

We are heading into International Supercomputing Conference week (ISC) and as such, there are several new items of interest from the HPC side of the house.
As far as supercomputer architectures go for mid-2017, we can expect to see a lot of new machines with Intel’s Knights Landing architecture, perhaps a scattered few finally adding Nvidia K80 GPUs as an upgrade from older generation accelerators (for those who are not holding out for Volta with NVlink ala the Summit supercomputer), and of course, it all remains to be seen what happens with the Tianhe-2 and Sunway machines in China in terms of new development.
While we are not expecting any major new architectural surprise shakeups on the Top 500 list when it is announced next Monday, there is progress for some of the pre-exascale machines being installed and put into early production, including the Cori supercomputer at NERSC (more on that later today) and the Theta system at Argonne National Lab. Both of these machines sport an Intel Knights Landing (and Haswell in Cori’s case) base with the Cray Aries interconnect via the XC40 supercomputer architecture—and both are reporting early results with key applications and how they might help centers adapt to the much larger systems.
As we pointed out last week, there are some questions about the future of the Aurora supercomputer at Argonne, an Intel and Cray based system that has been expected to arrive at the lab in 2018 sporting Intel’s Knights Hill and Cray architecture. However, work has been progressing on one of the systems designed to prepare users and codes for such a scale-shift—the stepping-stone Theta supercomputer, which will introduce the lab to the Cray XC40 architecture and help users make the shift from an IBM systems focus to a completely new approach altogether—something we talked about with one of the lab’s leads when Aurora was announced.
Even though part of its purpose is to provide an on-ramp to the next-generation Intel architecture (Knights Hill) and Cray architecture after so many years as a BlueGene-centric lab, Theta is still very powerful. In terms of capability, it is very similar to Argonne’s current leadership-class supercomputer, the 10 peak petaflop Mira supercomputer—an IBM BlueGene machine at still holds steady at #9 on the Top 500 list alongside a few other IBM BlueGene systems that will be retired in the next couple of years, bringing an end to that architectural era. The Knights Landing and XC40 (Cray “Aries” network-based) combination will deliver (along peak Linpack benchmark performance lines) in 3,624 nodes what takes Mira 49,152 nodes (although the architecture differences don’t allow for true apples-to-apples compare).
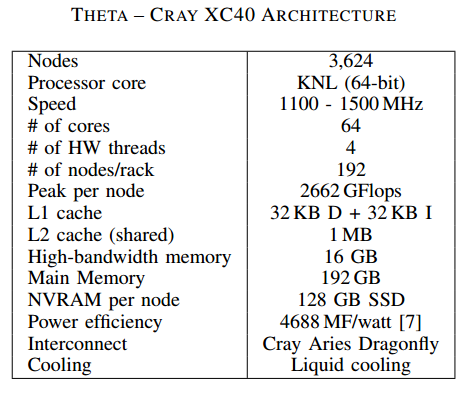 With Theta up and running now, we can presume in time for the upcoming Top 500 ranking (although some labs eschew this benchmark because of its lack of relevance to real-world HPC applications) researchers are running microbenchmarks to evaluate performance. On the list for a recent report were DGEMM for peak floating point performance metrics and for more component-centric evaluations, LAMMPS, MILC, and Nekbone were measured. If the team ran the Top 500 Linpack benchmark to obtain peak theoretical performance, we won’t know until next week.
With Theta up and running now, we can presume in time for the upcoming Top 500 ranking (although some labs eschew this benchmark because of its lack of relevance to real-world HPC applications) researchers are running microbenchmarks to evaluate performance. On the list for a recent report were DGEMM for peak floating point performance metrics and for more component-centric evaluations, LAMMPS, MILC, and Nekbone were measured. If the team ran the Top 500 Linpack benchmark to obtain peak theoretical performance, we won’t know until next week.
For DGEMM and the evaluation of the peak floating point performance of the KNL core and nodes, the team found that they were able to achieve 86% of the peak—an impressive number considering each node was expected to reach 2.25 teraflops (35.2 Gflops per core).
The research team adds that “while the KNL core has a theoretical peak throughput of 2 instructions per clock cycle), actual throughput can be limited by factors such as instruction width and power constraints.” They explain that “power measurements show better computational efficiency when using fewer hyperthreads. OS noise and the shared L2 cache contention have been identified as the sources of core to core variability on the node” but note that Cray’s core specialization can target the noise issues that have an impact on the timing of microkernels.
In terms of other trouble spots, it is actually OpenMP that introduced some of the latencies. The Barrier and Reduce construct was “found to be related to the latency of main memory access due to the lack of shared last level cache. A simple performance model was developed to quantify the overhead of OpenMP pragmas which scale as the square root of the thread count,” Argonne researchers note.
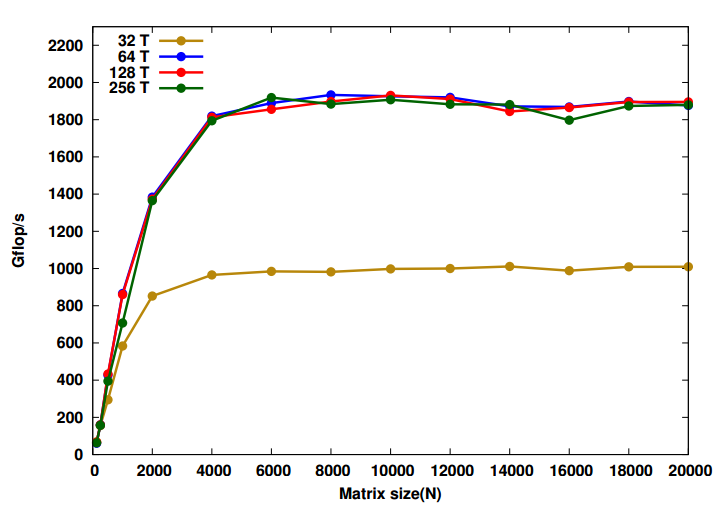
The team also ran the STREAM Triad benchmark to evaluate memory bandwidth. They found that “considerable variation was found in memory bandwidth between the flat and cache memory mode configurations.”
LAMMPS, MILC, and Nekbone all showed positive scaling characteristics (for strong and weak scaling) on Theta and were comparable to what teams were able to achieve on Mira, which is known for scalability via the BlueGene architecture. In short, so far, KNL is delivering on its promises in the wild–it will be interesting to see scaling, performance, and efficiency on real-world applications as these roll out by SC17 for Gordon Bell, for instance.
We can expect a number of stories leading into ISC around the early benchmark results and production tales from other supercomputers with similar architectures (Trinity, Cori, Stampede2, etc) and will write these up as we get them. The full benchmark results and details from Theta can be found here.


JAMSTEC Goes Hybrid On Many Vectors With Earth Simulator 4 Supercomputer
Sponsored When it comes to compute engines and network interconnects for supercomputers, there are lots of different choices available, but ultimately the nature of the applications — and how they evolve over time — will drive the technology choices that organizations make. And such is the case with the new …

Top500 Supercomputers: Who Gets The Most Out Of Peak Performance?
The most exciting thing about the Top500 rankings of supercomputers that come out each June and November is not who is on the top of the list. That’s fun and interesting, of course, but the real thing about the Top500 is the architectural lessons it gives us when we see …

Prime Contracting No Longer One Of Intel’s HPC Aspirations
Intel has spent the past nine months reorganizing itself in the wake of Pat Gelsinger becoming its chief executive officer in January, including new groups and divisions and new managers for them that were revealed in June. But the fate of its HPC organization, which has been less focused than …
Be the first to comment