

The National Energy Research Scientific Computing Center (NERSC) application performance team knows that for many users, “optimization is hard.” They’ve thought a lot about how to distill the application optimization process for users in a way that would resonate with them.
One of the analogies they use is the “Ant Farm.” Optimizing code is like continually “running a lawnmower over a lawn to find and cut-down the next tallest blade of grass,” where the blade of grass is analogous to a code bottleneck that consumes the greatest amount of runtime. One of the challenges is that each bottleneck represents a different challenge that the ants must tackle when traversing a flowchart-like ant farm. When optimizing for the Intel Xeon-Phi architecture, for example, one may need to concern themselves with any or all of the following: thread-scaling on the many light-weight cores, utilizing the on-package memory, filling large vector compute units. Knowing which of these avenues to pursue can be a challenge for NERSC users.
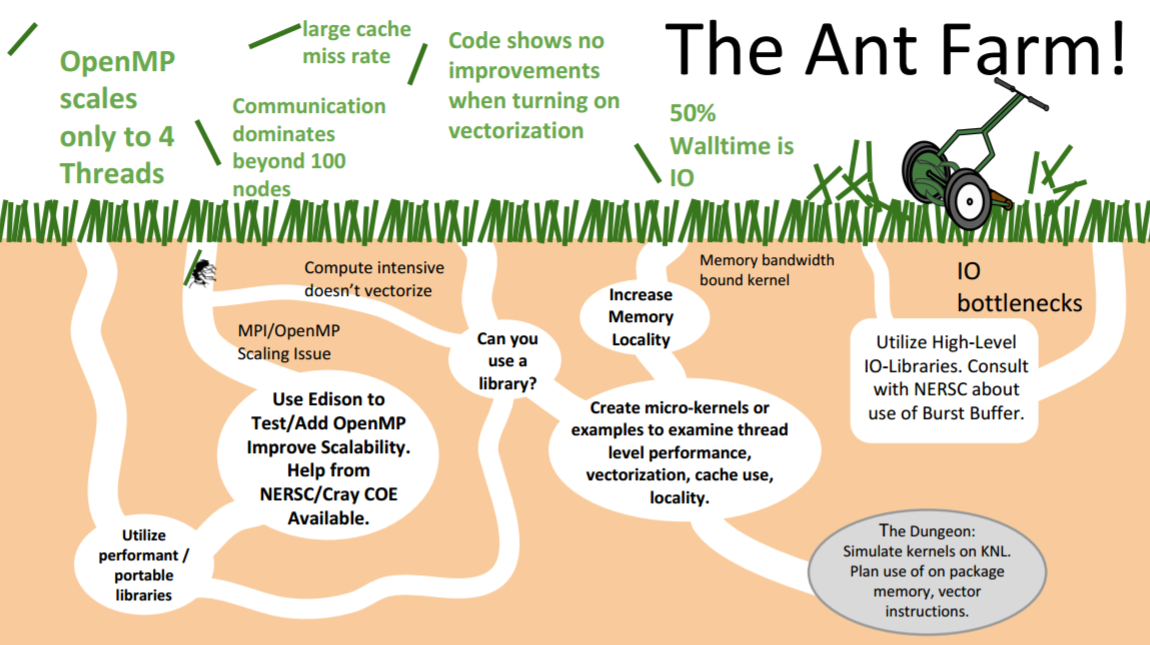
Figure 1: Optimization is like an ant hill (Image courtesy NERSC)
Optimization is hard. It is like a lawnmower that is continually running to knock down the next tallest blade of grass – NERSC
After years of working toward preparing applications for the Intel Xeon Phi processor-based Cori system, NERSC has found that using the roofline model to assist optimization efforts proven to be very successful in meeting this challenge. The roofline model was developed by Sam Williams, a computer scientist in the Computational Research Division at Lawrence Berkeley National Laboratory, which also manages NERSC.
The benefits of the roofline model have been so great that NERSC is now popularizing it through a co-design effort with Intel to include the roofline model (and advanced features) in the latest version of Intel Advisor. Early access can be found here.
The roofline model not only tells the programmer how much they are improving the code according to an absolute measure of performance (Gflop/s shown on the y-axis below), but it also tells developers which architectural features help (as shown in the arrows in the figure below). These paths show where the potential performance gains can be achieved by utilizing the wealth of architectural features of the Intel Xeon and Intel Xeon Phi processor families be it vectorization (AVX), code restructuring via Instruction Level Parallelism (ILP), focusing on the High Bandwidth memory (HBM) or conventional DDR memory and so on.
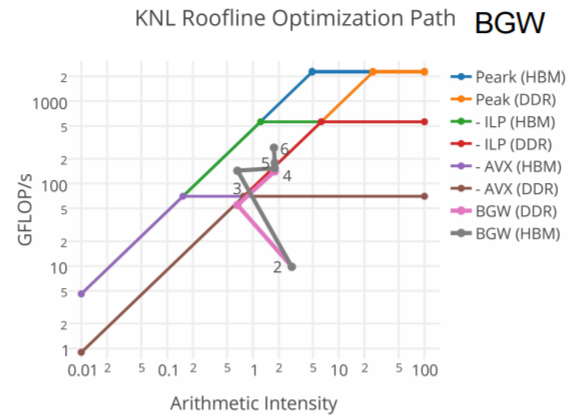
Figure 2: The roofline model is a valuable optimization tool showing both absolute performance and the path to that performance (Image courtesy NERSC)
As the primary scientific computing center for the U.S. Department of Energy’s Office of Science, NERSC supports more than 6,000 users running more than 700 applications. The overall conclusion of the NERSC work after porting a representative sample of those 700 applications is that most codes can be optimized for Intel Xeon Phi processors with the help of the roofline model to outperform Intel Xeon processors. The following graphic shows performance speedups on representative examples from the NESAP program (the NERSC Exascale Science Applications Program)—a collaborative effort where NERSC partnered with code teams and library and tools developers to prepare for the Cori many-core architecture.
Why do we need the roofline model?
The roofline model is important for two reasons, along with its ability to answer several key questions listed under the reason.
- Developers need a sense of absolute performance when optimizing applications.
- How do I know if my performance is good?
- Why am I not getting peak performance out of the platform?
- Developers need to pick the best route to faster code, given many potential optimization directions.
- How do I know which optimization to apply?
- What is the limiting factor in my application’s performance?
- How do I know when I can stop optimizing?
The classical vs. cache-aware roofline models
Most programmers intuitively or through experience know there are two peak performance ceilings. The lowest ceiling occurs when the processor runtime is dominated by physical DRAM memory (e.g., the ”classical” roofline model). The highest performance ceiling occurs when data is localized so the application can run out of fast cache memory (e.g., the “cache-aware” roofline model). The impact of L1 and L2 cache-blocking can be seen in the comparison below between these two roofline models.

Figure 3: Impact of L1 and L2 cache block on arithmetic Intensity (Image courtesy NERSC)
The following table describes the key differences between the classical vs. cache-aware roofline model. (AI is the abbreviation for Arithmetic Intensity).
| Classical Roofline Model | Cache-Aware Roofline Model |
| AI = #Flop / bytes (from DRAM) | AI = #Flop / bytes (into the CPU) |
| Bytes are measure out of a given level in memory hierarchy | Bytes are measured into the CPU from all levels in memory hierarchy |
| AI depends on problem size | AI is independent of problem size |
| AI is platform dependent | AI is independent of platform |
| Memory optimizations will change AI | AI is constant for given algorithm |
Roofline automation in Intel Advisor
The roofline process has been automated so it’s straightforward to build the roofline model for your code with the Intel Advisor. Basically the programmer computes the classical roofline model using three ingredients: 1) Number of Flop/s; (2) Number of bytes from DRAM; and 3) the computation time. The collection of the cache-aware roofline model is also automated via a set of survey scripts which can then be viewed via a nice GUI (Graphical User Interface).
Mathieu Lobet and Tuomas Kolkela provided a nice example in their Intel HPC Developer Conference Talk, Utilizing Roofline Analysis in the Intel® Advisor to Deliver Optimized Performance for Applications on Intel® Xeon Phi™ Processor. This example is from a PIC (Particle-in-Cell) code for tokamak (edge) fusion plasmas. More precisely, the XGC1 code is a magnetic fusion PIC code that uses an unstructured mesh for its Poisson solver that allows it to accurately resolve the edge plasma of a magnetic fusion device. Such devices may provide a cleaner, renewable power source in the future.
The computational bottlenecks are:
- Field interpolation to particle position in field gather that is performance limited by short trip counts and indirect grid accesses that produce gather/scatter instructions.
- An element search on an unstructured mesh that cannot vectorize due to multiple exit conditions and indirect grid accesses.
- The computation of higher-order terms in a set of equations that exhibits cache unfriendly memory accesses due to strided memory accesses across some complicated derived data types. This makes it challenging to ‘eyeball’ the code to see the computational bottleneck.
The figure below shows that a single Intel Advisor survey discovers most of these bottlenecks, which highlights the usefulness of Intel Advisor to find unknown bottlenecks. The NERSC team was careful to clarify the “most” caveat, as it reflects the need to continue improving the tool – e.g., to characterize strided memory accesses.
The Intel advisor screenshot below was annotated by the NERSC team to show the bottlenecks.
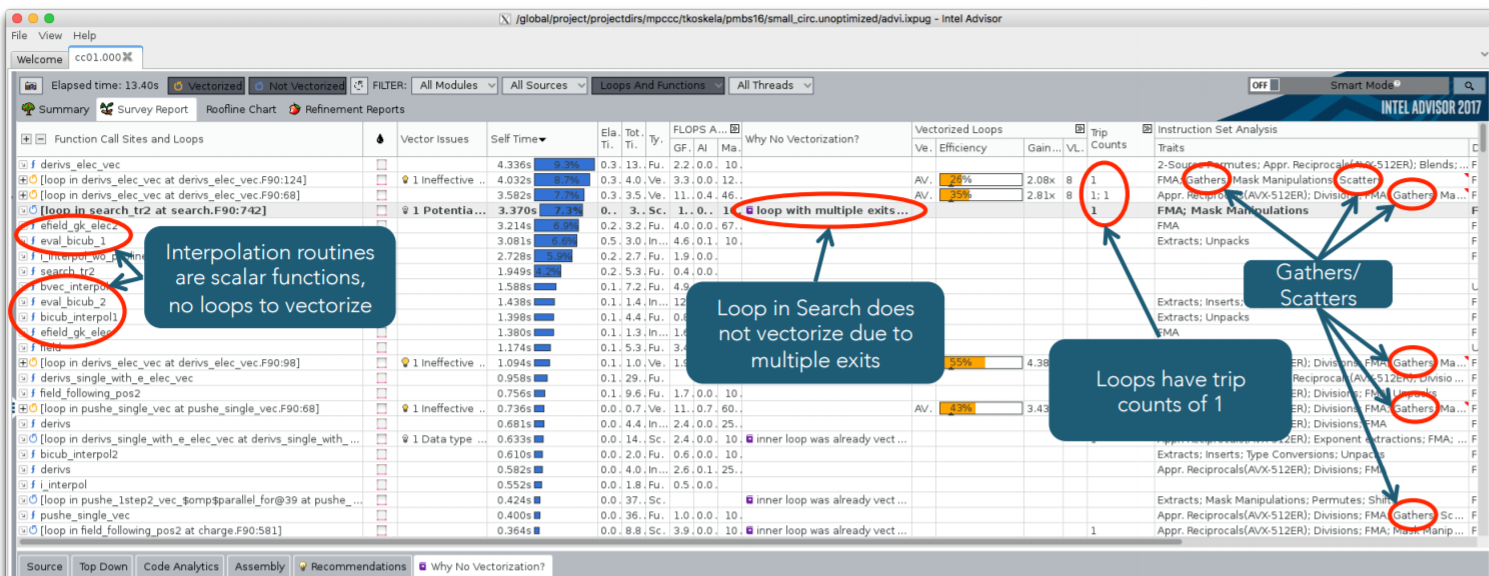
Figure 4: Annotates Intel Advisor screenshot (Image courtesy NERSC)
The XGC1 code was optimized by enabling vectorization, restructuring some data structures, and providing some simple algorithmic improvements (e.g., reducing the number of calls to the search routine and sorting the particles by the element index instead of local coordinates).
The colored dots show the optimization path on the classical roofline model as various optimizations were performed. The result is an approximate 2x performance improvement due to vectorization and memory layout changes on an Intel Xeon Phi.
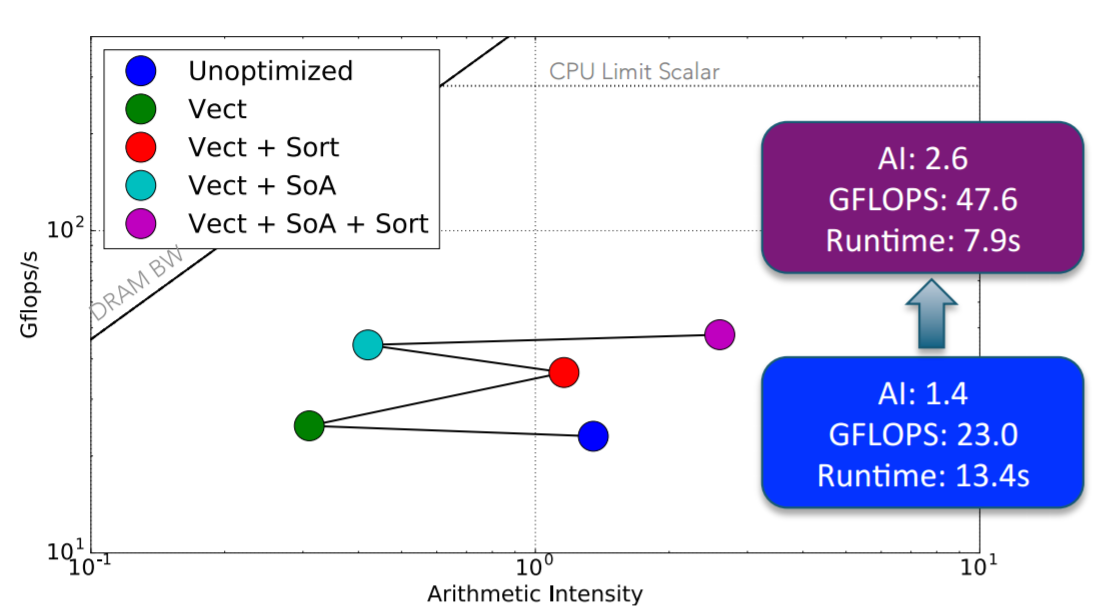
Figure 5: Optimization to vectorization and memory layout using classical roofline on Intel Xeon Phi (Image courtesy NERSC)
Of course, the roofline model can also be used to improve performance on an Intel Xeon processor as well. As shown below, a roughly 2x performance increase was also achieved on one of the Cori Intel Xeon processor nodes. Thus the benefits of using the roofline model apply to both processor families.
The NERSC team provided other examples such as the PICSAR code, which is a high-performance Fortran/Python Particle-In-Cell library. The NERSC team was able to “achieve speedups of 3.1 for order 1 and 4.6 for order 3 interpolation shape factors on Intel Xeon processors code name Knights Landing (KNL) configured in SNC4 quadrant flat mode. Performance is similar between a node of Cori phase 1 and KNL at order 1 and better on KNL by a factor 1.6 at order 3 with the considered test case (homogeneous thermal plasma).” In short, using the roofline model in Intel Advisor helped a lot.
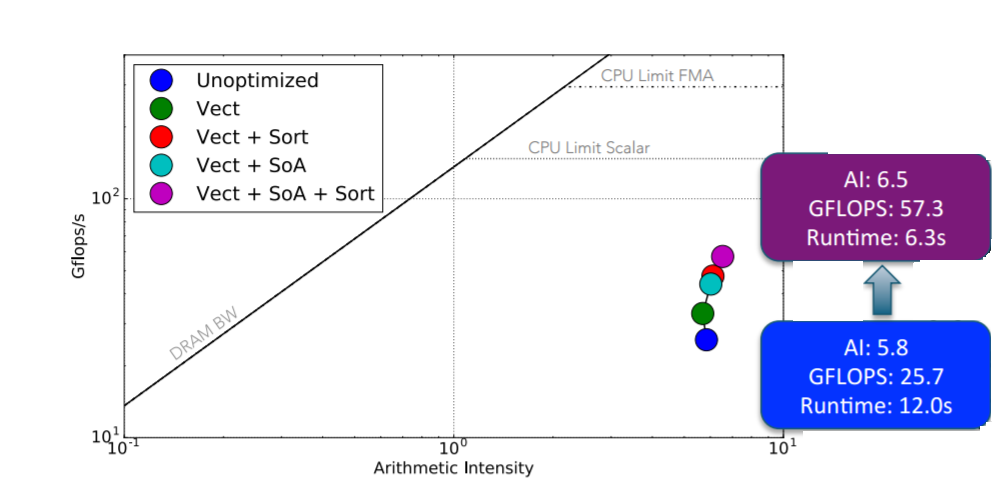
Figure 6: Optimization to vectorization and memory layout using classical roofline on Intel Xeon (Image courtesy NERSC)
Summary
The NERSC team found that the roofline analysis helps to optimize applications to attain high performance on both Intel Xeon and Intel Xeon Phi processors. The results to date show that optimized codes generally run faster on Intel Xeon Phi, which may be important to the design of future exascale supercomputers. The NERSC co-design work with Intel on Intel Advisor provides an all-in-one tool for cache-aware roofline analysis that automates the work, helps find hotspots, and analyzes the effect of optimizations. NERSC has provided a Python library for post-processing Advisor data at https://github.com/tkoskela/pyAdvisor.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. He was also the editor of Parallel Programming with OpenACC. Rob can be reached at info@techenablement.com.
This article was produced as part of Intel’s HPC editorial program, with the goal of highlighting cutting-edge science, research and innovation driven by the HPC community through advanced technology. The publisher of the content has final editing rights and determines what articles are published.

The Stepping Stones In America To Exascale And Beyond
To a certain extent, all of the major HPC centers in the world live in the future. Before a teraflops, petaflops, or exaflops supercomputer is even operational, a new team at the center is hard at work defining what the workloads five years from now might look like so they …

Using Bayesian Inference To Reverse Engineer Decades Of HPC
A collaboration including the University of Oxford, University of British Columbia, Intel, New York University, CERN, and the National Energy Research Scientific Computing Center is working to make it practical to incorporate of Bayesian inference into scientific simulators. The project is called Etalumis, which is the word “simulate” spelled backwards, and …

Python Delivers Big On Complex Unlabeled Data
A collaboration of researchers from the University of California Davis, the National Energy Research Scientific Computing Center, and Intel are working together on the DisCo project to extract insight from complex unlabeled data. DisCo is short for the Discovery of Coherent Structures, and it discovers the inherent structures in unlabeled …
“optimized codes generally run faster on Intel Xeon Phi” than?
Than unpotimised codes, of course!