Is Mojo The Fortran For AI Programming, Or More?
When Jim Keller talks about compute engines, you listen. And when Keller name drops a programming language and AI runtime environment, as he did in a recent interview with us, you do a little research and you also keep an eye out for developments. The name Keller dropped was Chris …

MPI on Neuromorphic Hardware Shows Greater Promise
While there are not many neuromorphic hardware makers, those on the market (or in the research device sphere) are still looking for ways to run more mainstream workloads. The architecture is aligned with low power consumption and high computational efficiency, but mapping generalizable, high-value graph-driven problems to these devices is …
Be the first to comment